Wir sind unabhängig, neutral und finanzieren uns teilweise über Werbung und Partnerprovisionen.
Danke wenn du uns unterstützt. Weitere Infos zum Bedanken findest Du hier.
Diese Seite verwendet hierzu Cookies & Tracking-Cookies, weitere Informationen findest du hier. Wenn du diese Seite weiterhin besuchst, erklärst du dich damit einverstanden.
Diese seite ist neutral und unabhängig. Die Finanzierung erfolgt teilweise über Werbung und Partnerprovisionen.
Danke wenn Du mich unterstützt.
Diese Seite verwendet Cookies & Tracking-Cookies, weitere Informationen findest Du hier. Wenn du diese Seite weiterhin besuchst, erklärst du dich damit einverstanden.
Handbuch:
Linux optimal installieren
© www.ctaas.de # 2026-07-02
Linux einfach installieren - wie man ein kleines, stabiles & sicheres System aufsetzt. Deutsche/German Debian/Ubuntu Anleitung:
| Nr. |
Admin Handbuch Inhalt: |
| 1 |
Vorüberlegungen |
| 2 |
Grundsystem Empfehlungen (DVD-Links) |
| 3 |
root bzw. sudo Passwort festlegen |
| 4 |
Paketquellen aktualisieren/Updates installieren | Repository hinzufügen/löschen |
| 5 |
Linux Desktopumgebungen im Vergleich |
| 6 |
Autologon |
| 7 |
Netzwerkeinstellungen anpassen (network/interfaces bzw. netplan) |
| 8 |
hosts-Datei/WINS/NetBIOS Hostnamen auflösen (winbind) (bind9) |
| 9 |
Netzwerk browsing (durchsuchen) aktivieren |
| 10 |
häufig empfohlene Zusatzprogramme |
| 11 |
Paketquellen (CDs/DVDs) entfernen |
| 12 |
Terminal Consolen Font ändern & Tipps zur Console |
| 13 |
Grafische Fernsteuerung/Fernwartung der Server |
| 14 |
vsftpd (FTP-Server/FTPS-Server) sicher einrichten |
| 15 |
OpenSSH-Server (SFTP-Server/SSH Secure Shell) einrichten |
| 16 |
Samba Dateiserver mit Papierkorb in Netzlaufwerken einrichten |
| 17 |
Apache2 Webserver mit PHP einrichten |
| 18 |
MySQL Datenbank-Server (mit PHP und Apache Anbindung) installieren |
| 19 |
transparenter Bildschirmschoner |
| 20 |
GRUB 2 (Consolenauflösung und Splash-Screen) anpassen |
| 21 |
Ubuntu auf eine neue Version aktualisieren (Upgrade) |
| 22 |
BitDefender Virenscanner von einem Live-System aus nutzen (Ubuntu) |
| 23 |
Linux sichern (MBR, Partitionstabellen, Partitionen ...) |
| 24 |
GRUB 2 von einem Live System aus reparieren (Linux MBR reparieren) |
| 25 |
VMWare ESXi Problemlösung: horizontal gespiegelte Darstellung |
| 26 |
VirtualBox VMs per Batch starten und beenden |
| 27 |
Datenrettung gelöschte Bilder/Fotos wiederherstellen (recoverjpeg) |
| 28 |
Datenrettung mit photorec |
| 29 |
Datenrettung mit foremost |
| 30 |
Datenrettung/Undelete mit tsk_recover |
| 31 |
Paketquellen/Repositories hinzufügen und verwalten |
| 32 |
doppelte Dateien löschen: FSlint (file system utilities) |
| 33 |
doppelte Dateien löschen: duff (DUplicate File Finder) |
| 34 |
doppelte Dateien löschen: rdfind (redundant data find) |
| 35 |
.eml Dateien entpacken |
| 36 |
Foto Dateinamen vereinheitlichen/mit Datum versehen und sortieren (exiftool) |
| 37 |
Bilder konvertieren: bmp in png (mit ImageMagick) |
| 38 |
Bilder konvertieren: jpg/jpeg & png in webp (mit cwebp) |
| 39 |
Bilder konvertieren: gif Bilder & Animationen in webp (mit cwebp) |
| 40 |
Bilder konvertieren: avif, heic, png, jpg umwandeln (libheif/heif-convert) |
| 41 |
guetzli: png in jpg konvertieren (optimiert für Webseiten) |
| 42 |
zopfli: png, htm, html, php, css, js, xml ... Dateien optimal packen |
| 43 |
advpng: png ... Dateien optimal packen (alternative Variante) |
| 44 |
brotli: htm, html, php, css, js, xml ... Dateien optimal packen |
| 45 |
lepton: jpg/jpeg verlustfrei im lep Format packen (zum archivieren) |
| 46 |
flif: png ... Dateien optimal packen (Free Lossless Image Format) |
| 47 |
Bildschirmauflösung einer Hyper-V VM ändern |
| 48 |
UTC Zeitzone anpassen für Ubuntu mit systemd (pool.ntp.org) |
| 49 |
Remote Desktop unter Ubuntu/Linux aktivieren |
| 50 |
PDF in PNG umwandeln (z. B. für Covers) |
| 51 |
cjxl: png, jpeg optimal in jxl (JPEG XL) konvertieren. |
| 52 |
PNG Bilder/Fotos mit OptiPNG optimal packen |
|
Linux Kurzreferenz: Wichtige Linux Shell-Befehle und Programme (Sortiert von A-Z)
|
|
addgroup,
adduser,
alias,
blkid (block device attributes),
cat (concatenate),
cd (change directory),
chattr (change file attributes),
chmod (change file mode bits),
chown (change owner),
chpasswd (change password),
cp (copy),
cut (ausschneiden),
date/hwclock/cal/ntpdate (Zeitangaben ausgeben und setzen),
dd (disk dump),
debconf-show,
delgroup,
deluser,
df (disk free),
diff (difference),
dosfsck,
dpkg-reconfigure,
du (disk usage),
e2fsck (ext filesystem check, chkdsk),
echo,
env (environment),
$? (errorlevel),
exit & logout,
fdisk,
file,
find,
for do done (for Schleife) ,
free,
fsarchiver (filesystem archiver),
fsck (file system check),
grep,
groups (Gruppen),
htop,
gzip,
hdparm,
head,
hostname,
hostnamectl,
id (identification),
if,
iotop,
ip,
journalctl,
kill,
killall,
ln (link),
ls (list),
lsattr (list file attributes),
lsb_release (Linux Standard Base Specification),
lsblk (list block devices),
lshw (list hardware),
mail,
more,
mount,
mkdir (make dir),
mkfs (make filesystem),
mv (move),
nmap,
nohup (no hangup),
NVMe (NVM Express),
partclone ,
passwd (password),
ps (processes),
pv (monitor the progress of a data throuh a pipe),
pwd (print working directory),
qrencode,
reboot,
rm (remove),
rmdir (remove directory),
sed (stream editor),
setterm,
shred,
shutdown,
sleep,
sort,
stat (display file system status),
su (superuser),
sudo (superuser do),
tail,
tar,
tee,
timedatectl (control the system time and date),
top,
touch (change file timestamps),
tune2fs,
uname,
xset
|
Die nachfolgende Dokumentation ist für Ubuntu und Debian geeignet.
Erklärt wird in wenigen einfachen Schritten wie man eine optimale Linux Umgebung installiert.
Diese Anleitung ist für Linux Systeme mit Desktop sowie auch für reine Server ohne grafische XServer nutzbar.
Wer noch nicht weiß welche Linux Desktop-Umgebung optimal ist, der findet hier noch einen Ressourcen-Vergleich.
In den nachfolgenden Schritten werden dann verschiedenste wichtige Programme, Tipps sowie einige Server Dienste vorgestellt.
1. Vorüberlegungen für Desktops:
Verglichen wurden insbesondere Desktops die:
- stabil & ressourcenschonend arbeiten,
- möglichst auf 3D-Effekte & Bling-Bling verzichten,
- schnelles und flüssiges Arbeiten ermöglichen,
- in VMs gut laufen und
- regelmäßig gut gepflegt werden (Sicherheit).
Des Weiteren sollten heutzutage gängige Desktopfunktionen bereit stehen:
- ein Taskmanager (zum überwachen von Ressourcen und Netzwerk-Traffic),
- ein Terminal (mit veränderbaren Fonts),
- ein Dateimanager mit Netzwerkfunktionalität (browse Netzwerk),
- ein grafischer Editor zum bequemen Editieren von Konfigurationsfiles,
- ein Webbrowser zum Surfen im Internet (z. B. mit Firefox),
- Tools für grundlegende Systemeinstellungen wie z. B. Font-Einstellungen, statische Netzwerkadressenvergabe oder WLAN-Konfiguration,
- Benachrichtigungen des Users bei Updates (sofern kein Autoupdate aktiviert wurde).
Alle weiteren Anwendungen aus dem Office-, Grafik-, Musik-, Server-Bereich usw. wurden nicht berücksichtigt.
Der Anwender muss sich die entsprechenden Anwendungen je nach Verwendungszweck selbst nachinstallieren.
Es geht hier also darum ein möglichst kleines, schlankes und stabiles Grundsystem zu erhalten auf das man dann aufbauen kann.
2. Ein Grundsystem ist Voraussetzung:
Will man ein möglichst aufgeräumtes System ohne jeglichen Schnickschnack,
so sollte man anfangs nur eine Server Version ohne GUI installieren. Voraussetzung ist am besten eine neue Linux Installation.
Man installiert zuerst ein Standard Server Setup der gewünschten Distribution (Ubuntu oder Debian).
Unterschiedliche Setup-Medien findet man hier:
Für Ubuntu:
Die Server-DVD ist für ein kompaktes Ubuntu-System eine Voraussetzung (empfohlen).
Die Ubuntu-Desktop-DVD
bzw. die Xubuntu-Desktop-DVD starten jeweils ein Live-System (dieses ist für Tests, Reparaturzwecke, sowie zur Installation geeignet).
Für Debian:
Das Stable-Livesystem ist für Tests, zum Installieren, sowie für Reparaturen geeignet.
Hier findet man das komplette Debian (geeignet für alle Installationsarten - ebenso empfohlen).
In der Regel reicht hier ein Download der ersten CD/DVD aus, denn diese enthält alle Dateien für ein Standard-Debian-System.
Alle weiteren Medien benötigt man nur, wenn man weitere Pakete für eine komplette offline Installation benötigt.
Ältere Versionen kann man hier im Debian Archiv herunterladen.
Hinweis:
Ein Setup von einer Desktop-Live-DVD, installiert immer einen kompletten Desktop, mit allen Anwendungen.
Daher wird ein Setup von einer Desktop-Live-DVD nicht empfohlen.
3a. unter Ubuntu - das root Passwort setzen (optional):
Sofern dies noch nicht bei der Installation geschehen ist, sollte man jetzt noch das root-User-Passwort setzen:
sudo passwd root
Im Terminal muss man nun das neue Passwort vergeben.
3b. unter Debian - dem Standard-Benutzer sudo Rechte zuweisen (optional):
Will man dem normalen Standard Debian User sudo Rechte zuweisen so sind folgende Schritte durchzuführen:
Anmelden als root entweder über ein entsprechendes root-Terminal oder mittels:
su
Achtung: Es wird hierbei das root User Passwort nicht das Passwort vom angemeldeten User abgefragt.
Danach sollte man das sudo package installieren (sofern noch nicht vorhanden):
apt-get install sudo
Danach kann man dem User die sudo Rechte wie folgt zuweisen:
gpasswd -a UserName sudo
Die Änderung wird erst nach einer Neuanmeldung (An-/Abmeldung am System) übernommen, am schnellsten:
reboot
Sicherheitshinweis: Die sudo Rechte erweitern die Rechte des Users!
Sicherheitstechnisch sollte man abwägen was wichtiger ist.
Mehr Bequemlichkeit, dann aktiviert sudo,
mehr Sicherheit dann verwendet nur root mit einem starken Passwort zur Einrichtung.
Den User wieder aus der sudo-Gruppe entfernen:
gpasswd -d UserName sudo
4. Paketquellen einlesen/aktualisieren & Updates installieren (empfohlen):
Bevor man ans weitere installieren geht, sollte man die Paketquellen neu einlesen (auf Updates prüfen)
und diese Updates ggf. erst einspielen (upgrade):
apt-get update # Paketquellen aktualisieren (vor jedem Update notwendig).
apt-get list --upgradeable # Alle verfügbaren Update-Pakete anzeigen.
apt-get --simulate dist-upgrade # Änderungen am System werden nur simuliert.
apt-get upgrade # Bestehende Programm-Pakete aktualisieren. Es werden keine neuen Programm Versionen (upgrades) installiert. Pakete die neue Abhängigkeiten erfordern werden hier nicht auf eine neue Version aktualisiert.
apt-get --with-new-pkgs upgrade # Aktualisiert die Pakete; wenn Abhängigkeiten es verlangen, dürfen dabei zusätzliche neue Pakete installiert werden. Dies entspricht sozusagen einem 'dist-upgrade' für dieses Update. Das System wird danach nicht bereinigt.
apt-get install --reinstall Paketname # Installiert ein Paket nochmal neu (kann bei Fehlern helfen).
apt-get dist-upgrade # Auch neue Programmpakete/Programm Versionen installieren (empfohlen).
apt full-upgrade # Auch neue Programmpakete/Programm Versionen installieren (moderne Syntax - entspricht 'dist-upgrade' | empfohlen).
apt-get autoremove # Alte nicht mehr benötigte Pakete wieder löschen. Will man auch alte Kernel-Versionen löschen, so muss man ggf. zuvor den grub-Bootloader aktualisieren [update-grub].
apt-get autoclean # Heruntergeladene aber nicht mehr gepflegte Pakete löschen.
Erst danach sollte man mit der Installation des eigentlichen Desktops beginnen.
Sauberes entfernen von nicht mehr benötigten Paketen:
apt-get remove Paketname # Deinstalliert das angegebene Paket.
apt-get autoremove Paketname # Deinstalliert das angegebene Paket einschließlich aller nicht mehr benötiger Abhängigkeiten.
apt-get purge Paketname # Deinstalliert das angegebene Paket und entfernt alle dazugehörigen Konfigurationsdateien,
notwendig ist dies z. B. beim Wechsel von PHP5 auf PHP7 oder bei einem Desktopwechsel - ein Parallelbetrieb ist hier meist nicht vorgesehen.
Um Problemen aus dem Weg zu gehen sollte man bei derartigen Paketen zuerst das alte Paket mittels purge entfernen und erst dann das neue Paket installieren.
apt-cache search Suchbegriff | more # Sucht nach möglichen Paketen. Hilfreich, wenn man nicht genau weiß welches man nehmen soll.
4.1. Repository hinzufügen/löschen:
add-apt-repository universe # Aktiviert das Ubuntu-Repository „universe“ mit Community-Paketen
add-apt-repository ppa:mozillateam/ppa # Beispiel-PPA z. B. für Firefox/Thunderbird-nahe Pakete
add-apt-repository --remove universe # Entfernt das Repository „universe“ wieder aus den Paketquellen. Installierte Pakete aus dieser Paketquelle bleiben installiert, werden jedoch zukünftig nicht mehr aktualisiert.
Das kann später u. a. bei Abhängigkeitsänderungen zu Problemen führen. Programme, die aus dieser Paketquelle installiert wurden, können normal entfernt werden auch wenn das Repository entfernt wurde.
Folgende Repositorys sind möglich:
universe # Community-Pakete, viele Tools/Utilities, extra Software
restricted # Treiber/Firmware-nahe Pakete, hardwarebezogen
multiverse # Pakete mit Lizenz-/Rechts-Einschränkungen
partner # Canonical-Partner-Software, z. B. proprietäre Zusatzpakete
Personal Package Archive (PPA) = fremde Paket-Quell-Repositorys eines Drittanbieters einbinden:
Achtung:
Füge nur PPA hinzu, denen du vertraust. Fremde Abhängigkeiten können das System stark beeinträchtigen und Updates ggf. erschweren.
PPA können Pakete aus anderen Abhängigkeiten ersetzen. Im Zweifel sollte man vor größeren Änderungen ein Backup/Snapshot erstellen.
ppa:launchpad-username/ppa-name # Drittanbieter-Quellen, projektspezifische Zusatzsoftware
ppa:mozillateam/ppa # Beispiel-PPA für Firefox/Thunderbird-nahe Pakete
ppa:graphics-drivers/ppa # Beispiel-PPA für aktuellere NVIDIA-Treiber
5. Fenstermanager-Installation:
Nun kann man sich für einen Fenstermanager (eine Desktopumgebung) entscheiden.
Vorstellen möchte ich hier folgende:
| Xfce |
MATE Desktop Environment |
Gnome |
LXDE |
LXQt |
IceWM |
Cinnamon |
(Ubuntu) Unity |
KDE Plasma |
| Empfehlung: 100 % |
Empfehlung: 90 % |
Empfehlung: 80 % |
Empfehlung: 70 % |
z. Z. nicht Empfohlen |
nicht Empfohlen |
nur bedingt Empfohlen |
Entwicklung eingestellt |
nicht Empfohlen |

- ist über die offiziellen Paketquellen verfügbar,
- hat einen klassischen Look,
- ist schnell und ressourcenschonend,
- sowie sehr stabil und zukunftssicher, da es sehr ausgereift ist und regelmäßig weiter entwickelt wird,
- die aktuelle Version heißt derzeit Xfce4,
- Xfce wird für Server, Desktop und VM empfohlen,
- verwendet das GTK+-Toolkit.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert den Xfce4 Desktop bis Ubuntu 18.10:
apt-get install xfce4
Ab Ubuntu 19.04
verändertes xfce4 package (neue Empfehlung zur Installation):
apt-get install --no-install-recommends xfce4 xorg xserver-xorg-video-all elementary-xfce-icon-theme
Ergänzende Parametererklärungen für ein kompaktes Setup findet ihr hier.
ergänzend ab Ubuntu 20.10:
deutsches Sprachpaket nachinstallieren:
Zuerst die Sprach-Pakete herunterladen:
apt install language-pack-gnome-de
Dies aktiviert nach einem Neustart das deutsche Tastaturlayout.
Danach kann man wie folgt die Sprache im System komplett auf Deutsch umstellen:
update-locale LANG=de_DE.UTF-8 && reboot
System-Sprache auf Deutsch umstellen Alternative:
dpkg-reconfigure locales && reboot
hier dann [*] de_DE.UTF-8 UTF-8 und de_DE.UTF-8 auswählen. Auch hier ist dann noch ein Systemneustart notwendig.
Beachtet dass beim nachinstallieren von anderen Programmen wie Office, Firefox usw. ggf. weitere entsprechende Sprach-Pakete für diese zusätzlichen Programme notwendig sein können.
Folgendes installiert die für Ubuntu angepasste Version (weniger empfohlen):
apt-get install xubuntu-desktop
Folgendes installiert die angepasste Ubuntu Studio Version (die Multimedia Version zum bearbeiten von Audio-, Video- und Bild-Dateien) (weniger empfohlen):
apt-get install ubuntustudio-desktop
Weitere Zusätze (wie z. B. CD/DVD-Brennprogramm) installiert man über:
apt-get install xfce4-goodies
Sollten Icons fehlen, so installiert man einfach:
apt-get install gnome-icon-theme
bzw.:
apt-get install gnome-icon-theme-full
bzw.:
apt-get install xubuntu-icon-theme
Tastenkürzel:
Windows+e Editor,
Windows+f Explorer,
Windows+m E-Mail,
Windows+t Terminal,
Windows+w Webbrowser
starten.
|

- ist ein Fork von Gnome 2,
- hat einen klassischer Look,
- ist relativ neu, wird aber stetig weiter entwickelt,
- ab Ubuntu 14.10 und Debian 8
ist MATE über die offiziellen Paketquellen verfügbar,
- wird für Desktops empfohlen.
- verwendet das GTK+-Toolkit.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert den MATE-Desktop mit allen zusätzlichen Komponenten (empfohlen):
apt-get install xorg mate-desktop-environment-extras
Folgendes installiert den MATE Desktop:
apt-get install xorg mate-desktop-environment
Folgendes installiert nur den minimalen MATE Desktop ohne jegliche Extras (mit Brisk-Menü):
apt-get install xorg mate-desktop-environment-core mate-applet-brisk-menu
Folgendes installiert ab Ubuntu 15.04 den für Ubuntu angepassten kompletten MATE Desktop (weniger empfohlen):
apt-get install ubuntu-mate-desktop
Die Benachrichtigungsleiste nachinstallieren (optional):
apt-get install mate-notification-daemon
Unter Ubuntu sollte man diesen Font nachinstallieren, um die Terminaldarstellung zu verbessern (optional):
apt-get install ttf-ubuntu-font-family |
] unter Debian 8. Ansicht vergrößern über klick oder zoom.")
- moderner & klassischer Look,
- wird ständig weiter entwickelt,
- ist stabil und zukunftssicher,
- für leistungsstärkere Desktops empfohlen,
- verwendet das GTK+-Toolkit.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert den Gnome 3 Desktop:
apt-get install xorg gnome-core
gnome-session-flashback
Parameterbeschreibung:
gnome-core - installiert den Gnome 3 Desktop, dieser benötigt möglichst einen Grafiktreiber der Video und 3D beschleunigt.
gnome-session-flashback installiert zusätzlich - GNOME Flashback (Metacity) - einen sparsamen 2D Desktop.
Bei der Anmeldung kann man dann über das Zahnradicon auswählen welcher Desktop gestartet werden soll.
Der zuletzt gewählte Eintrag wird automatisch als Default-Desktop eingestellt. |

- klassischer Look,
- wird gut gepflegt und ist daher stabil und zukunftssicher,
- für Server und Desktops gleichermaßen geeignet,
- für VMs sehr empfohlen da sehr ressourcenschonend,
- verwendet das GTK+-Toolkit.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert den LXDE Desktop (empfohlen):
apt-get install xorg lxde-core
Folgendes installiert eine für Ubuntu angepasste LXDE Version (weniger empfohlen):
apt-get install xorg lubuntu-core
Das Aussehen/Thema lässt sich anpassen über:
apt-get install lxappearance
Bei einer Installation unter VirtualBox (als VM) muss man noch folgendes Installieren:
apt-get install build-essential dkms
|

- klassischer Look,
- relativ neu, wird erst entwickelt (noch nicht 100 % stable),
- daher zur Zeit keine Empfehlung für Server, Desktop oder VM,
- LXQt ist noch nicht in den offiziellen Quellen von Ubuntu und Debian enthalten,
- ist eine auf Qt basierende LXDE Umgebung.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert ab Ubuntu 18.04 den LXQT Desktop:
apt install lxqt-core openbox
Installationsanleitung für Ubuntu:
1. folgende Paketquelle hinzufügen (nur bei alten Versionen):
add-apt-repository ppa:lubuntu-dev/lubuntu-daily
2. Alle Paketquellen neu einlesen:
apt-get update
3. LXQt installieren:
apt-get install lxqt-metapackage openbox
Die Installation unter Debian wird derzeit nicht empfohlen. Derzeit (Stand: 2015-03-05) ist hier alles noch eine Baustelle.
Sollte man es doch versuchen, so sollte man zuerst den Befehl [add-apt-repository] nachinstallieren, sodass man Paketquellen hinzuzufügen kann:
apt-get install software-properties-common
Anschließend sollte man nach einer Installationsanleitung googeln.
|

- alter Windows Look,
- alt, aber sehr ressourcensparend,
- für Desktops eher weniger empfohlen, da doch sehr schlicht.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert den IceWM Desktop:
apt-get install xorg icewm
optionale Themes (z. B. SilverXP) installieren:
apt-get install icewm-themes |

- ist ab Ubuntu 14.10 und Debian 8 über die Standard Paketquellen verfügbar,
- ist ein Fork von GNOME bzw. der GNOME Shell,
- benötigt einen Grafiktreiber der Video und 3D beschleunigt,
- als fall-back wird ein Software-Rendering-Modus verwendet, der jedoch eine erhöhte CPU-Auslastung bewirkt,
- daher eine sehr hohe CPU Last in VMs,
- für leistungsstarke Desktops durchaus empfohlen,
- wird hauptsächlich in Linux Mint eingesetzt.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert den Cinnamon Desktop:
apt-get install xorg cinnamon-core
Folgendes installiert Cinnamon mit allen zusätzlichen Anwendungen:
apt-get install xorg cinnamon-desktop-environment |

- die Entwicklung wurde ab Ubuntu 17.10 eingestellt (für Ubuntu wird wieder Gnome verwendet),
- Unity wurde speziell für kleinere Displays wie z. B. Netbooks entwickelt,
- Die Arbeitsumgebung Unity wird hauptsächlich unter Ubuntu eingesetzt,
- des Weiteren werden die Standard GTK+ Programme verwendet,
- Ab Unity 8 wird das Qt-Framework verwendet,
- die linke Schnellstart-
leiste ist clever und auch gut über eine Tastensteuerung zu erreichen,
- auch die Suchfunktion über die [Windows-Fahnentaste] ist an sich gut gelöst,
- nur leider trüben der enorme Ressourcenbedarf, die teileweise übertriebenen Anpassungen mit Themes, sowie die integrierte Websuche (über verschiedenste Portale und die daraus resultierenden Datenschutzprobleme) das positive Bild,
- Unity ist derzeit unter Debian nicht oder nur schwer installierbar.
Folgendes installiert unter Ubuntu den Ubuntu-Desktop mit Unity (weniger empfohlen):
apt-get install ubuntu-desktop
Folgendes installiert die mit Lernprogrammen erweiterte Schulversion Edubuntu (weniger empfohlen):
apt-get install edubuntu-desktop
Tastenkürzel:
Strg+Alt+T = neues Terminal.
SUPER (Windows-Taste)+A = Suche nach Anwendungen.
SUPER (Windows-Taste)+F = Suche nach Dateien (Files).
|

KDE Plasma 4:
- wird ständig weiter entwickelt,
- ist relativ verspielt,
- verwendet die Qt-Bibliothek.
'universe' Paketquelle hinzufügen (Optional/ab Ubuntu 18.04):
add-apt-repository universe
Folgendes installiert den KDE Plasma Desktop:
apt-get install xorg kde-plasma-deskop
Sprachpaket für Ubuntu:
apt-get install language-pack-kde-de
Sprachpaket für Debian:
apt-get install kde-l10n-de
weitere Metapakete:
apt-get install kde-standard
apt-get install kde-full
Folgendes installiert den speziell für Ubuntu angepassten Desktop (weniger empfohlen):
apt-get install kubuntu-desktop

Neu:
KDE Plasma 5:
- hat einen modernen flat Look,
- und fast ein einheitliches Design,
- trotzdem ist es noch sehr verspielt,
- befindet sich z. Z. noch in Entwicklung,
- verwendet das Qt 5 und KDE Framework 5,
- Kubuntu 15.04 verwendet KDE Plasma 5 erstmals als Standard Desktop.
KDE-Plasma 5 Installationsanleitung
für Ubuntu 14.10:
apt-add-repository ppa:kubuntu-ppa/next
apt-get update
apt-get dist-upgrade
apt-get install
kubuntu-plasma5-desktop
plasma-workspace-wallpapers
KDE-Plasma Installationsanleitung
ab Ubuntu 15.04:
apt-get install kubuntu-desktop kde-l10n-de
|
|
circa Ressourcenverbrauch*: |
Xfce:
Download: 92 MB
HD Speicher: +336 MB
HD insgesamt: 1,7 GB
laufende Tasks: 110
belegter RAM: 135 MB
Die Angaben beziehen sich auf das Xfce Grundsystem. |
Mate Desktop Environment:
Download: 125 MB
HD Speicher: +423 MB
HD insgesamt: 1,8 GB
laufende Tasks: 103
belegter RAM: 135 MB |
GNOME Flashback (Metacity):
Download: 309 MB
HD Speicher: +1180 MB
HD insgesamt: 3 GB
laufende Tasks: 149
belegter RAM: 320 MB |
LXDE:
Download: 78 MB
HD Speicher: +288 MB
HD insgesamt: 1,6 GB
laufende Tasks: 107
belegter RAM: 110 MB |
LXQt:
Download: 154 MB
HD Speicher: +486 MB
HD insgesamt: 2,1 GB
laufende Tasks: 112
belegter RAM: 150 MB |
IceWM:
Download: 40 MB
HD Speicher: +136 MB
HD insgesamt: 1,5 GB
laufende Tasks: 87
belegter RAM: 75 MB |
Cinnamon:
Download: 185 MB
HD Speicher: +773 MB
HD insgesamt: 2,7 GB
laufende Tasks: 130
belegter RAM: 260 MB |
Ubuntu (Unity):
Download: 625 MB
HD Speicher: +2306 MB
HD insgesamt: 4,8 GB
laufende Tasks: 155
belegter RAM: 500 MB
Die Angaben beziehen sich auf Ubuntu 15.04. |
KDE-Plasma 4:
Download: 209 MB
HD Speicher: +707 MB
HD insgesamt: 2,9 GB
laufende Tasks: 115
belegter RAM: 360 MB
Die Angaben beziehen sich auf KDE-Plasma 4. |
Hinweise:
Eine parallele Installation von verschiedenen Desktopumgebungen kann zu unerwünschten Effekten führen.
Denn Einstellungen wie Thema, Schriftbild, Panel, Icons usw. können andere vorhandene Desktopumgebungen negativ beeinflussen. Man sollte daher möglichst nur einen Fenstermanager (nur eine Desktopumgebung) installieren.
Um alternative Desktopumgebungen zu testen, kann man auch CD/DVD/USB-Live-Systeme, oder getrennte VM Installationen verwenden.
Das System sollte jetzt in den Grundzügen einsatzbereit sein.
In den nachfolgenden Schritten werden verschiedenste wichtige Programme, Tipps sowie einige Server Dienste vorgestellt.
Beachtet hier nur die Punkte die Ihr benötigt.
6. Die grafische Benutzeroberfläche starten & Autologon:
Hier bitte nur eine Option zum Autologin verwenden.
Die einfache Consolenvariante (links) empfiehlt sich für Einzelplatzsysteme und Server - die Variante mit dem Displaymanager (rechts) sollte man verwenden, wenn man einen Anmeldescreen für mehrere Benutzer benötigt.
| TTY Console Autologin: |
Grafisches Login mit dem Displaymanager: |
Verwendet man 'getty' bzw. 'agetty' für das Autologin auf der Console TTY1, dann kann man sich auf dieser Console nicht mehr abmelden.
Möchte man das System später durch ein exit wieder sperren, so muss man stattdessen 'rungetty' verwenden:
apt-get install rungetty
Tipp vorab: Sollte das System nach dem Neustart in der Console hängen bleiben (das passiert nur bei Falscheingaben), dann meldet man sich einfach über eine andere Console an.
Z. B. über Strg + Alt + F2 an. Hier kann man sich dann normal anmelden und Fehleingaben korrigieren oder auch alles wieder rückgängig machen.
Neu für systemd-Versionen:
Unter Debian (ab Debian 8, 9) bzw.
unter Ubuntu (ab Ubuntu 15.04, 15.10, 16.04, 16.10, 17.04, 17.10, 18.04, 18.10)
muss man folgende Schritte durchführen:
Zuerst folgendes Verzeichnis anlegen:
mkdir -pv /etc/systemd/system/getty@tty1.service.d/
Dann eine neue Datei (*.conf) mit folgendem Inhalt anlegen:
nano /etc/systemd/system/getty@tty1.service.d/autologin.conf
# Hier folgende Zeilen hinzufügen:
[Service]
ExecStart=
ExecStart=-/sbin/agetty --autologin Benutzername tty1
# alternativ mit rungetty:
# ExecStart=-/sbin/rungetty --autologin Benutzername tty1
# Wichtig: Die leere 'ExecStart=' Zeile muss man mit eingeben.
Unter Debian ( init-Version bis Debian 7) muss man folgende Datei editieren:
nano /etc/inittab
# Hier die vorhandene Zeile:
1:2345:respawn:/sbin/getty -8 38400 tty1
# so ändern und speichern:
1:2345:respawn:/sbin/rungetty --autologin Benutzername tty1
Unter Ubuntu ( init-Versionen bis Ubuntu 14.10) muss man folgende Datei editieren:
nano /etc/init/tty1.conf
# Hier die vorhandene Zeile:
exec /sbin/getty -8 38400 tty1
# so ändern und speichern:
exec /sbin/rungetty --autologin Benutzername tty1
Die Desktopumgebung kann man nun wie folgt starten:
startx
Will man anschließend von der Console aus direkt in die grafische Oberfläche starten, so legt man im Homeverzeichnis des Benutzers eine neue Datei an:
nano ~/.bash_profile
# Hier fügt man folgenden Befehl ein:
startx &
# Tipp: Hier an dieser Stelle kann man natürlich auch
# beliebige andere Befehle oder Scripte starten (Linux Autostart).
Dann wird nach dem Autologin anschließend direkt der XServer gestartet, ohne dass man einen Displaymanager benötigt.
Wichtig: Will man später auch über SSH und Putty zugreifen, so sollte man ein [ &] anhängen um den XServer im Hintergrund zu starten.
Denn hängt man das [ &] nicht an, so würde in Putty gleich nach dem Login versuchen den XServer zu starten und dann die Console blockieren. |
Möchte man dagegen direkt in die Desktopumgebung (GUI) starten, so kann man einen Displaymanager verwenden.
Der Displaymanager stellt einen Anmeldbildschirm für verschiedene User bereit.
Empfehlen würde ich folgenden:
apt-get install lightdm lightdm-gtk-greeter
Das Startverhalten (ob z. B. direkt das grafische Login gestartet werden soll) kann man jederzeit wie folgt anpassen:
nano /etc/default/grub
# Hier den vorhandenen Eintrag:
GRUB_CMDLINE_LINUX_DEFAULT=""
# ändern in:
GRUB_CMDLINE_LINUX_DEFAULT="text"
# Parameterbeschreibung:
# Ein leerer Eintrag "" bedeutet, es wird direkt das grafische Login gestartet.
# Der Eintrag "text" bedeutet, es wird nach dem Login das Terminal (die Console) gestartet.
Anschließend muss man noch die grub Einstellungen aktualisieren:
update-grub
Die Änderung wird erst nach einem Neustart übernommen:
reboot
In dem Beispiel oben wird also nicht mehr die GUI - sondern nur noch die Eingabeaufforderung (also das Terminal) gestartet.
LightDM Autologon:
Will das ein bestimmter User am LightDM Displaymanager automatisch anmeldet wird, so muss man nur in der Datei:
mousepad /etc/lightdm/lightdm.conf
# Folgendes hinzufügen:
[SeatDefaults]
autologin-user=Username
# autologin-user-timeout=30
# Der Parameter [autologin-user-timeout=xx] ist optional.
# Angegeben wird hier die Zeitdauer (in Sekunden) die gewartet wird bevor das Autologin stattfindet.
# Meldet sich während dieser Wartezeit ein anderer User an, so wird das Autologin unterbrochen.
# Hat man den Parameter nicht angegeben, so wird der User sofort angemeldet.
Nach der Abmeldung des automatisch angemeldeten Users kommt man wieder in die grafische Login-Maske des Displaymanagers, hier kann sich dann auch ein anderer User anmelden.
Gnome 3 Autologon (ähnlich wie bei LightDM):
mouspad /etc/gdm3/daemon.conf
# Hier dann folgende Werte aktivieren & ändern:
[daemon]
# Enabling automatic login
AutomaticLoginEnable=true
AutomaticLogin=Username
# Alternativ kann das verzögerte Login über die vorhandenen TimedLogin-Einträge vorgenommen werden.
# TimedLoginEnable=true
# TimedLogin=Username
# TimedLoginDelay=10
|
7. Anpassung des Netzwerks:
Hier bitte nur eine Auswahl verfolgen.
Entweder man verwendet den Netzwerkmanager links (bei häufig wechselnden Adressen & WLANs, VPN oder DSL Einwahl) oder man stellt die IP-Adresse fest ein (rechts).
| Netzwerkkonfiguration über Netzwerkmanager (WLAN, VPN, DSL): |
IP-Adresse fest einstellen (Server) bis Ubuntu 17.04: |
Eine Möglichkeit ist es den Netzwerkmanager zu verwenden, um die Netzwerkeinstellungen zu ändern. Der Netzwerkmanager wird verwendet, um Netzwerkeinstellungen mit Hilfe einer Programmoberfläche vorzunehmen.
Zum Beispiel kann man hier WLANs auswählen, VPN oder eine DSL Einwahl konfigurieren oder statische IP-Adressen vergeben.
Will man die Netzwerkeinstellungen anpassen, so empfiehlt es sich den Netzwerkmanager nach zu installieren:
apt-get install network-manager network-manager-gnome network-manager-openvpn-gnome
Hinweis: [network-manager-openvpn-gnome] muss man nur installieren wenn man VPN-Verbindungen mit dem Netzwerkmanager einrichten will.
Zuerst muss man die Konfiguration der Netzwerkkarte hier deaktivieren:
nano /etc/network/interfaces
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
# Das loopback-Netzwerkinterface also Original belassen.
# The primary network interface
# allow-hotplug eth0
# iface eth0 inet dhcp
# Und das Netzwerkinterface der Karten auskommentieren (deaktivieren)
# die man über den Netzwerk-Manager einstellen will.
Gleich im Anschluss muss man dann folgende Konfigurationsdatei editieren (nicht immer nötig):
nano /etc/NetworkManager/NetworkManager.conf
Hier den vorhandenen Eintrag wie folgt ändern:
managed=true
Damit der NetworkManager auch noch im Taskleisten-Tray erscheint (je nach Umgebung vorher testen) muss man noch folgende Datei editieren (nicht immer nötig):
nano /etc/xdg/autostart/nm-applet.desktop
# Und hier in der Zeile:
Exec=
# den Eintrag [nm-applet]
in [dbus-launch nm-applet] ändern.
Die Netzwerkeinstellungen werden erst nach einem Neustart übernommen. |
Die Lösung hier gilt bis Ubuntu 17.04. Ab Ubuntu 17.10/18.04 wird netplan verwendet.
Eine andere Möglichkeit der Netzwerkanpassung besteht durch direktes anpassen der Konfigurationsdateien.
Statische IP-Adresse vergeben:
Die Netzwerk-Konfigurationsdatei öffnen:
nano /etc/network/interfaces
die vorhandene Standardkonfiguration:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
allow-hotplug eth0
iface eth0 inet dhcp
wie folgt ändern (IP-Adressen entsprechend anpassen):
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
allow-hotplug eth0
iface eth0 inet static # eth0 ist die Netzwerkschnittstelle. Beachtet dabei,
# dass diese ab Ubuntu 15.10 unterschiedliche Namen tragen kann.
address 192.168.2.100
netmask 255.255.255.0
gateway 192.168.2.1
broadcast 192.168.0.255
network 192.168.0.0
dns-search domain.localnet intern.home # Man kann mehrere Domänennamen/Subdomänen angegeben.
dns-domain domain.localnet
dns-nameservers 192.168.2.1 8.8.8.8 # DNS-Server (Lokal & Internet, hier z. B. der Google DNS-Server).
# Wichtig: Hier kann man einen, oder maximal zwei DNS-Server angeben.
# Lässt man die DNS-Serverangabe weg, so kann es zu verschiedensten Fehlern
# wie [unknown host], [... konnte nicht aufgelöst werden.] kommen.
# Daher sollte man den DNS-Server-Eintrag in der Regel immer mit angeben.
# Im Home-Office sollte dies in der Regel die IP-Adresse des Routers/Gateways sein.
# 8.8.8.8 ist ein freier öffentlicher DNS-Server von google.
hwaddress ether 00:11:22:33:44:55 # Optional die MAC-Adresse ändern (erleichtert ggf. die Netzwerkübersicht).
# Hinweis: Ändert man unter VirtualBox in der VM die MAC-Adresse, dann hat man keinen Netzwerkzugriff mehr.
# Verwendet man VirtualBox, so kann man die MAC-Adresse nur
# über den Menüpunkt [Netzwerk] im [Oracle VM VirtualBox Manager] ändern.
|
| den Netzwerk Interface Namen ändern (optional): |
IP-Adresse fest einstellen (Server) ab Ubuntu 17.10/18.04: |
Ab Ubuntu 15.10 erhalten die Netzwerkschnittstellen neue Interface Namen.
Die Namen orientieren sich dabei unter anderem an der Art des Anschlusses (onboard, PCI-Express, USB, WLAN).
Statt eth0, eth1 heißt der Interface Name der Netzwerkkarte dann z. B. enp0s3, enps21, eno1, wlp3s0 usw.
Insbesondere im Betrieb an- und abschaltbare Netzwerkkarten/Geräte wie z. B. USB-Netzwerkkarten machten eine Anpassung des alten Namenschemas erforderlich.
Für die Namensvergabe ist udev verantwortlich.
Im Allgemeinen empfehle ich die Einstellung nach dem neuen Schema zu belassen.
Falls man den Namen trotzdem ändern will so empfehle ich folgende 2 Varianten.
Ändern kann man den Namen wie folgt:
Variante 1 (empfohlen/Update fest):
folgende Datei neu anlegen/ändern:
nano /etc/udev/rules.d/999-network.rules # Die hohe Nummer sorgt dafür, dass dieser Eintrag bei einem Update bestehen bleibt.
# Hier folgendes in einer Zeile einfügen:
SUBSYSTEM=="net", ACTION=="add", ATTR{address}=="11:22:33:44:55:66", NAME="eth0"
SUBSYSTEM=="net", ACTION=="add", ATTR{address}=="aa:bb:cc:dd:ee:ff", NAME="eth1"
# Hinweise:
# Für jede Netzwerkkarte wird ein separater Eintrag erzeugt.
# Die doppelten Gleichheitszeichen muss man genauso mit übernehmen.
# Die MAC-Adresse muss zur jeweiligen Netzwerkkarte passen.
# Alle Buchstaben der MAC-Adresse muss man klein schreiben (sofern welche vorkommen).
# Den Name kann man dabei beliebig wählen, eth0, eth1 sind nur Vorschläge nach dem alten Schema.
Nach einem Neustart ist die Netzwerkkarte über den neuen Namen erreichbar.
Variante 2 (weniger empfohlen/nicht Update fest):
nano /etc/default/grub
# Hier die folgende Zeile wie folgt ergänzen:
...
GRUB_CMDLINE_LINUX="net.ifnames=0 biosdevname=0"
...
# Beachtet: Bei einem Kernel Update/Grub Update wird diese Einstellung möglicherweise wieder zurückgesetzt.
Anschließend muss man noch die geänderten grub Einstellungen aktualisieren:
update-grub
Wichtig:
Beachten sollte man, dass man bei der dazugehörigen Netzwerkkonfiguration
unter [/etc/netplan/*] bzw. [/etc/network/interfaces] (siehe rechte Spalte)
den Netzwerkinterface-Namen entsprechend angepassen muss.
Hier im Beispiel müsste man dann aus enp0s3 -> eth0 machen.
Nach einem Neustart ist dann die Netzwerkkarte über den neuen Namen erreichbar.
|
Ab Ubuntu 17.10, 18.04 ... wird netplan zur Netzwerkkonfiguration verwendet.
Mit netplan sind vielfältige Konfigurationsvarianten möglich.
Unter anderem wird dhcp, static-ip, wakeonlan, routen, bridges, wifi (mit Passwortangabe) und vieles mehr unterstützt.
Eine statische IPv4-Adresse richtet man wie folgt ein:
In das Konfigurationsverzeichnis wechseln:
cd /etc/netplan
Alle Netzwerkkonfigurationen auflisten:
ls -laF
Beachtet dabei, der Konfigurationsname kann verschieden sein, auch mehrere Konfigurationsdateien sind möglich. Legt man mehrere Konfigurationen an, so werden diese in lexikalischer Reihenfolge (0-9 & A-Z) eingelesen.
# Zu Beginn ist oft nur eine einzelne yaml-Konfigurationsdatei zur Netzwerkkonfiguration vorhanden.
# Diese sollte man öffnen:
nano 50-cloud-init.yaml # Den Dateinamen ggf. anpassen (neue Standarddatei ab Ubuntu 22.04).
nano 01-netcfg.yaml # Den Dateinamen ggf. anpassen (Standarddatei ab Ubuntu 17.10).
nano /etc/netplan/* # Oder wenn es nur eine Konfiguration gibt, diese direkt öffnen.
die vorhandene Standardkonfiguration:
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
enp0s3: # Beachtet der Interface-Name der Netzwerkkarte ist Geräteabhängig/verschieden.
dhcp4: yes
dhcp6: yes
wie folgt ändern (IP-Adressen entsprechend anpassen):
Update: ab Ubuntu 22.04:
Ab Ubuntu 22.04 wurde der Parameter 'gateway4' für das Standard-Gatway durch 'routes' ersetzt.
Für Installationen ab 22.04 solltet ihr daher die Konfigurationsdatei wie folgt abändern.
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
ethernets:
enp0s3: # Den Interface-Name der Netzwerkkarte muss man entsprechend übernehmen.
dhcp4: no # Den automatischen Bezug von IPv4-Adressen ausschalten.
# dhcp6: no # Den automatischen Bezug von IPv6-Adressen ausschalten (APIPA Adresse).
addresses: [192.168.2.100/24] # statische IPv4-Adresse und Subnetzmaske.
routes:
- to: default
# - to: 0.0.0.0/0 # Alternative Schreibweise (also statt: - to: default).
via: 192.168.2.1 # Standardgateway, meist die DSL-Router IP-Adresse.
nameservers:
addresses: [192.168.2.1, 1.1.1.1, 9.9.9.9, 8.8.8.8] # DNS-Server Lokal & Internet.
Wichtige Parametererklärungen und Ergänzungen:
0.0.0.0/0 = Entspricht der 'Default-Route' - das bedeutet:
Alle Netzwerkpakete, für die keine spezifische Route existiert, werden an das Standard-Gateway weitergeleitet.
Verwendet hier aber nur eine Variante, entweder mit '- to: default' oder '- to: 0.0.0.0/0'.
Der Parameter gateway4: wie er von Ubuntu 17.10 bis 22.04. galt, wird in zukünftigen Versionen nicht mehr unterstützt.
Der Parameter wird (so nach aktuellem Stand) auch nicht automatisch angepasst (bei einem Update/Upgrade).
Tipp: Passt diesen Eintrag daher rechtzeitig vor dem nächsten größeren Upgrade an.
Beachtet auch:
Alle Nachfolgenden Hinweise - wie Tabs, Einrückungen usw. - der älteren Version gelten weiterhin (lest daher den Rest noch weiter).
Für ältere Ubuntu-Versionen von 17.10 bis 22.04 gilt folgendes:
wie folgt ändern (IP-Adressen entsprechend anpassen):
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
ethernets:
enp0s3: # Den Interface-Name der Netzwerkkarte muss man entsprechend übernehmen.
dhcp4: no # Den automatischen Bezug von IPv4-Adressen ausschalten.
# dhcp6: no # Den automatischen Bezug von IPv6-Adressen ausschalten (APIPA Adresse).
addresses: [192.168.2.100/24] # statische IPv4-Adresse und Subnetzmaske.
gateway4: 192.168.2.1 # Standardgateway, meist die DSL-Router IP-Adresse.
nameservers:
addresses: [192.168.2.1, 1.1.1.1, 9.9.9.9, 8.8.8.8] # DNS-Server Lokal & Internet.
# Parametererklärungen:
# IP-Adresse und Subnetzmaske:
# 192.168.2.100 = ist die feste IP-Adresse die man vergeben will.
# /24 = bestimmt die Subnetmaske (3 Bytes * 8 Bits = 24 Bits = 255.255.255.0).
# DNS-Server Adressen:
# 192.168.2.1 = ist hier Beispielsweise ein lokaler DNS-Server. Beachtet dabei, ein
# DSL-Router verwendet in der Regel nur einen DNS-forwarder über das Standardgateway.
# Die IP-Adresse vom DSL-Router sollte man daher hier nicht angegeben.
# 1.1.1.1 = ist der freie DNS-Server von CloudFare + APNIC.
# 9.9.9.9 = ist der freie DNS-Server von Global Cyber Alliance (GCA) + Partner.
# 8.8.8.8 = ist der freie DNS-Server von Google.
# Wichtiges:
# Die Konfiguration darf keine Tabulator-Zeichen enthalten.
# Zum Einrücken sind nur Leerzeichen erlaubt. Wenn man doch Tabs verwendet hat, dann
# erhält man den Fehler: [ Invalid YAML at ... found character that cannot start any token].
# Wenn die Einrückung nicht stimmt dann erhält man den Fehler:
# [ Invalid YAML at /etc/netplan/ ... mapping values are not allowed in this context]
# Beachtet hier folgendes:
# Alle Schlüssel muss man mit Leerzeichen wie oben dargestellt nach rechts einrücken.
# Dies ist notwendig, damit das System die Schlüssel korrekt zuordnen kann.
# Hier noch ein Beispiel. 'addresses' gibt es z. B. zweimal.
# Der erste 'addresses' Schlüssel bezieht sich auf die Netzwerkkarte (hier enp0s3),
# dieser bestimmt die IP-Adresse der Netzwerkkarte.
# Der zweite 'addresses' Schlüssel bezieht sich auf 'nameservers',
# dieser gibt hier die Adresse(n) zum DNS-Server an.
# Damit das System die doppelten Werte korrekt zuordnet, muss man diese entsprechend einrücken.
# Man erhält den Fehler: [ Error in network definition /etc/netplan/ ... unknown key adresses],
# wenn man die Schlüssel also den Teil links vor dem Doppelpunkt falsch geschrieben hat.
# Man erhält den Fehler: [ Error in network definition /etc/netplan ... expected sequence],
# wenn man die eckigen Klammern [ ] bei Schlüsseln mit mehreren Werten nicht vorhanden sind.
# Beachtet auch, zu den angezeigten fehlerhaften Zeilen (line) und Spaltennummern (column)
# muss man in der Regel immer eins (+1) dazu addieren.
Die neuen Einstellungen werden bei einem Neustart automatisch übernommen.
Mit folgendem Befehl kann man die Änderungen sofort prüfen und übernehmen:
netplan apply
Eventuelle Fehler werden sofort angezeigt.
Wird nach Eingabe des Befehls nichts angezeigt, dann ist alles ok.
Für debug Zwecke kann man folgenden Befehl verwenden:
netplan --debug apply
Hier sieht man dann mehr Details, so kann man ggf. Fehler leichter finden und beheben.
Aufruf der Hilfe mit:
man netplan
Von der Konfigurationsdatei sollte man vor der Bearbeitung eine Sicherung anlegen.
Da netplan nur *.yaml Dateien verarbeitet, empfehle ich das Anhängen des Datums.
Beispielsweise so (Dateiname & Pfad entsprechend anpassen):
cp 50-cloud-init.yaml 50-cloud-init.yaml.2025-07-10
bzw. so bei älteren Versionen:
cp 01-netcfg.yaml 01-netcfg.yaml.2018-06-05
Wenn mehrere netplan-Konfigurationsdateien existieren,
werden diese lexikografisch aufsteigend (alphabetisch von klein nach groß)
nacheinander abgearbeitet.
Das bedeutet die Abarbeitung erfolgt in der Reihenfolge:
- /etc/netplan/01-cloud-init.yaml (Verarbeitung zuerst)
- /etc/netplan/50-cloud-init.yaml (Verarbeitung als zweites)
- /etc/netplan/99-cloud-init.yaml (Verarbeitung am Ende)
Wenn man nicht nur keine Ziffern am Start verwendet ist die Sortierung wie folgt:
- Zuerst alle Ziffern, zum Beispiel 00-config.yaml bis 99-config.yaml
- Danach alle Großbuchstaben: A - Z, zum Beispiel Archiv-LAN-yaml
- Danach kämen alle Kleinbuchstaben: a -z, zum Beispiel: wireless.yaml
Bei unterschiedlichen Netzwerk-Schnittstellen wie WLAN/LAN usw.
kann es ggf. Sinn machen diese in separaten Konfigurationsdateien getrennt zu erfassen.
Eine Trennung der einzelnen Schnittstellen kann ggf. eine Fehlersuche deutlich erleichtern.
Hierzu noch folgende kurze Anmerkungen:
Man sollte sich bevorzugt mit dem neuen Schema befassen (das ist Zukunftssicher).
Ich empfehle daher nicht auf das alte Schema umzuschalten (auch das wäre möglich).
Vor allem sollte man niemals alte Konfigurationen (/etc/network/interfaces) und
neue netplan Konfigurationen (/etc/netplan/*) zur gleichen Zeit verwenden.
Um Problemen aus dem Weg zugehen solltet ihr hier nur einen Weg nutzen.
Ich persönlich würde ab Ubuntu 17.10/18.04 die neuen Einstellungen über netplan nutzen. |
Tipps zum Netzwerk:
Änderungen am Netzwerk werden erst übernommen wenn man das Netzwerk neu startet.
ip -c a = Zeigt die derzeitige Netzwerkkonfiguration farblich hervorgehoben an.
ip link = Zeigt die MTU Einstellung und MAC-Adressen an.
ifconfig -a = Zeigt die derzeitige eingestellte Konfiguration an.
networkctl status -a = Status-Anzeige der verwendeten Netzwerklinks.
ifup eth0 = startet das Netzwerk eth0.
ifdown eth0 = beendet das Netzwerk eth0.
ping 192.168.2.1 = setzt Ping Pakete an die Adresse 192.168.2.1 ab.
netstat -npl = Zeigt Aktive Internetverbindungen, Sockets und die verwendeten Ports an.
netstat -s = Zeigt verschiedene Paketstatistiken an.
apt-get install traceroute = Installiert das Linux Pendant zum Windows Befehl [tracert]
um Routen zu verfolgen [traceroute IP oder Hostname].
/etc/hostname = die Datei enthält den Hostnamen des eigenen Systems.
/etc/hosts = in der Datei kann man IP-Adressen und Domain-Namen sowie lokale PC-Namen zuweisen (auch für Werbeblocker geeignet).
8. hosts-Datei/WINS/NetBIOS Hostnamen auflösen (winbind):
Wichtig in kleinen Netzwerken:
Wenn man keinen eigenen DNS-Server eingerichtet hat (also nur einen Standard DSL-Router verwendet), dann macht der Router nicht automatisch eine Namensauflösung,
denn der Router leitet die Namens-Anfragen nur an die vom Provider bereitgestellten DNS-Server im Internet weiter.
Diese DNS-Server im Internet kennen jedoch die PCs und Geräte im LAN nicht und eine Namensauflösung schlägt fehl.
Daher kann der Router diese Hostnamen nicht auflösen.
Um das Problem zu lösen installiert man entweder einen DNS-Server (wie z. B. bind9) oder einen WINS-Server (der Windows Internet Name Service (WINS) übernimmt die Namensauflösung von NetBIOS-Computernamen).
Am einfachsten installiert man den [samba nameservice integration server] (winbind):
apt-get install winbind
Danach muss man nur noch folgende Konfigurationsdatei anpassen:
nano /etc/nsswitch.conf
# Hier ändert man die Zeile hosts: wie folgt ab:
...
hosts: files wins dns
...
Parameterbeschreibung:
Die Hostnamenauflösung aller Netzwerkgeräte (PCs, Drucker, Tablet ...) sollte damit sofort klappen.
Denn winbind dient der Integration von Namensdiensten für Samba-Server und erledigt das Auflösen von Benutzer-/Gruppeninformation für Microsoft Windows, OS X, und andere Unix-Systeme.
Die Reihenfolge der Abfragen kann man beliebig festlegen:
[files] steht für die Abfrage über die [/etc/hosts]-Datei.
[wins] steht für die Abfrage über den WINS-Server.
Wenn kein WINS-Server im Netzwerk vorhanden ist geschieht die WINS-Namensauflösung über NetBIOS-Broadcast.
Das bedeutet nichts anderes, als dass ein Computer, der einen Hostnamen im Netz auflösen möchte, einen Broadcast (Rundruf) ins lokale Netzwerk (an alle im Subnetz) sendet und so den angesprochenen Empfänger auffordert mit seiner
IPv4-Adresse (WINS ist nicht IPv6 kompatibel) zu antworten. Auf Grund wie diese Informationen über das Netzwerk übermittelt werden kann dies ggf. ein Sicherheitsrisiko darstellen (wenn kein Zentraler Server vorhanden ist).
WINS beantwortet nur Antworten aus dem eigenen Subnetz - Routen in andere Netze schlagen daher oft fehl.
NetBIOS-Namen (Hostnamen) dürfen maximal nur 15 Zeichen lang sein.
[dns] steht für die Abfrage über den DNS-Server.
Die [winbind]-Installation behebt also typische Namensauflösungsfehler wie z. B.: [ping: unknown host] (ping),
[server can't find ... : NXDOMAIN] (nslookup), [... : Der Name oder Dienst ist nicht bekannt] (traceroute).
Alternativen:
Will man nicht noch einen extra Daemon laufen lassen, so kann man Hostnamen auch über die [hosts]-Datei bekannt machen:
nano /etc/hosts
9. Netzwerk browsing aktivieren:
Kann man das Netzwerk nicht nach (Windows) Freigaben durchsuchen, so muss man folgendes Paket nachinstallieren:
apt-get install gvfs-backends
Dieses ermöglicht das Einhängen von virtuellen Dateisystemen, also das Einhängen von verschiedensten Freigaben (wie z. B. ftp, http, network, sftp, smb, smb-browse, usw.).
10. Empfehlenswerte Zusatzprogramme:
Da einige Minimalinstallationen sehr spartanisch daher kommen, hier noch ein paar empfohlene/wichtige Programme die man je nach Bedarf nach installieren kann.
Einträge die mit Sternen gekennzeichnet wurden sind meine persönliche Bewertung (mehr Sterne [*] = besser - bewertet wurde der Funktions- und Bedienungsumfang).
Einträge die mit einem Herzen [♥] gekennzeichnet wurden sind meine besonderen Empfehlungen.
Am Ende ist bei einigen Programmen in Klammern die jeweils dazugehörige Standard Systemumgebung angegeben.
Natürlich kann man die Programme unter jeder beliebigen Distribution installieren.
apt-get install update-manager - installiert ein Programm um System-Updates zu installieren (für alle auf Ubuntu basierende Systeme).
apt-get install pcmanfm - ** installiert einen Dateimanager (LXDE).
apt-get install gnome-system-monitor - ** installiert einen Taskmanager, der unter anderem den CPU- und RAM-Verbrauch sowie Netzwerk-Traffic anzeigen kann (Gnome).
apt-get install mate-system-monitor - installiert einen Taskmanager, der unter anderem den CPU- und RAM-Verbrauch sowie Netzwerk-Traffic anzeigen kann (MATE).
apt-get install xfce4-taskmanager - * installiert einen einfachen Taskmanager, der unter anderem den CPU- und RAM-Verbrauch anzeigen kann (Xfce).
apt-get install lxtask - installiert einen einfachen Taskmanager, der unter anderem den CPU- und RAM-Verbrauch anzeigen kann (LXDE).
apt-get install mousepad - **♥ einen Text Editor mit Syntaxhervorhebung installieren (Xfce).
apt-get install pluma - ***♥ installiert einen Text Editor mit Syntaxhervorhebung und Plugin-Optionen -
wie z. B. eine Rechtschreibprüfung [apt-get install hunspell-de-de] (MATE).
apt-get install leafpad - einen Text Editor installieren (LXDE).
apt-get install synaptic - eine grafische Paketverwaltung installieren.
apt-get install xfce4-terminal - **♥ installiert ein Terminal, in dem man auch eigene Fonts verwenden kann (Xfce).
apt-get install lxterminal - installiert ein Terminal, in dem man auch eigene Fonts verwenden kann (LXDE).
apt-get install virtualbox-guest-x11 - die VirtualBox Gasterweiterungen installieren. Optionale Pakete [virtualbox-guest-dkms] & [virtualbox-guest-utils].
apt-get install firefox firefox-locale-de - installiert den Webbrowser Firefox.
apt-get install iceweasel iceweasel-l10n-de - installiert den auf Firefox basierenden Webbrowser unter Debian.
apt-get install chromium-browser chromium-browser-l10n chromium-codecs-ffmpeg chromium-codecs-ffmpeg-extra - installiert Google Chrome, mit Multimedia-Codecs, wie z. B. AAC/AC3/MPEG-4 Audio/H264/QuickTime/MP3.
apt-get install chromium chromium-l10n - installiert Google Chrome unter Debian.
apt-get install thunderbird thunderbird-locale-de - installiert das E-Mailprogramm Thunderbird unter Ubuntu.
apt-get install icedove icedove-l10n-de - installiert ein E-Mailprogramm (basiert auf Thunderbird) unter Debian.
apt-get install midori - installiert einen schlanken Webbrowser (Xfce4).
apt-get install fonts-croscore - ♥ installiert den Monospace Font 'Cousine' (bei Debian erst ab Version 8 verfügbar) z. B. fürs Terminal.
apt-get install xfonts-terminus - installiert den Terminus Font z. B. fürs Terminal.
apt-get install language-pack-gnome-de - installiert fehlende Sprachpakete nach (Gnome).
apt-get install language-pack-de - installiert fehlende Sprachpakete nach (Metapaket für Systemanwendungen).
apt-get install oxygen-icon-theme - installiert ein alternatives Icon-Thema.
apt-get install xarchiver - installiert einen Packer (Xfce).
apt-get install Xfburn - installiert eine Brennsoftware (Xfce).
apt-get install brasero - * installiert eine Brennsoftware die unter anderem auch CD/DVD kopieren kann (auch als Image).
apt-get install lxmusic - installiert einen einfachen Musikplayer (LXDE).
apt-get install vlc - * installiert den VLC media player von VideoLAN.org (vlc startet ggf. nicht wenn man als root-User angemeldet ist).
apt-get install parole - installiert einen schlanken Videoplayer (Xfce4).
apt-get install gpicview - ** installiert einen Bildbetrachter (LXDE).
apt-get install ristretto - * installiert einen Bildbetrachter (Xfce4).
apt-get install eom - installiert den Bildbetrachter Eye-of-Mate (MATE).
apt-get install xfce4-whiskermenu-plugin - installiert unter Xfce ein schlichtes alternatives Startmenü (dieses kann man dann der Leiste hinzufügen).
Funktionen wie: Favoriten, Gliederung der Anwendungen, Anzeige der zuletzt genutzten Programme, oder eine Suchfunktion werden hier bereitgestellt.
apt-get install adblock-plus - installiert einen Werbefilter für den Webbrowser.
apt-get install warmux supertux pingus monkey-bubble tecnoballz lbreakout2- installiert folgende Games: einen Worms Clone, ein Jump'n'Run,
ein Lemmings-Clone, ein Bubble-Spiel und zwei Breakout's Clones. Die gelb hervorgehobenen laufen unter einer VM eher schlecht.
apt-get install ubuntu-restricted-extras - installiert unfreie Code-Plugins unter anderem gstreamer, ffmpeg, adobe-flashplugin und MS-Fonts (Ubuntu).
apt-get install flashplugin-nonfree installiert den Adobe Flashplayer - unter Umständen muss die [Multiverse]-Paketquelle hinzufügen.
apt-get install openjdk-9-jdk openjdk-9-source openjdk-9-demo openjdk-9-doc openjdk-9-jre-headless - installiert das Java-Development-Kit (für Entwickler).
apt-get install openjdk-*-jre icedtea-*-plugin - installiert immer die aktuelle Java Version incl. Webbrowser-Plugin.
Hinweis: Setzt man statt der Versionsnummer den Joker '*' ein, so wird immer automatisch die aktuelleste Version ausgewählt.
apt-get install compizconfig-settings-manager compiz-plugins-extra - (universe) erweiterte Effekte (wie einen 3D-Desktop, abbrennende-, wabbelnde- und explodierende-Fenster uvm.)
nachrüsten (Ubuntu). [ccsm] startet den 'CompizConfig Einstellungs-Manager', alle geänderten Einstellungen werden im Ordner [~/.gconf/] gespeichert.
Bei Fehlern sollte man diesen Ordner löschen und neu starten.
apt-get install p7zip-full - installiert den Packer 7-zip.org [7z].
apt-get install ntfs-3g - Lese- und Schreibzugriff für NTFS-Dateisysteme nachrüsten (nur Debian/unter Ubuntu bereits integriert). In aktuellen Live-Systemen ist dies meist schon installiert.
apt-get install hardinfo sysinfo lshw lshw-gtk - installiert verschiedene Tools um Hardware-Infos an zu zeigen (für Console & XServer).
apt-get install gsmartcontrol smartmontools - installiert Tools um SMART-Werte (Self-Monitoring, Analysis, and Reporting Technology)
von SSDs & HDs anzuzeigen & zu überwachen [smartctl -a /dev/sda].
apt-get install libreoffice libreoffice-l10n-de libreoffice-help-de - installiert das komplette LibreOffice.
apt-get install gimp gimp-help-de - installiert GIMP2.
apt-get install testdisk - sucht und repariert gelöschte Partitionstabellen (Hinweis: testdisk stellt den MBR nicht wieder her).
Alternativ kann man zum Partitionen wieder herstellen [gpart -g -i -W /dev/sda /dev/sda] verwenden - gpart unterstützt zurzeit allerdings kein ext3 & ext4.
apt-get install qpdfview - Installiert einen PDF-Viewer.
11. Paketquellen entfernen:
Will man Programme nachinstallieren, so wird unter Debian oft nach der Installations-CD/DVD gefragt.
Hat man diese nicht mehr zur Hand, oder will man aus Bequemlichkeit lieber die Online-Quellen verwenden,
so kann man diese einfach auskommentieren. Öffnet hierzu die Datei:
nano /etc/apt/sources.list
# Hier ändert man alle Einträge, die den Eintrag [cdrom:] enthalten:
deb cdrom: [...] / ... main
# so ab:
# deb cdrom: [...] / ... main
# Man fügt also vor die Entsprechenden Zeilen ein Rautezeichen [#] ein.
# Das Rautezeichen bewirkt, dass diese Zeilen nicht mehr ausgewertet wird.
12. TTY Terminal Consolen Font ändern & Tipps zur Console:
Damit mehr in der in den Consolen (Strg + Alt und F1 bis F7) angezeigt wird, kann man einen anderen Font auswählen:
dpkg-reconfigure console-setup
Hier wählt man dann z. B. folgendes:
UTF-8
# Latin1 und Latin5 - ...
Terminus (optional TerminusBold oder Fixed)
8x14
Danach haben die Terminals z. B. 28 statt 25 Zeilen.
Möglichkeit 2 bzw. Workaround falls die Einstellungen nach einem Neustart nicht übernommen werden:
Unter Ubuntu 15.04/Ubuntu 15.10 wird die Einstellung von [dpkg-reconfigure console-setup] nach einem Neustart vergessen (bug?).
Man kann hier einfach in der Datei:
nano /etc/rc.local
# Hier vor dem Eintrag [exit 0] eine den entsprechenden Fontaufruf hinzufügen (hier 2 Vorschläge):
/bin/setfont /usr/share/consolefonts/Lat7-Terminus14.psf.gz
/bin/setfont /usr/share/consolefonts/Lat7-Fixed13.psf.gz
# Weitere Fonts und Größen findet man im Verzeichnis [/usr/share/consolefonts/].
Tipps zum Terminal/zur Console:
Seitenweises scrollen im Terminal über Shift + Bild auf bzw. Shift + Bild ab.
Strg + r die letzten Befehlseingaben durchsuchen.
Strg + a Cursor an Zeilenanfang setzen.
Strg + e Cursor an Zeilenende setzen.
Strg + u Zeileninhalt löschen.
Strg + Shift + v etwas im Terminal einfügen (anders als zum Beispiel in Windows).
Die Terminal/Consolen Historie löschen:
Gespeichert wird die Historie in einer versteckten Text-Datei mit dem Namen [.bash_history], in der Regel liegt die Datei direkt im entsprechenden Userprofil.
Hierzu vorab noch folgender Tipp: Beginnt man den Kommandozeilenbefehl mit einem Leerzeichen, so wird dieser nicht in der Historie gespeichert.
Den Historie-Cache löschen:
history -cw
Parameterbeschreibung:
[-c] = (clear) löscht die Historie.
[-w] = (write) schreibt die [.bash_history]-Datei neu.
[-cw] = löscht also die Historie & speichert diese sofort (leer) ab.
Man kann die History auch löschen in dem man die History-Datei selbst löscht.
rm ~/.bash_history
Da sich ggf. noch eine Kopie der History im RAM befindet, muss man im Anschluss noch alle Terminals schließen - dann sollte die History leer sein.
13. Grafische Fernsteuerung/Fernwartung der Server:
Die Vorgestellten Lösungen sind eine Auswahl, diese wurden getestet und für gut befunden.
Es gibt natürlich noch eine Vielzahl anderer Möglichkeiten zur Fernsteuerung. Hier sollte man sich also je nach Bedarf die benötigte Verbindung heraussuchen.
| xrdp (RDP): |
vino (VNC): |
x11vnc (VNC): |
Um von Windows aus auf den Desktop zu zugreifen installiert man am einfachsten den xrdp Server (Remote Desktop Protokoll)
(sourceforge.net/projects/xrdp, xrdp.org):
apt-get install xrdp
Anpassungen unter:
mousepad /etc/xrdp/xrdp.ini
xrdp erzeugt neue virtuelle X-Sitzungen, teilweise stimmten hier bei mir die Pfade nicht, so dass bei mir z. B. Installationen nicht klappten. |
Den VNC Server installieren:
apt-get install vino
Passwort und Einstellungen festlegen:
vino-preferences
vino-passwd
VNC Serverstart über:
/usr/lib/vino/vino-server
Problemlösung falls es nicht klappt (Verschlüsselung ausschalten):
apt-get install dconf-editor
Den Editor starten:
dconf-editor
Hier unter [org] >[gnome] > [desktop] > [applications] > [remote-access],
bei [require-encryption] den [ ] Haken entfernen.
Wenn man will kann man hier auch einen [view-only] Modus aktivieren.
Hinweis: Achtung die Tastaturbelegung ist US nicht DE. |
Der x11vnc Server gefällt mir persönlich derzeit am besten, denn x11vnc gibt 1:1 den tatsächlichen Bildschirminhalt wieder.
x11vnc Installieren über:
apt-get install x11vnc
Starten kann man den Server (ohne Passwortabfrage) über:
x11vnc
Beim Starten sollte man die angezeigte Portadresse beobachten.
Zunächst sollte man ein Passwort festlegen (mit eigenem Pfad zur Passwortdatei):
x11vnc -storepasswd P@ssw0rD /etc/x11vnc.pass
Man sollte diese Datei auch für andere lesbar machen (so das auch Standard-User eine VNC-Verbindung aufbauen können):
chmod 644 /etc/x11vnc.pass
Den Server kann man jetzt mit Passwortabfrage starten (mit eigenem Pfad zur Passwortdatei) einmaliger Verbindungsaufbau:
x11vnc -rfbauth /etc/x11vnc.pass
Alternativ kann man das Passwort auch über die Terminal Zeile eingeben:
Das Passwort wird hierbei im Terminal abgefragt und automatisch verschlüsselt in der Datei ~/.vnc/passwd im User-Home-Dir gespeichert.
x11vnc -storepasswd
Der Server wird dann so gestartet (es wird hierbei dann die oben angelegte ~/.vnc/passwd Passwortdatei aus dem User-Home-Dir verwendet.):
x11vnc -usepw
Den Server mit einem bestimmten Port starten:
x11vnc -rfbport 5900
Den Server für einen dauerhaften Verbindungsaufbau bereit machen:
x11vnc -forever
Natürlich kann man die Parameter auch zusammen verwenden:
x11vnc -rfbauth /etc/x11vnc.pass -forever
-rfbport 5900 &
VNC Tastaturlayout auf Deutsch umstellen:
Unter Xfce wird das Tastaturlayout nicht übernommen.
Beheben kann man das Problem in dem man die Spracheinstellung fest auf die gewünschte Sprache einstellt.
Hierzu muss man unter [Einstellungen]
> [Einstellungen] > [Tastatur] > [Tastaturbelegung]
den [ ] Haken bei [Systemweite Einstellungen benutzen] entfernen.
Der Verbindungsaufbau vom Client aus erfolgt dann über IP-Adresse und Portangabe, also z. B. so:
192.168.2.1:5900 |
Sicherheitshinweise:
RDP-Verbindungen verwenden nur eine RC4-Verschlüsselung - diese gilt als nicht mehr 100 % sicher.
Auch VNC-Verbindungen sind nicht verschlüsselt, es werden z. B. Tastatureingaben im Klartext übertragen!
Es besteht daher die Gefahr, das Übertragungen belauscht und Passworte mitgeschnitten werden.
Man sollte daher RDP- und VNC-Verbindungen nur Netzintern bzw. abgesichert über ein VPN oder einen anderen gesicherten Tunnel verwenden.
Will man auf die Systeme gesichert (über das Internet) zugreifen, so empfiehlt sich die Nutzung von SSH (siehe Punkt 15).
14. vsftpd FTP-Server mit Benutzeranmeldung (FTP/FTPS):
vsftpd ist ein FTP-Server der auf besondere Sicherheit ausgelegt wurde (Very Secure File Transfer Protocol Daemon).
vsftpd ist schnell, stabil und sicher und wird bei den meisten Distributionen regelmäßig gepflegt und mit Sicherheitsupdates versorgt.
Daher würde ich vsftpd bevorzugt empfehlen.
Links: Original Webseite - vsftpd.conf Parametererklärungen
| vsftpd Grundkonfiguration & Benutzerkonfiguration: |
Absicherung mit Zertifikaten (FTPS-Server): |
Den FTP-Server installieren:
apt-get install vsftpd
Anschließend muss man Konfigurationsdatei öffnen:
nano /etc/vsftpd.conf
# Hier folgende Zeilen am Anfang hinzufügen:
userlist_deny=NO # Die Anmeldungen von allen lokalen Usern verbieten (erhöht die Sicherheit).
userlist_enable=YES # Ausgenommen sind nur lokale User die auf der unter [userlist_file] geführten Liste stehen.
userlist_file=/etc/vsftpd.user_list
# Optional: Die Datei wird geladen wenn [user_list] auf [YES] steht (Standard ist /etc/vsftpd.user_list).
local_root=/srv/ftp # In diesen Pfad wird nach einem Userlogin gewechselt. Hier müssen dann die bereitgestellten FTP-Daten hin.
# Und folgende vorhandene Zeilen ändern:
anonymous_enable=NO # Auf [NO] umändern = Anonymen Zugang nicht gestatten.
local_enable=YES # Das Rautezeichen [#] Am Anfang entfernen. Lokalen Benutzern den Login gestatten.
xferlog_enable=YES # Optionales Logging (Standard=YES). Kann man später auch ausschalten.
connect_from_port_20=NO # Auf [NO] umändern. Der Port 21 reicht in der Regel völlig aus.
ftpd_banner=Willkommen # Optional: Eigene Willkommensmeldung für FTP Gäste.
dirmessage_enable=YES # Anzeigen von [.message] Dateien.
use_localtime=NO # Optional: Wenn die Zeit im FTP abweicht auf [NO] stellen (war bei mir in VMs so).
chroot_local_user=YES # Hier das Rautezeichen [#] Am Anfang entfernen.
# Lokale Benutzer auf das Home Verzeichnis (definiert unter local_root) beschränken (erhöht die Sicherheit).
# Achtung den Eintrag gibt es zweimal, einen aktivieren reicht aus.
listen_port=21 # Optional: Wer mag kann auch den Standard-Port ändern.
# Ein geänderter Port kann auch Angriffe erschweren.
# Will man auf den FTP-Server über das Internet
# zugreifen, so muss man im Router für diesen Port
# eine entsprechende Weiterleitung einrichten.
Will man für Tests vorübergehend nur die Anonyme Anmeldung zulassen, so muss man [userlist_enable=NO]
und [anonymous_enable=YES] setzen, sowie den [vsftpd]-Dienst neu starten.
Als nächstes muss man die User hinzufügen die den FTP-Server besuchen dürfen:
nano /etc/vsftpd.user_list
Hier kann man dann die User hinzufügen denen der FTP-Zugang gewährt wird:
Benutzer1
Benutzer2
...
Wichtig:
Alle Änderungen werden erst nach einem Neustart des FTP-Servers übernommen.
Den Server Neustarten/Starten/Beenden:
service vsftpd restart
/etc/init.d vsftpd start
/etc/init.d vsftpd stop
Ab sofort funktioniert der FTP-Server. Benötigt man einen reinen öffentlichen Downloadserver ist man hier fertig.
Will man Daten hoch laden so muss man noch den Schreibzugriff aktivieren (siehe rechts unten).
Will man den Transfer verschlüsseln, so benötigt man Zertifikate um die Übertragung ab zu sichern (siehe rechts oben).
Willkommens Meldung anlegen (optional):
In den FTP-Bereich wechseln:
cd /srv/ftp/
Eine neue Datei anlegen:
nano .message
# Hier dann eine beliebige Willkommensmeldung eintragen:
Willkommen! Hinweis: Alle Zugriffe werden Protokolliert.
|
Absicherung mit Zertifikaten:
Vorbereitende Arbeiten:
openssl installieren & Verzeichnisse mit Berechtigungen anlegen (meist vorhanden):
apt-get install openssl
mkdir -p /etc/ssl/private
chmod 700 /etc/ssl/private
Das Zertifikat erzeugen:
openssl req -x509 -nodes -days 365 -newkey rsa:8192 -keyout /etc/ssl/private/vsftpd.pem -out /etc/ssl/private/vsftpd.pem
Die nachfolgenden Abfragen entsprechend ausfüllen:
Country Name ... = DE
State or Provice ... = Bundesland
Locality Name (eg, city) = Stadt
Organization Name ... = Firmenname
Organization Unit ... = Abteilung
Common Name ... = Domainname.de
Email Address ... = E-Mailadresse
Aus dem eben erzeugten Zertifikat extrahiert man den Privat-Key:
openssl rsa -in /etc/ssl/private/vsftpd.pem -out /etc/ssl/private/vsftpd.key
Anschließend muss man die Konfiguration wie folgt ergänzen:
nano /etc/vsftpd.conf
# folgende Zeilen am Anfang hinzufügen:
force_local_data_ssl=YES
force_local_logins_ssl=YES
ssl_ciphers=HIGH
# und folgende vorhandene Zeilen ändern:
rsa_cert_file=/etc/ssl/private/vsftpd.pem
rsa_private_key_file=/etc/ssl/private/vsftpd.key
ssl_enable=YES
# Folgende Einträge braucht man nicht hinzufügen,
# da diese im Default/Standardmäßig schon die richtigen Werte haben:
ssl_tlsv1=YES # Standard=YES
ssl_sslv2=NO # Standard=NO
ssl_sslv3=NO # Standard=NO
allow_anon_ssl=NO # Standard = NO
# Disable SSL session reuse:
# ist nur nötig bei wenigen speziellen Clients
# wie z. B. bei FireFTP.
# Diesen Wert daher nur einstellen,
# wenn dies wirklich benötigt wird.
# require_ssl_reuse=NO
Hinweis: Setzt man [force_local_logins_ssl=NO] und [force_local_data_ssl=NO],
so werden sowohl TLS (verschlüsselte Verbindungen mit Zertifikat) als auch nicht-TLS Verbindungen (unverschlüsselte Verbindungen) erlaubt, je nach dem was der FTP-Client unterstützt.
|
| einen reinen FTP-User anlegen (optional): |
Schreibzugriff aktivieren: |
Empfehlenswert ist es wenn man einen reinen FTP-Benutzer anlegt, der sich nicht am lokalen System anmelden kann.
Sinn und Zweck: Dies erhöht die Sicherheit des Systems bei möglichen Angriffen.
Den neuen FTP-Benutzer anlegen:
useradd usr_ftp_only -m -d /home/usr_ftp_only -s /bin/false
Parameterbeschreibung:
[usr_ftp_only] ist der Benutzername des neu anzulegenden Users, der Name ist natürlich frei wählbar.
[-m] (main) ist die Kurzform von [--create-home] > bedeutet: Beim Erstellen wird das Home-Verzeichnis mit erstellt.
[-d] (dir) ist die Kurzform von [--home] > bedeutet: Hier wird der Pfad zum Home-Verzeichnis festgelegt (ggf. ändern).
[-s] ist die Kurzform von [--shell] > bedeutet: legt die zu startende login shell fest.
Für den eben erzeugten User muss man noch ein Passwort vergeben:
passwd usr_ftp_only
Nun muss man noch die login shell (/bin/false) hinzufügen:
nano /etc/shells
hier also am Ende folgendes hinzufügen:
/bin/false
Ebenso sollte man nicht vergessen den User in der [vsftpd.user_list] einzutragen:
nano /etc/vsftpd.user_list
Den eben angelegten User hinzufügen (andere User ggf. löschen):
usr_ftp_only
|
Die Konfigurationsdatei öffnen:
nano /etc/vsftpd.conf
# und folgende Einträge anpassen:
write_enable=YES # Die Dateirechte (chmod) muss man ebenfalls setzen.
local_umask=022
und folgendes hinzufügen:
allow_writeable_chroot=YES # Falls man direkt ins FTP-Wurzelverzeichnis (FTP root Verzeichnis) schreiben will.
Will man nur einigen Usern das schreiben ins FTP-Wurzelverzeichnis (ins FTP root Verzeichnis) erlauben,
so sollte man sich die Einträge [chroot_local_users=YES], [chroot_list_enable=YES] und [chroot_list_file=/etc/vsftpd.chroot_list] genauer anschauen.
vsftpd erlaubt es Standardmäßig nicht das man direkt ins Wurzelverzeichnis des FTP-Servers (local-root=/srv/ftp) schreiben kann (es sei denn man hat dies durch [allow_writeable_chroot=YES] explizit erlaubt).
Am einfachsten umgeht man das Problem, in dem man ein Unterverzeichnis in dem FTP-Verzeichnis erstellt und hier die Schreibrechte erteilt.
mkdir /srv/ftp/net/
chmod 777 /srv/ftp/net/
Wichtige Hinweise & Fehlerbehebungen:
vsftpd ist auf Sicherheit ausgelegt und überprüft vor dem Start seine eigene Konfiguration und die Rechte aller Dateien auf die es zugreifen soll und verweigert den Start bzw. den Zugriff bei einer eventuell
falschen Konfiguration (siehe auch die FAQ auf der Herstellerwebseite). Hat man die Dateiberechtigung vom FTP-Wurzelverzeichnis (local-root=/srv/ftp) geändert, so kommen möglicherweise Fehler
wie [GnuTLS-Fehler -15: An unexpected TLS packet was received.] oder [Herstellen der Verbindung zum Server fehlgeschlagen].
Als Lösung hilft hier nur die original Berechtigungen wieder herstellen [chmod 755 /srv/ftp] und [chown root:ftp /srv/ftp]
oder man lockert die Sicherheitsbestimmungen durch Hinzufügen von [allow_writeable_chroot=YES].
Versucht man in die FTP-root zu schreiben kommen möglicherweise Fehler wie:
[553 Could not create file.], [Kritischer Dateiübertragungsfehler] oder [550 Create directory operation failed.].
Als Lösung hilft hier nur wie oben beschrieben 1. ein Unterverzeichnis anlegen und 2. die entsprechende Berechtigung zu vergeben oder man lockert die Sicherheitsbestimmungen durch Hinzufügen von [allow_writeable_chroot=YES].
Jeweils Dienstneustart nicht vergessen.
|
Clientzugriff Varianten ein-/ausblenden:
Zugriffsmöglichkeiten für den Client gibt es viele. Ich möchte hier nur ein paar ausgewählte gängige vorstellen:
Zugriff auf den Server mit FileZilla (Windows):
Hierzu muss man im Servermanager von FileZilla folgende Einstellungen vornehmen:
Server: IP-Adresse oder Domain
Port: 21 (kann man leer lassen)
Protokoll: FTP - File Transfer Protocol
Verschlüsselung: Explizites FTP über TLS anfordern
Benutzername: Benutzername
Passwort: Geheim (kann man auch weglassen - dann wird gefragt)
Zugriff auf den Server mit WinSCP (Windows):
In der Anmeldemaske muss man folgende Einstellungen vornehmen:
File protocol: FTP
Encryption: TLS/SSL Explicit encryption
Host name: IP-Adresse oder Domain
Port number: 21
User name: Benutzername
Password: Geheim (kann man auch weglassen - dann wird gefragt)
Zugriff auf den Server mit dem Browser-Plugin FireFTP (MultiOS/Cross-Platform):
Zuerst muss man die Erweiterung im Webbrowser installieren:
Im Firefox am einfachsten installieren über Menü [Extras] > [Add-ons] > [Erweiterungen],
hier in der Suchmaske oben rechts [FireFTP] eingeben und auf [Installieren] klicken.
Nach einem Browserneustart ist FireFTP aktiv.
Damit der Zugriff zum Server richtig funktioniert, muss in der [vsftpd.conf] der Eintrag [require_ssl_reuse=NO] vorhanden sein (Dienstneustart nicht vergessen).
Der Aufruf eines Servers funktioniert dann über: ftps://IP-Adresse_oder_Domain
Zugriff auf den Server mit dem Total Commander
mit dem Secure FTP Plugin (Windows):
Der Total Commander kann auch mit Hilfe des Secure-FTP-Plugins
nicht auf einen
FTPS-Server zugreifen.
Das Secure-FTP-Plugin im Total Commander
erwartet auf der Serverseite
zwingend einen
SFTP-Server.
Und vsftpd stellt aber nur einen FTPS-Server bereit. Also muss man einen zusätzlichen SFTP-Server einrichten.
Wie man einen SFTP-Server installiert habe ich unter dem
Punkt 15 beschrieben.
Hinweis zum Internet Explorer:
Der IE fragt nicht nach einem Benutzernamen & Passwort (er versucht immer eine Anonyme Anmeldung und bringt dann einen Fehler). Verwendet daher zum Testen einen anderen Browser.
Lösung: Der Zugriff über den IE klappt nur so (Namen, Passwort & IP-Adresse muss man entsprechend ändern):
ftp://Benutzername:Passwort@192.168.2.1
Ein paar wichtige optionale Parameter:
anon_upload_enable=YES # anonymous Anmeldungen Schreibzugriff erlauben (Verzeichnisrechte und [write_enable=YES] werden benötigt).
anon_mkdir_write_enable=YES # anonymous Anmeldungen das Erstellen von Verzeichnissen erlauben (Verzeichnisrechte und [write_enable=YES] werden benötigt).
anon_root=/data/directory # Den FTP-Pfad für die Anonyme Anmeldung festlegen.
anon_other_write_enable=YES # Erlaubt auch andere Dateioperationen wie Löschen oder Umbenennen oder Verzeichnisse zu erstellen.
anon_max_rate=10240 # Transferate in Bytes/Sekunde für Anonyme User (0=unbegrenzt/Standard).
local_max_rate=10240 # Transferrate in Bytes/Sekunde für lokale User mit Anmeldung (0=unbegrenzt/Standard).
max_clients=0 # Höchstzahl der zugelassenen Clients - weitere Clients erhalten eine entsprechende Fehlermeldung (0=unbegrenzte Clientanzahl/Standard).
hide_file={*.mp3,.hidden,hide*,h?} # Dateien vom Directorylisting ausblenden. Der Zugriff auf die Dateien ist nur möglich wenn man den Namen kennt. Ausschlüsse werden im Regex-Format festgelegt.
deny_file= # Zugriff auf die Datei(en) verbieten.
vsftpd_log_file=/var/log/vsftpd.log # Standardausgabe-Pfad für die Logdatei (benötigt [xferlog_enable=YES] - Standard=NO).
Protokolliert ausführlich alle Up- und Downloads.
download_enable=NO # Setzt man den Wert auf [NO], so sind nur noch Uploads möglich.
chown_uploads=YES # Upload Benutzerrechte automatisch ändern auf den ...
chown_username=Benutzername # ... User mit dem Namen ... (Der owner wird nur auf den angegebenen User geändert, wenn der Upload von einem anonymen User erfolgte).
max_per_ip=10 # Maximal zugelassene Anzahl von Nutzer von ein und derselben IP-Adresse (Standard:0 = unbegrenzt).
delete_failed_uploads=YES # löscht fehlerhaft abgeschlossene uploads.
delay_failed_login=10 # Pause in Sekunden nach einem fehlerhaften login (Standard:1).
Hilfe erhält man über:
man vsftpd.conf
15. OpenSSH-Server / SFTP-Server (SSH File Transfer Protocol) zugriff über SSH (Secure Shell):
Public Key Authentifizierung unter Debian und Ubuntu mit OpenSSH.
Benötigt man nicht einen FTPS sondern einen SFTP Zugang, so muss man einen SSH-Server installieren.
Mit dem SFTP Zugang klappt z. B. auch der Zugriff über den [Total Commander] wenn man das [Secure FTP]-Dateiplugin installiert hat.
| Grundkonfiguration: |
OpenSSH installieren:
apt-get install openssh-server
HostKey - Sicherheitshinweis:
Bei der Installation werden automatisch RSA-, DSA- sowie ECDSA-Keys und ggf. ein ED22219-Key erstellt. Diese Keys (Schlüsseldateien) liegen alle im Verzeichnis [ /etc/ssh/].
Jeder Schlüssel besteht hierbei aus zwei Dateien (private- & public-key).
All diese Schlüssel werden in der Regel mit maximal 2048-Bit erstellt.
Problematisch dabei ist das jeder einzelne Schlüssel einen Zugang zum Server ermöglicht!
Ist ein Schlüsselverfahren kompromittierbar (die NSA lässt grüßen), so ist der Server angreifbar.
Daher empfiehlt es sich hier alle vorhandenen Schlüsseldateien mit höherer Sicherheit neu zu erstellen (sofern möglich),
dabei sollte man für diese Schlüssel keine passphrase vergeben.
Hinweis: Eine ausführliche Parametererklärung finden Sie über diesen Link (auf dieser Seite weiter unten).
ssh-keygen -t rsa -b 8192 -o -f /etc/ssh/ssh_host_rsa_key # Mögliche Werte für -b 768 - 16384 (SSH Protocoll 2).
ssh-keygen -t dsa -b 1024
-o -f /etc/ssh/ssh_host_dsa_key # Nur 1024 Bit möglich (SSH Protokoll 2).
ssh-keygen -t ecdsa -b 521 -o -f /etc/ssh/ssh_host_ecdsa_key # Nur 256, 384 oder 521 Bit möglich (SSH Protokoll 2).
ssh-keygen -t ed25519 -b 256 -f /etc/ssh/ssh_host_ed25519_key # Aktuell nur 256 Bit möglich (wird schon so erstellt) (SSH Protokoll 2).
[ -o] ist nur möglich wenn openssh >= 6.5 vorhanden ist.
Noch besser ist es, wenn man sich nur für ein Verschlüsselungsverfahren entscheidet ( Empfohlen):
Man löscht also z. B. im Verzeichnis [ /etc/ssh/] die Schlüssel-Dateien (Keyfiles):
[ ssh_host_dsa_key] & [ ssh_host_dsa_key.pub],
[ ssh_host_ecdsa_key] & [ ssh_host_ecdsa_key.pub] und
[ ssh_host_ed25519_key] & [ ssh_host_ed25519_key.pub],
so das als einzige Anmeldemöglichkeit nur noch RSA, über die Schlüsseldatei:
[ ssh_host_rsa_key] & [ ssh_host_rsa_key.pub] übrig bleibt.
Vorsicht beim Löschen: Der Ordner enthält versteckte Dateien - diese nicht mit löschen!
Es darf also nur ein Schlüsselpaar für das gewünschte Verfahren übrig bleiben (RSA ist hier nur Beispielhaft aufgeführt - man kann auch ein anderes Verschlüsselungsverfahren auswählen).
Man zwingt also seinen Usern ein einzelnes (spezielles) Verfahren auf.
Das wiederum erhöht die Sicherheit, da es dadurch weniger Angriffsmöglichkeiten gibt.
Für das ausgewählte Verfahren sollte man wie oben vorgeschlagen einen neuen sicheren Key erzeugen.
ssh-keygen -t rsa -b 8192 -o -f /etc/ssh/ssh_host_rsa_key # Einen sicheren RSA-Host-Key erzeugen.
Hinweis:
Bei Updates, insbesondere bei größeren Versionssprüngen kann es passieren das die Keys automatisch neu erstellt werden.
Es empfiehlt sich daher eigene Keys separat zu sichern und diese nach einem Update ggf. manuell zurück zu spielen.
Verschlüsselungsstandards im Überblick:
[ dsa] (Digital Signature Algorithm) wurde von der NSA (National Security Agency) entwickelt und
1991 vom National Institute of Standards and Technology (NIST) empfohlen. Bei DSA können jedoch schwächen auftreten, wenn ein schwacher Zufallsgenerator verwendet wird.
ECDSA (Elliptic Curve Digital Signature Algorithm) ist eine Variante des DSA Algorithmus der Elliptische-Kurven-Kryptographie verwendet.
Mit erheblich kürzeren Schlüsseln erreicht das Verfahren ähnliche Sicherheit wie das RSA-Kryptosystem (ein Vergleich siehe Tabelle).
Dieses Verfahren ist schnell und bietet sich an wenn die Rechenzeit entscheidend ist. ECDSA wird noch nicht von jedem Client unterstützt.
Einige Kyrptoexperten vermuten, dass die von der US-Standardisierungsbehörde stammenden NIST-Kurven möglicherweise angreifbar sind, da die häufig verwendeten NIST-Kurven von einem NSA Mitarbeiter entwickelt wurden.
Das Ausgangsmaterial für die Kurven ist nicht dokumentiert und es werden Hintertüren durch schwache Kurven nicht ganz ausgeschlossen.
| Elliptic Curve Key Size |
RSA and Diffie-Hellman Key Size |
| 256 bits |
3072 bits |
| 384 bits |
7680 bits |
| 521 bits |
15360 bits |
[ Ed25519] Reduziert etwas das Risiko von Angriffen die durch schlechte Zufallsgeneratoren auftreten können (verhindert diese aber nicht 100%).
Der Algorithmus ist sehr schnell, er wurde für 64-Bit CPUs optimiert, die Schlüssellänge ist auf 256 bits begrenzt.
Ein 128 Bit Schlüssel entspricht etwa einem 3000 Bit RSA Schlüssel. Ed25519 wird noch nicht von jedem Client unterstützt.
[ RSA] Hat derzeit die meiste Verbreitung, daher würde ich derzeit zu RSA mit einem starken Schlüssel tendieren.
Allgemeine Links zum Nachlesen:
Wikipedia: Ed25519, Elliptic_Curve_Cryptography
Golem: OpenSSH rüstet auf,
Was noch sicher ist, die Herkunft der NIST-Kurven,
OpenSSH Key
NSA: Elliptische Kurven, [ 1]
Andere wichtige Parameter für ssh-keygen:
ssh-keygen -p -f Keydatei # Ändert die Passphrase von der angegebenen Keydatei.
Die Datei wird dabei nicht neu erzeugt, sondern es wird dabei nur die passphrase geändert.
ssh-keygen -A # Erzeugt alle Host-Keys komplett und ohne Rückfrage neu.
Bestehende HosKeys werden überschrieben. Den Befehl daher nur starten falls nichts mehr geht.
Hinweis:
Nach dem man den Server installiert hat ist der Zugriff sofort möglich.
SSH-Zugang in der Firewall (ufw) öffnen:
ufw allow 22/tcp
ufw enable
Will man sich später mit dem Server verbinden, so wird dann ein SSH Fingerprint angezeigt. Will man diesen auch überprüfen, so ist es wichtig dass man sich diesen Fingerprint zuvor natürlich anzeigt und notiert.
Folgender Befehl zeigt den SSH Server Fingerprint an:
ssh-keygen -lv -f /etc/ssh/ssh_host_rsa_key.pub
Man kann hier natürlich auch den Pfad zu eigenen erstellten Schlüsseln angeben. Dann erhält man den Fingerprint der selbst erstellten Schlüssel. |
| Wichtig! Brute-Force-Angriffe erschweren (faildelay einstellen): |
Um Brute-Force-Angriffe zu erschweren sollte man die Wartezeit zwischen einem fehlerhaften Login deutlich erhöhen.
Wörterbuchattacken sind dann durch die deutlich erhöhte Laufzeit für Angreifer nicht mehr sinnvoll durchführbar. Dies erhöht also die Sicherheit des Systems deutlich.
nano /etc/pam.d/sshd
# Hier am Anfang folgende Zeile einfügen:
auth optional pam_faildelay.so delay=20000000 # 20 Sekunden (20 Millionen Micro Sekunden/180 Passwortversuche je Stunde)
auth optional pam_faildelay.so delay=60000000 # 1 Minute (60 Millionen Micro Sekunden/60 Passwortversuche je Stunde)
# Die Zeit kann man je nach Sicherheitsanspruch natürlich individuell anpassen.
|
| root User Login verbieten & den Zugriff auf bestimmte Benutzer/Gruppen beschränken & Port einstellen: |
Standardmäßig kann sich auch der User [root] verbinden. Aus Sicherheitsgründen sollte man das verbieten.
Gleichzeitig kann man hier den Zugriff nur für einzelne Benutzer & Gruppen festlegen.
Hierzu bearbeitet man die Konfiguration vom openssh-server:
nano /etc/ssh/sshd_config
# Den vornandenen Eintrag ändert man wie folgt:
PermitRootLogin=NO # Verbietet das einloggen als root User.
# Fügt man AllowUsers hinzu, so wird das Login wird nur für die Benutzer erlaubt die man angegeben hat.
AllowUsers Benutzer1 Benutzer2
# Lässt man den Parameter AllowUsers weg, so können sich Standardmäßig alle Benutzer verbinden.
# AllowGroups erlaubt den Zugriff für Gruppen.
# Berechtigungen werden in folgender Reihe abgearbeitet:
# DenyUsers, AllowUsers und DenyGroups, AllowGroups
# Externer Zugriff von außen:
Port
22
# Optional: Wer mag kann auch den Port ändern.
# Ein geänderter Port kann Angriffe erschweren.
# Will man auf den SFTP/SSH-Server über das Internet
# zugreifen, so muss man im Router für diesen Port
# eine entsprechende Weiterleitung einrichten.
Hinweis:
Änderungen an der Konfiguration werden nur nach einem Neustart des Dienstes, bzw. dem neu einlesen der Konfiguration übernommen:
service ssh restart
service ssh reload |
| User in Verzeichnisse einsperren: |
Achtung: Standardmäßig erhält man Zugriff auf alles ab dem Wurzelverzeichnis [/]. Dies sollte man aus Sicherheitsgründen etwas einschränken.
Zuerst legt man eine Gruppe an die später alle User beherbergen soll:
addgroup grp_sftp_user
Anschließend fügt man den Benutzer hinzu:
useradd -g grp_sftp_user -s /bin/false usr_sftp_user
Der User erhält hierbei keinen Shell-Zugang (/bin/false).
Dem Benutzer vergibt man im Anschluss noch ein Passwort:
passwd usr_sftp_user
Danach muss man die Konfiguration vom openssh-server wie folgt anpassen:
nano /etc/ssh/sshd_config
# Den bereits vorhandenen Eintrag:
Subsystem sftp /usr/lib/openssh/sftp-server
# ändert man wie folgt ab:
Subsystem sftp internal-sftp
# und ganz am Ende der Datei fügt man folgendes hinzu:
Match Group grp_sftp_user
# Die folgenden Regeln gelten für alle Benutzer der Gruppe.
# Statt Group, kann man auch User für einen einzelnen User verwenden.
# Hier legt man dann den Pfad fest in welches Verzeichnis der User eingesperrt wird:
ChrootDirectory /home # Hier wird das root-Verzeichnis festgelegt.
# Wichtig: Die Verzeichnisberechtigung auf dem root-Verzeichnis darf maximal [chmod -R 755 Ordner] betragen.
# Ist die Berechtigung zu hoch (z. B. 777), dann kann man keine Client-Verbindungen mehr herstellen,
# meist treten dann am Client Fehler wie [Fehler: Konnte SFTP-Sitzung nicht initialisieren!] oder [Unable to startup channel] auf.
ForceCommand internal-sftp
AllowTCPForwarding no
X11Forwarding no # Grafischen Serverzugriff verbieten.
Hier im Beispiel hat der Benutzer mit dem Namen [usr_sftp_user] nur noch einen SFTP-Zugriff auf alle Dateien und Verzeichnisse (Dateirechte beachten)
die unter dem Verzeichnis [/home] liegen - eine lokale Anmeldung ist verboten [/bin/false].
Um die Änderungen zu übernehmen muss man den Dienst neu starten:
service ssh restart |
| Absicherung mit Schlüssel-Dateien durch Umstellung auf die SSH Public-Key-Authentifizierung: |
Nach der Umstellung auf die SSH Public-Key-Authentifizierung wird zur Anmeldung zwingend eine Schlüsseldatei benötigt. Eine einfache Anmeldung mit Benutzernamen & Passwort ist dann nicht mehr möglich.
Schlüssel erzeugen:
ssh-keygen -t rsa -C '[Kommentar]' -b 8192 -o -a 2048 -f id_rsa -Npassphrase
Parameterbeschreibung:
[-t] (type) Bestimmt den Verschlüsselungsstandard neben [rsa] existiert z. B. noch [dsa], [ecdsa], [ed25519]).
[-b] (bits) Legt die Anzahl der Bits fest, die zur Verschlüsselung verwendet werden (mind. 768, max. 16384 bei RSA, Standard meist 2048). Empfehlenswert ist hier eine deutliche Erhöhung, da diese die Sicherheit deutlich steigern.
Dauer die in etwa benötigt wird zum Erstellen der Keys (IntelCPU @ 3 GHz): bei 4096 Bits ~ 10 Sekunden, bei 8192 Bits ~ 30 Sekunden, bei 16384 Bits ~ 4 Minuten.
[-C] (comment) optional: Hier kann man ein extra Kommentar dem Schlüssel hinzufügen. Ich würde hier z. B. Datum, Kennzahlen o. ä. angeben.
Bei einer Vielzahl von Schlüsseln kann dies helfen den Überblick zu behalten. Hier nur nicht die Passphrase eingeben, denn der Kommentar wird im Klartext am Ende des Schlüssels gespeichert.
[-o] Den Schlüssel im neuen sicheren (SSH protocol 2) Format speichern (dies ist nur möglich wenn openssh >= 6.5 vorhanden ist).
Die Angabe ist nur beim Typ RSA notwendig da DSA, ECDSA sowie ED25519 automatisch im SSH Protokoll 2 Standard gespeichert werden.
[-a] Anzahl der [key derivation function] festlegen, höhere Werte erhöhen die Resistenz gegen Brute-Force-Angriffe - gleichzeitig steigt damit jedoch die Zeit,
bei der Passphrasen-Überprüfung (dies ist nur möglich wenn openssh >= 6.5 vorhanden ist).
Hinweis: Der Parameter macht daher nur Sinn wenn eine passphrase vergeben wird.
Dauer die in etwa benötigt wird für die Erstellung bzw. Überprüfung der passprase (IntelCPU @ 3 GHz):
bei 1024 ~ 10 Sekunden, bei 2048 ~ 19 Sekunden, bei 4096 ~ 38 Sekunden, bei 8192 ~ 77 Sekunden, bei 16384 ~ 152 Sekunden.
[-f] (file) Bestimmt den Ausgabepfad und den Dateinamen der Schlüssel - standardmäßig ist der Pfad [~/.ssh/id_rsa] (bei RSA) voreingestellt. Lässt man den Parameter komplett weg,
so wird bei der Erstellung der Standard-Pfad vorgeschlagen. Sollte der Pfad noch nicht vorhanden sein, so wird dieser dann automatisch erstellt. Die benötigten Berechtigungen werden dabei automatisch korrekt gesetzt.
[-N] (new passphrase) kann man verwenden wenn man die Passphrase gleich mit eingeben will. Lässt man den Parameter weg, so wird an der Kommandozeile danach gefragt.
Wichtig: Aus Sicherheitsgründen sollte man den Schlüssel mit einer Passphrase schützen, denn sollte der private Schlüssel von einem Angreifer gestohlen werden,
so müsste dieser zuerst noch das Passwort herausfinden um diesen zu nutzen. Dieses Passwort sollte gängigen Passwortstrategien entsprechen (man sollte es also nicht zu leicht wählen).
Als nächstes wechselt man in das [.ssh]-Verzeichnis wo die soeben erstellten Schlüssel abgelegt wurden.
cd .ssh/
Zum einen kann man hier eine .pem Datei erzeugen (wird z. B. für [Total Commander] benötigt (optional):
cp id_rsa id_rsa.pem
Will man die Schlüssel mit Putty verwenden, so sollte man diese noch in das Putty-Format konvertieren. Bei meinen Tests (2015-03-26) klappte das nur mit Schlüsseln im alten Format (ohne Parameter -o, -a).
Zuerst benötigt man die entsprechenden Tools:
apt-get install putty-tools
Danach erzeugt der Aufruf von:
puttygen id_rsa -o id_rsa.ppk
einen für Putty gültigen Key.
Wichtig:
Als nächstes sollte man zuerst die Schlüssel sichern (id_rsa & id_rsa.pub und ggf. id_rsa.pem &
id_rsa.ppk). Denn wenn man in den nachfolgenden Schritten einen Fehler macht, kann es passieren dass man sich vom Server selbst aussperrt.
Je nach verwendetem Client benötigt man unterschiedliche Dateien. Daher am besten einfach alle sichern. Die Schlüssel sollte man dabei nur über einen sicheren Kanal auf den Client kopieren.
Damit der Schlüssel beim Login ausgewertet wird, muss man ihn zum Schlüsselbund hinzufügen:
cat id_rsa.pub >> authorized_keys
Man sollte hier kein [cp] wie Copy verwenden, da man in der Datei mehrere verschiedene Schlüssel ablegen kann. Die Schlüsseldateien sind reine Textdateien.
Die Datei [~/.ssh/authorized_keys] enthält alle öffentlichen Schlüssel, der User die sich mit dem Server verbinden dürfen.
Als nächstes muss man noch folgende Änderungen vornehmen:
nano /etc/ssh/sshd_config
# Hier folgendes einstellen (vorhandene Werte entsprechend anpassen):
PubkeyAuthentication yes # Verwenden der Schlüsseldatei aktivieren.
PasswordAuthentication no # Setzt man hier [no], so kann man sich nur noch über eine Schlüsseldatei anmelden.
Lässt man hier [yes] so ist sowohl die Anmeldung über eine Schlüsseldatei, als auch über ein Kennwort möglich.
ChallengeResponseAuthentication no # Behebt ggf. Probleme, ist meist Standardmäßig so.
Um die Änderungen zu übernehmen muss man den Dienst neu starten:
service ssh restart
Wichtig: Zuletzt sollte man aufräumen:
Der private Schlüssel, der beim Erstellen mit erzeugt wurde gehört nicht auf den Server. Denn wird dieser von einem Angreifer vom Server gestohlen, so kann dieser Schlüssel zur Anmeldung verwendet werden.
Der privaten Schlüssel und die ggf. konvertierten sollte man daher alle löschen. Auf dem Server verbleibt somit im [.ssh]-Verzeichnis am Ende nur die einzelne Datei [authorized_keys].
Alle anderen Dateien im [.ssh]-Verzeichnis kann man nach dem man sie gesichert hat löschen.
rm ~/.ssh/id_*
Alternativen:
Man kann die Schlüssel natürlich auf jedem anderen System zuerst erstellen und dann entsprechend verteilen.
Unter Windows kann man zur Schlüsselerstellung z. B. Puttygen.exe verwenden. |
| ASCII-Banner (optional): |
Damit man den Server besser identifizieren kann, kann man ein Banner einbinden.
Dieses Banner wird dann z. B. bei Putty bei der Anmeldung angezeigt.
Zuerst muss man aktivieren das überhaupt ein Banner angezeigt wird:
nano /etc/ssh/sshd_config
Hier einfach den vorhanden Banner-Eintrag aktivieren (also das Rautezeichen [#] entfernen) und den vorhandenen Dateinamen etwas abändern (z. B. [.txt] anhängen).
Die voreingestellte Originaldatei [/etc/issue.net] sollte man möglichst nicht verändern, da diese bei einem Update mit aktualisiert wird (Änderungen würden verloren gehen).
Banner /etc/issue.net.txt
Anschließend kann man den Bannertext eingeben:
nano /etc/issue.net.txt
Hier dann einen beliebigen Text, bzw. eine beliebige ASCII-Grafik einfügen, wie z. B.:
________________________________________________________________________________
_____
|[KEY]! Disk erforderlich. .\_/.
| o. | --(@)--
!__!__! /.\
_ _ _
.:(:( _|_ ):):. __(=)__ __|=|__ ___|=|___
| (___R.__) [=__I._=] \__ P.__/
/\_/\ _, ________|_ (=) |=| |=|
(") <') /._.\ = = \ (=) |=| |=|
___.(_o_).___(_)>___/_/_\_\______\___\|/___(=)___\|/___|=|___\|/___|=|___\|/___
|___|___|___|___|___|#Hacker|___|___|___|___|___|___|___|___|___|___|___|___|__|
|_|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|____|
|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|_2021@cts_|
________________________________________________________________________________
oder z. B. so (kurze Version):
_ _ _
.:(:( _|_ ):):. __(=)__ __|=|__ ___|=|___
________|_ (___R.__) [___I.__] \__ P.__/
/._.\ = = \ (=) |=| |=|
___/_/_\_\______\____________________\|/___(=)___\|/___|=|___\|/___|=|___\|/____
|___|__#Hacker__|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|__|
|_|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|____|
|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|___|_2021@cts_|
Der Text sollte hierbei maximal 16 Zeilen je maximal 80 Zeichen betragen, damit Anmeldename und Passworteingabe noch mit angezeigt werden.
Des Weiterhin sollte man hier keine Serverangaben veröffentlichen die Hackangriffe vereinfachen.
Benutzernamen, OS Version, Serverzweck usw. sollte man hier also nicht veröffentlichen.
Die Änderungen an der [sshd_config] wird erst übernommen wenn man den Dienst neu lädt.
service ssh reload |
|
VisualHostKey auf Linux Clients anzeigen und Verbindungsaufbau mit Linux Client: |
Will man sich von einem Linux Client aus verbinden, so kann man sich vor dem einloggen auch zusätzlich den 'fingerprint' als 'randomart image' ausgeben lassen.
Hierzu muss man auf dem Client folgende Änderung vornehmen:
nano /etc/ssh/ssh_config
Hier ändert man dann den vorhandenen Eintrag wie folgt ab:
VisualHostKey yes
Ab sofort wird beim Verbindungsaufbau nicht nur der 'fingerprint' sondern auch zusätzlich das 'randomart image' ausgegeben.
Ein ggf. eingerichtetes Banner wird danach ebenso angezeigt.
Der Verbindungsaufbau vom Client erfolgt so:
ssh Benutzername_auf_dem_Server@servername_oder_IP-Adresse
Beispiel für eine 'fingerprint'- und 'randomart image'-Ausgabe beim Verbindungsaufbau:
Host key fingerprint is 1e:78:40:3c:df:cd:c3:bd:9d:2c:df:e7:3e:4a:94:3a
+---[RSA 8192]----+
| .. |
| .o |
| .o . + . |
| o. . = o |
| . S +.o.|
| o . o..o.|
| . E .o .|
| o oo|
| ..o=|
+-----------------+
Merke:
Der 'fingerprint' und das 'randomart image' wird nur ausgegeben wenn man es bei den Clients entsprechend aktiviert hat.
Putty unter Windows zeigt den 'fingerprint' nur einmalig beim ersten Verbindungsaufbau an (vertrauenswürdige Keys werden in der Registry gespeichert).
Das 'randomart image' zeigt Putty überhaupt nicht an.
Man kann also Serverseitig nicht erzwingen das 'fingerprint' bzw. 'randomart image' auf dem Client angezeigt werden.
Will man vor jeder Verbindung eine Anzeige erzwingen, so sollte also man ein Banner (siehe oben) verwenden.
|
Clientzugriff Varianten ein-/ausblenden:
Zugriffsmöglichkeiten für den Client gibt es viele. Ich möchte hier nur ein paar ausgewählte gängige vorstellen:
Zugriff mit Putty (MultiOS/Windows):
Terminal-/Consolen-Zugriff erhält man z. B. mit
Putty (Windows).
Zugriff mit dem Total-Commander (Windows):
Im [
Total Commander] muss man zuerst das [
SFTP Dateisystemerweiterungs-Plugin]
installieren, anschließend kann man über den Slash [
\] - also die Netzwerkumgebung] (
nicht über Netz/FTP-Verbinden gehen) das [
Secure FTP]-Plugin starten.
Hier kann man dann über
F7 eine neue Verbindung anlegen. Für die neue Verbindung wird dann ein Name abgefragt (beliebig wählbar).
In der Anschließenden Maske trägt man dann folgendes ein:
Verbinden mit ... : Server-IP-Adresse:22 oder
Domain:22 Die Port-Nummer muss man nur angeben, wenn man den Port geändert hat.
Benutzername: Name des anzumeldenden Users
Kennwort: Rumpelstilzchen oder passphrase
Hier kommt das Kennwort des Users rein, verwendet man dagegen eine passphrase dann wird diese hier eingetragen.
Öffentliche Schlüsseldatei (*.pub): Hier die ir_rsa.pub Datei auswählen.
Private Schlüsseldatei (*.pem): ir_rsa.pem Hier gehört die private ir_rsa Datei hin (diese muss zwingend die Endung .pem haben!)
Hinweis:
Verwendet man die Public-Key-Authentifizierung also einen Schlüssel mit einer passphrase, so muss man bei Kennwort statt dem Userkennwort die Passphrase eintragen.
Alternativ kann man auch in der Verbindungsmaske vom [
Secure FTP]-Plugin den Menüpunkt [
PuTTY-Agenten benutzen (Pageant)] anhaken (aktivieren).
Damit der PuttyAgent funktioniert sind folgende Schritte zu erledigen:
1. Die [
pageant.exe] herunterladen und starten.
2. Im Taskleisten Tray (unten rechts neben der Uhr) erscheint dann der [
Pageant (PuTTY authentication agent)]. Über diesen kann man jetzt die verschiedenen Schlüssel verwalten.
Alternativ kann man die Schlüssel auch durch folgenden Aufruf hinzufügen: [
pageant.exe /Pfad_zur_Schlüsseldatei/id_rsa.ppk].
Beim Hinzufügen egal ob über Tray oder Kommandozeile wird immer die passphrase des Schlüssels abgefragt. Diese wird auch nicht gespeichert.
Tipps:
Besteht über den Total Commander eine Verbindung so kann man über den Menüpunkt [
Dateien] > [
Dateiattribute ändern...] diese entsprechend ändern.
Weiterhin kann man wenn eine Verbindung besteht beliebige Konsolenbefehle (Shellbefehle im Terminal) eingeben (dabei aber bitte die entsprechenden User Berechtigungen beachten).
Eventuelle Ausgaben werden oben im Logfile angezeigt (dieses lässt sich durch einen Doppelklick vergrößern).
Zugriff mit FileZilla (Windows):
Zuerst muss man den Schlüssel hinzufügen, dieser wird im Putty-Format erwartet.
Im Menü auf [
Bearbeiten] > [
Einstellungen] klicken, hier dann
folgendes aufklappen [
Verbindung] > [
FTP] > [
SFTP] und [
Schlüsseldatei hinzufügen...] auswählen.
Wählt man eine nicht konvertierte [
id_rsa]-public-key-Datei aus, so wird angeboten diesen in ein Putty-Format zu konvertieren.
Man muss diese neu konvertierte Datei dann erst speichern und anschließend die konvertierte Datei auswählen.
Hat man eine bereits im Putty-Format [
id_rsa.ppk] vorliegende Datei, so wählt man diese einfach aus.
Anschließend kann man über Menü [
Datei] > [
Servermanager] eine neue SFTP-Verbindung anlegen.
In der Anschließenden Maske trägt man dann folgendes ein:
Server: Server-IP-Adresse oder Domain
Port: 22 Die Port-Nummer muss man nur angeben, wenn man den Port geändert hat.
Protokoll: SFTP - SSH File Transfer Protocol Entsprechend auswählen.
Benutzername: Name des anzumeldenden Users
Passwort: Abrakadabra
Netzwerk Dateiserver mit Papierkorb / LAN-Freigabe über Samba:
Samba kann Datei- und Druckerfreigaben im Netzwerk bereitstellen und als Domänencontroller arbeiten.
Samba installieren:
apt-get install samba libpam-smbpass
Parameterbeschreibung: Samba pflegt eine eigene User- und Passwortdatenbank. [libpam-smbpass] = synct ständig System- und Samba-Passworte (alle 90 Sekunden), sodass man diese nicht getrennt aktualisieren muss (empfohlen).
Damit 'libpam-smbpass' funktioniert und die User-Passworte in die Samba-Passwortdatenbank übernommen werden, muss man sich einmalig mit dem User der für Samba verwendet wird auf dem Linux PC an- und abmelden.
Bei Passwortänderungen des Samba Users muss man sich ebenso einmalig unter dem geänderten Usernamen am Linux Server an- und abmelden, damit die Passwortänderung in Samba aktualisiert wird.
Hinweis: 'libpam-smbpass' steht ab Ubuntu 16.04 leider nicht mehr zur Verfügung, die Synchronisation der User- und Samba-Datenbank muss man daher ab sofort eigenständig über 'smbpasswd' erledigen.
Man kann Samba das Passwort des Users auch so bekannt machen (nur nötig wenn man kein 'libpam-smbpass' verwendet):
smbpasswd -a Benutzername # den Benutzer der Samba Datenbank hinzufügen & das Samba Passwort abfragen (die Passwortabfrage erfolgt über die Standardeingabe).
smbpasswd -x Benutzername # den Benutzer aus der Samba Datenbank entfernen. Hinweis: Der Benutzer root lässt sich nicht löschen.
smbpasswd -e Benutzername # den Benutzer deaktivieren (eine Anmeldung ist dann nicht möglich). Zum sperren des Benutzers root geeignet.
smbpasswd -d Benutzername # den Benutzer aktivieren (eine Anmeldung ist dann wieder möglich).
Samba Benutzer automatisiert/direkt/Scriptgesteuert hinzufügen (2 Varianten):
echo -ne "Passwort\nPasswort\n" | smbpasswd -a -s Benutzername # Passwortübergabe mittels echo maskiert mit der Escape-Sequenz \n (newline) über die Standardeingabe.
(echo "Passwort"; echo "Passwort") | smbpasswd -a -s Benutzername # Passwortübergabe über doppeltes echo über die Standardeingabe.
Beachtet dabei, dass man das Passwort immer 2-mal angegeben muss (zur Bestätigung).
Weiterhin sollte man die Anführungszeichen wie gegeben mit übernehmen um Passworte mit Leerzeichen u. ä. zu berücksichtigen.
Parameterbeschreibung:
[-e] = (bei echo) Die Verarbeitung von Escape-Sequenzen mit Backslash \ aktivieren.
[-n] = (bei echo) Den nachfolgenden Zeilenumbruch nicht ausgeben.
[-s] = (silent/standard input - bei smbpasswd) Ausführung ohne Ausgaben. Passworte (neu/alt) werden von der Standardausgabe gelesen (zur Automatisierung).
Optional: Eine Freigabe über den Caja oder Natilus Dateimanager einrichten.
Nur bedingt empfohlen, da weniger Möglichkeiten:
apt install caja caja-share samba
# Den Dateimanager von Mate (ab Ubuntu 16.04 empfohlen) oder den
apt-get install nautilus nautilus-share samba
# Dateimanager von Gnome installieren.
nohup caja &
# Startet den Dateimanager direkt vom Terminal.
Ordner kann man dann im Caja/Nautilus Dateimanager mittels rechter Maustaste freigeben.
Man hat hier allerdings nur wenige Optionen (wie alle lesen, alle schreiben).
Der Zugriff lässt sich so also schlecht einschränken.
Braucht man aber nur schnell mal eine Freigabe, so ist dies durchaus eine Option.
Wichtig:
Man muss auch hier den Benutzer der Samba Datenbank hinzufügen:
smbpasswd -a Benutzername
Besser ist es die Freigabe wie folgt einzurichten:
Zuerst legt man einen Ordner an den man freigegeben will.
mkdir /srv/DATA
Anschließend muss man noch die Dateiberechtigungen auf Systemebene setzen:
chmod -R 777 /srv/DATA # Die Dateiberechtigung 777 (Vollzugriff für alle) rekursiv setzen.
Dann muss man die Freigabeberechtigungen für die User (darf ich lesen, durchsuchen, beschreiben, für welche Netze, ...) anpassen:
nano /etc/samba/smb.conf
Für die meisten Standardzwecke sollte folgende Konfiguration reichen (für Copy & Paste) (empfohlen):
# Folgende Zeilen am Anfang hinzufügen:
# Unter dem vorhandenen [global]-Eintrag kann man für alle Freigaben allgemeingültige Einträge festlegen.
## Freigabe Optionen: ##
[DATA$]
# Freigabename (mit [$] wird es eine versteckte Freigabe).
comment=Samba Freigabe Kommentar
# Kommentar zur Freigabe.
path=/srv/DATA
# Pfad zur Freigabe. Der Ordner muss bereits vorhanden sein.
writeable=yes
# Schreibrecht aktivieren.
valid users=%U
# Zugriff für alle User (auch root).
read list=Benutzername
# Folgende Benutzer haben nur Leserechte. Alternativ: Schreibzugriff nur für bestimmte Benutzer [write list=Benutzername] wenn man zuvor die Schreibrechte für alle deaktiviert hat.
hosts allow=192.
# Netzbereich 192.*.*.*
## Cache Optionen: ##
write cache size=262144
# Cacht Schreibzugriffe (hier 256k), dies kann den Durchsatz erhöhen.
## Optionale Datei und Verzeichnisrechte: ##
# create mode = 0640
# directory mode = 0750
## Papierkorb Optionen: ##
# Fügt man z. B. die die folgenden Papierkorboptionen unter dem vorhandenen [global]-Eintrag ein, so gelten diese für alle Freigaben.
vfs object=recycle
# Papierkorb Funktionalität aktivieren.
recycle:repository=.recycle/%U
# Für jeden User einen extra Papierkorb anlegen.
recycle:keeptree=yes
# Verzeichnisstruktur beim Löschen beibehalten.
recycle:exclude=*.tmp, .~lock*.*#, ~$*.*
# Folgende Dateien nicht im Papierkorb sichern: [*.tmp] = beliebige Temp-Dateien, [.~lock*.*#] = LibreOffice lock-Dateien, [~$*.*] = Microsoft Office lock-Dateien.
recycle:directory_mode=0750
# Recht setzen das andere Gruppenmitglieder den Papierkorb lesend durchsuchen können.
recycle:versions=yes
# Historische Versionen aufheben = gleiche Dateien (geänderte) werden fortlaufend durchnummeriert.
recycle:noversions=*.doc?, *.xls?, *.mdb, *.pdf
# Von diesen Datentypen keine historischen Daten speichern. Nur die letzte Version wird gesichert.
recycle:touch=yes
# Beim Löschen von Dateien wird das [Datum des letzten Zugriffs] auf das Löschdatum gesetzt.
hide files=/?esktop.ini/?humbs.db/
# Diese Dateien/Verzeichnisse erhalten das versteckt Attribut.
# veto files=/TypVerbieten/
# Verbietet das Anlegen von Dateien/Verzeichnissen.
Ausführliche Beschreibung ein-/ausblenden.
## Freigabe Optionen: ##
[
DATA$] # Das ist der Freigabename, dieser kann auch anders lauten als der Ordnername.
Ein [
$] am Ende erzeugt eine versteckte Freigabe.
comment = Freigabe-Beschreibung # Eine optionale Beschreibung der Freigabe.
browsable = yes # Kann man die Freigabe auch rekursiv durchsuchen (Standard=yes)?
path=/srv/DATA # Der Pfad zur Freigabe (die Datei-Berechtigungen auf Systemebene müssen gegeben sein!).
writeable = yes # Freigabe beschreibbar machen?
valid users = Benutzername, @grp_Lager, %U # Welche Benutzer dürfen die Freigabe nutzen?
@grp_Lager =
bedeutet alle User die Mitglied der Gruppe
Lager sind können die Freigabe nutzen. [
%U] (username) = alle lokal existierenden User einschließlich root.
hosts allow = 192.168. # Für welche Netzwerkbereiche soll die Freigabe erreichbar sein?
# Hier können alle User aus dem lokalen Netzwerk
192.168.*.* auf die Freigabe zugreifen.
## Papierkorb Optionen: ##
# Papierkorb aktivieren & Pfad einstellen:
vfs object = recycle # Gelöschte Dateien und Verzeichnisse werden in den festgelegten (versteckten) Ordner verschoben.
recycle:repository = .recycle/%U # Der Pfad zum Papierkorb ist relativ zur Freigabe [
.recyle]
= ist Standard, [
%U] = Username (wenn man für jeden User ein extra Papierkorb will).
# Ausnahmen & Berechtigungen für den Papierkorb festlegen:
recycle:keeptree = yes # Verzeichnisstruktur im Papierkorb mit sichern.
recycle:exclude = .~lock*.*#, ~$*.*, *.tmp # Vom Papierkorb ausgeschlossene Dateien z. B. Office-Temp-Dateien (LibreOffice/Microsoft Office). Diese werden nicht im Papierkorb gesichert.
recycle:exclude_dir = tmp, temp # Sofort zu löschende Verzeichnisse. Diese werden nicht im Papierkorb gesichert.
recycle:directory_mode = 0750 # Zugriffsrechte für das Papierkorbverzeichnis festlegen.
# [
0700] = Nur der User selbst hat Vollzugriff auf den Papierkorb (Standard).
# [
0750] = Der User hat Vollzugriff und alle Gruppenmitglieder können lesend auf den Papierkorb zugreifen.
recycle:maxsize = 0 # Festlegen bis zu welcher maximalen Dateigröße werden Dateien in den Papierkorb geschoben? Größere Dateien werden sofort gelöscht. Die Angabe erfolgt in Bytes (1073741824 Bytes = 1 GiB).
# Wie soll mit gleichen Dateien (geänderten Dateien) umgegangen werden:
recycle:versions = yes # Geänderte Versionen werden nicht gelöscht, sondern fortlaufend durchnummeriert (
Copy #x of Dateiname).
Auf ältere Versionen kann man hier also zugreifen.
recycle:noversions = *.doc?, *.xls?, *.mdb, *.pdf # bedeutet dabei das ältere Versionen von geänderten Dateien (die dem Filter entsprechen) nicht im Papierkorb gesichert werden.
# [
recylce:noversion] hat immer Vorrang vor [
recycle:versions].
# Das bedeutet wenn ein Wert für [
recycle:noversions] gesetzt wurde, so wird immer nur die zuletzt gelöschte Dateiversion erhalten. Alle anderen Vorversionen werden nicht im Papierkorb gesichert.
# Wird eine Datei gelöscht die nicht zu den Werten von [
recycle:noversions] passt, so gilt [
recycle:versions] und es wird eine durchnummerierte Historie der Datei angelegt.
# Korrekten Zeitstempel setzen, zur Vorbereitung auf die Löschung via Cron-Job:
recycle:touch = yes # Der Zeitstempel (
das Datum des letzten Zugriffs) wird bei der gelöschten Datei auf das aktuelle Datum gesetzt, wenn die Datei in den Papierkorb geschoben wird (empfohlen).
recycle:touch_mtime = yes # Der Zeitstempel (
das Datum der letzten Änderung) wird bei der gelöschten Datei auf das aktuelle Datum gesetzt,
wenn diese in den Papierkorb geschoben wird (weniger empfohlen).
# Diese Zeitstempel sind wichtig, um so später den Papierkorb zu bereinigen. Man kann dann z. B. nach dem '
letzten Zugriff' bzw. nach der '
letzten Änderung' suchen.
# User festlegen die den Papierkorb durchsuchen können:
write list = admin, root, @grp_trashcan
# Die angegebenen User bzw. die Mitglieder der angegebenen Gruppen können auch den Papierkorb von anderen Usern durchsuchen und bereinigen.
# Dies lockert also unter anderem die Berechtigung [
recycle:directory_mode = 0700] von oben.
# Verschiedene Dateien und Verzeichnisse für User verstecken:
hide files = /.recycle/?esktop.ini/?humbs.db/
# Einträge müssen immer zwingend mit einem Slash [
/] beginnen und enden.
# So kann man den Mülleimer und andere unwichtige Dateien für die User verstecken.
# Die Dateien erhalten dabei Transparent das hidden/versteckt-Attribut - ein Zugriff auf die Dateien ist also nach wie vor noch möglich.
# Verschiedene Dateitypen oder Namen verbieten:
veto files = /*.mpg/Müll/
# Verbietet das Anlegen von Dateien oder Verzeichnissen die dem Muster entsprechen. Einträge müssen immer zwingend mit einem Slash [
/] beginnen und enden.
delete veto files = yes # Die Option weist Samba an, veto-Dateien zu löschen, wenn ein User versucht, ein Verzeichnis zu löschen, in dem veto-Dateien enthalten sind.
# Das bedeutet, wenn ein User ein Verzeichnis zu löschen versucht, das eine veto-Datei enthält, dann wird die Datei (und das Verzeichnis) nicht gelöscht.
# Stattdessen wird das Verzeichnis bestehen bleiben und aus der Perspektive des Users leer erscheinen. Wird die Option auf yes gesetzt, werden Verzeichnis und veto-Dateien gelöscht. (Standard=no)
Benötigt man ein getrenntes Homedirectory für jeden User, so sollte man die vorbereiteten Einträge wie
[homes], [
netlogon], [
profiles] usw. beachten.
Windows Zugriffsprobleme ab Samba 4.5 beheben:
# Hat man noch ältere Windows Versionen wie z. B. Windows XP, Windows 2000 o. ä. im Einsatz, dann funktioniert der Zugriff auf die Samba-Freigaben Standardmäßig nicht mehr.
# Man erhält dann beim Versuch ein Netzlaufwerk zu verbinden [net use * \\hostname\share /user:test passwd] trotz korrekt eingegebener Zugangsdaten
# die folgende Fehlermeldung: [Systemfehler 1326 aufgetreten.] bzw. [Anmeldung fehlgeschlagen: unbekannter Benutzername oder falsches Kennwort.].
#
# Hintergrund ist, dass ab Samba Version 4.5 die unsichere NTLMv1-Authentifizierung standardmäßig deaktiviert wurde.
# Aus Sicherheitsgründen sollte man daher wenn möglich die betroffenen Client-Systeme aktualisieren, so dass diese die neuere NTLMv2-Authentifizierung unterstützen.
# Sollte dies nicht mehr möglich sein, wie z. B. bei Windows XP oder Windows 2000, so muss man die folgenden Einträge unter dem Abschnitt [global] hinzufügen:
[global]
lanman auth=yes
ntlm auth=yes
# Wichtig:
# Diese zwei Einträge muss man zwingend unter dem bereits vorhandenen Eintrag [global] hinzufügen.
# Man kann diese Einträge nicht bei einer Freigabe angeben.
# Aus Sicherheitsgründen sollte man diese Parameter nur angeben wenn man diese zwingend benötigt.
Um die Änderungen zu übernehmen, muss man den Dienst neu starten. Je nach verwendeter Samba Version sind die Befehle unterschiedlich:
service smbd restart
service samba restart
Samba Papierkorb automatisch bereinigen:
Der Ordner der als Papierkorb verwendet wird nicht automatisch gelehrt.
Entweder man bereinigt den Ordner manuell von Zeit zu Zeit.
Oder man richtet hierzu einen geplanten Task (Cron-Job) für die Bereinigung des Papierkorbs ein (die Anleitung dazu kommt gleich).
Für die Bereinigung sollte man am besten ein Script anlegen:
nano /adm/clean_recycle_on_network_share.sh
Neue korrigierte Version - Variante mit Zwischensicherung (für Copy & Paste) (empfohlen):
Hier folgendes einfügen:
#!/bin/bash
# Alle Dateien und Verzeichnisse suchen, bei denen das Zugriffsdatum älter als 7 Tage ist.
# Zutreffende werden in den Ordner '/srv/TEMP' außerhalb der Freigabe verschoben. In dem Ordner '/srv/TEMP' erhalten sie dann eine letzte Gnadenfrist.
# Der User hat dann erst mal keinen Zugriff mehr auf seine gelöschten Dateien und das Zugriffsdatum bleibt somit konstant.
# Der Administrator hat natürlich noch die Möglichkeit Dateien aus dem Ordner '/srv/TEMP' wieder herzustellen.
# Für den Administrator sollte man daher eine extra Freigabe auf '/srv/TEMP' einrichten.
#
Papierkorb in der Freigabe bereinigen:
#
Wichtig: Die folgenden Hochkommas ' und Anführungszeichen " muss man alle exakt übernehmen.
# Bei einem Fund werden die folgenden Befehle in einer separaten Shell (sh) ausgeführt (... -exec sh ' Shell-Befehle ').
find '/srv/DATA/.recycle/' -atime +7 -exec sh -c ' # Hier den Pfad anpassen.
file="{}"; # Den aktuellen Pfad & Dateinamen in der Variable file speichern.
# z. B.: [
/srv/DATA/.recycle/root/ORDNER1/TEST.txt]
# Beachtet dabei, .../root/... ist hier nur der Name vom Benutzer der über die Netzwerkfreigabe Dateien oder Verzeichnisse gelöscht hat. Der Username kann verschieden sein.
newcut_pathname=${file#/srv/DATA/.recycle/}; # Von dem gespeicherten Pfad wird hier der Pfad von der Freigabe bis zum Papierkorb entfernt (hier den Pfad anpassen).
# Die Variable newcut_pathname enthält dann nur noch den relativen Pfad zur Datei von der Freigabe aus gesehen.
# z. B.: [
root/ORDNER1/TEST.txt]
new_pathonly=$(dirname "${newcut_pathname}"); # Den Pfad ermitteln um das Zielverzeichnis anzulegen.
# new_pathonly enthält jetzt nur noch den neuen Pfad relativ zur Freigabe (also ohne Dateiname).
# z. B.: [
root/ORDNER1]
# mv legt keine Verzeichnisse an, daher werden diese sofern sie noch nicht vorhanden sind (! = Verneinung) vorab neu angelegt (hier drei Pfade anpassen).
# mv verschiebt nur die Dateien. Die vorher eingestellten User/Dateirechte werden beibehalten. Damit der Admin alle Dateien löschen kann wird das Verzeichnis mit Vollzugriff (777) angelegt.
# Beachtet dabei, dieser Vollzugriff wird durch die zusätzlichen Freigaberechte separat nochmalig begrenzt. Es hat in der Freigabe somit nicht jeder automatisch Vollzugriff.
if ! [ -d "/srv/TEMP/${new_pathonly}" ]; then;
mkdir -pv "/srv/TEMP/${new_pathonly}";
chmod -R 777 "/srv/TEMP/${new_pathonly}"; else echo "Pfad existiert bereits."; fi;
# Nun kann man die Datei aus dem Papierkorb der Freigabe in das Sicherungsverzeichnis verschieben (hier den Pfad anpassen).
mv -v "${file}" "/srv/TEMP/${newcut_pathname}";
' \; # Ende vom separaten Shell aufruf bzw. das Ende von find.
# Leere Verzeichnisse im freigabe Papierkorb löschen (hier den Pfad anpassen).
find '/srv/DATA/.recycle/' -mindepth 1 -type d -empty -delete;
# '-mindepth 1' = sorgt dafür, das der Papierkorb-Ordner '.recycle' selbst nicht gelöscht wird.
#
Zwischensicherungsverzeichnis endgültig bereinigen (hier den Pfad anpassen):
find '/srv/TEMP/' -type f -atime +60 -exec rm -v '{}' \; >/dev/null 2>&1
# Täglich um 12 Uhr, im Ordner '/srv/TEMP' nach Dateien suchen, bei denen das Zugriffsdatum älter als 60 Tage ist, gefundene werden gelöscht (hier den Pfad anpassen).
# Leere Verzeichnisse im Sicherungsverzeichnis löschen (hier den Pfad anpassen).
find '/srv/TEMP/' -mindepth 1 -type d -empty -print -delete; >/dev/null 2>&1
# '-mindepth 1' = sorgt dafür, das das Sicherungsverzeichnis 'recycle_temp' selbst nicht gelöscht wird.
#
Optional:
# cron leitet immer alle Ausgaben die an die Standardausgabe (stdout) gehen standardmäßig per E-Mail weiter - sodass man die Ausgabe dann dort in der E-Mail sieht.
# Der User 'root' würde bei dieser Konfiguration täglich 2 E-Mails erhalten.
# Fügt man der cron-Zeile den Anhang [
>/dev/null 2>&1] an, so werden nur Fehler (stderr) per E-Mail weitergeleitet - alle anderen fehlerlosen Ausgaben werden nicht mehr weitergeleitet.
#
# Tipp: Für Tests legt man am einfachsten mit
touch eine Datei mit einem alten Zeitstempel an oder man ändert kurzzeitig das Systemdatum mittels
date.
# Version: 2019-09-27
Das Script ausführbar machen:
chmod +x /adm/clean_recycle_on_network_share.sh
Das Script manuell ausführen (zum Testen):
/adm/clean_recycle_on_network_share.sh
Nun kann man den geplanten Task hinzufügen:
crontab -e
Hinweis: Es gibt getrennte crontab's für User und root.
Will man das Script als root starten, dann muss man crontab auch mit dem root-User einrichten.
Hier die folgende Zeile am Ende hinzufügen:
0 12 * * * /adm/clean_recycle_on_network_share.sh
# Die Bereinigung des Papierkorbs in der Netzwerkfreigabe startet hiermit täglich um 12 Uhr.
einfache Variante - Alternative ohne Zwischenspeicherung:
crontab -e
Hier fügt man einfach die folgenden Einträge direkt im crontab hinzu.
# Täglich um 12 Uhr, im Ordner '/srv/DATA/.recycle/' nach Dateien suchen, bei denen das Zugriffsdatum älter als 14 Tage ist, gefundene werden gelöscht (hier den Pfad anpassen).
0 12 * * * find '/srv/DATA/.recycle/' -type f -atime +14 -exec rm -v '{}' \; >/dev/null 2>&1
# Leere Verzeichnisse im freigabe Papierkorb löschen (hier den Pfad anpassen).
0 12 * * * find '/srv/DATA/.recycle/' -mindepth 1 -type d -empty -print -delete; >/dev/null 2>&1
# '-mindepth 1' = sorgt dafür, das der Papierkorb-Ordner '.recycle' selbst nicht gelöscht wird, '-print' = optionale Ausgabe.
# Optional:
# cron leitet immer alle Ausgaben die an die Standardausgabe (stdout) gehen standardmäßig per E-Mail weiter - sodass man die Ausgabe dann dort in der E-Mail sieht.
# Der User 'root' würde bei dieser Konfiguration täglich 2 E-Mails erhalten.
# Fügt man der cron-Zeile den Anhang [ >/dev/null 2>&1] an, so werden nur Fehler (stderr) per E-Mail weitergeleitet - alle anderen fehlerlosen Ausgaben werden nicht mehr weitergeleitet.
Weitere alternative Varianten ein-/ausblenden (weniger empfohlen):
# Hier werden täglich um 12 Uhr alle Dateien (ab dem angegebenen Verzeichnis) endgültig entfernt, wenn der letzte Zugriff auf diese Dateien älter als 15 Tage her ist.
0 12 * * *
find '/srv/DATA/.recycle/' -mindepth 1 -atime +15 -exec rm -rf '{}' \;
# Hat man mehrere Freigaben definiert, so werden diese alle mit dieser einen Zeile automatisch bereinigt. Die unterschiedlichen Farben dienen nur der besseren Lesbarkeit:
0 12 * * * for path in $(grep path /etc/samba/smb.conf |
cut -d= -f2 | sed -e '/^#/d' -e '/^ /d'); do
find ${path}/.recycle -mindepth 1 -atime +15 -exec rm -rf '{}' \;; done;
Parameterbeschreibung:
Über die for;, do;, done; - Schleife werden mit Hilfe von grep nacheinander alle Pfade aus der 'smb.conf'-Datei ausgelesen.
Diese Pfade werden mit Hilfe von cut und sed noch entsprechend Formatiert und in der Variable gespeichert.
Diese Variable wird nun an find übergeben. find sucht dann alle Dateien und Verzeichnisse auf die in den letzten 15 Tagen nicht mehr zugegriffen wurde.
Die gefundenen Dateien und Verzeichnisse werden im Anschluss entsprechenden mit rm gelöscht.
grep Parameterbeschreibung:
[grep path /etc/samba/smb.conf] gibt alle Zeilen aus die [path] enthalten.
cut Parameterbeschreibung:
[-d=] Beschreibt das Trennzeichen hier [=]. Die Zeilen werden am Trennzeichen in Spalten zerlegt.
[-f2] Bestimmt welcher Spaltenteil ausgegeben werden soll.
Hier im Beispiel soll alles nach dem ersten [=] Gleichheitszeichen ausgegeben werden.
Daher wird hier eine 2 wie 2. Spalte angegeben. Es wird dann also der Pfad ausgegeben.
sed Parameterbeschreibung:
[-e '/^#/d'] entfernt vorhandene Kommentarzeilen.
[-e '/^ /d'] entfernt führende Leerzeilen [ ].
Wichtig: Löscht man das Leerzeichen so muss der Pfad ohne Leerzeichen angegeben sein. Also z. B. so: [pfad=/srv/DATA] und nicht so [pfad = /srv/DATA].
Das Leerzeilen entfernen macht insbesondere daher Sinn, da so die vorhandenen Kommentarzeilen alle gelöscht werden.
-mindepth Parameterbeschreibung:
Setzt man [-mindepth 1] auf 1, dann beginnt die Suche beim Löschen erst nach dem 1. Unterverzeichnis. Es bleibt also das [.recycle]-Verzeichnis bestehen.
Setzt man [-mindepth 2] auf 2, dann bleiben auch eventuell vorhandene Userverzeichnisse bestehen.
[-atime] = (access time) sucht nach dem [Datum des letzten Zugriffs] (empfohlen).
Das [Datum des letzten Zugriffs] wird oben über den Parameter [recycle:touch] auf das Löschdatum gesetzt.
Beachten sollte man, dass ggf. eine Bildervorschau als neuer Zugriff gewertet werden kann. Durchsucht also eine Anwendung den Mülleimer, kann dies als neuer Zugriff gewertet werden. Dies kann dann das Löschen hinauszögern.
Tritt dieser Effekt häufiger auf kann man nur nach dem [Datum der letzten Änderung] suchen.
[-mtime] = (modification time) sucht nach dem [Datum der letzten Änderung] (weniger empfohlen).
Achtung: Liegt das Änderungsdatum weit zurück, sprich löscht man eine Datei die man vor längerer Zeit erstellt hat (z. B. vor den 15 Tagen),
so würde die Datei beim nächsten Lauf (also am nächsten Tag) sofort mit gelöscht (und nicht erst in 15 Tagen).
Da beim Löschen das Änderungsdatum der Datei ja nicht geändert wird und die Datei schon alt genug wäre (die Datei war ja schon mindestens 15 Tage alt).
Umgehen kann man das in dem man [recycle:touch_mtime = yes] aktiviert - hier wird beim Löschen das Änderungsdatum aktualisiert.
Da hier aber das Änderungsdatum der Datei geändert wird würde ich davon abraten, denn hier würde dann bei einem Restore der Datei das Datum der letzten Änderung nicht mehr stimmen.
# Zum Testen kann man folgendes Shell-Script verwenden:
#!/bin/sh
for path in $(grep path /etc/samba/smb.conf | cut -d= -f2 | sed -e '/^#/d' -e '/^ /d'); do echo ${path}; done; # für Debug Zwecke (Ausgabe der Papierkorbverzeichnisse).
for path in $(grep path /etc/samba/smb.conf | cut -d= -f2 | sed -e '/^#/d' -e '/^ /d'); do find ${path}/.recycle -mindepth 1 -atime +15; done;
# für Debugzwecke (Ausgabe der zu löschenden Daten).
Samba Firewall (ufw) Zugriff ermöglichen:
ufw allow 137/udp
ufw allow 138/udp
ufw allow 139/tcp
ufw allow 445/tcp
ufw enable
weitere Hilfe erhält man über:
man smb.conf
17. Apache2 Webserver mit PHP:
| Grundkonfiguration: |
mod_rewrite aktivieren (optional): |
Apache und PHP installieren:
apt-get install apache2 php5 libapache2-mod-php5 php5-gd (bis Ubuntu 15.10 mit PHP5)
apt-get install apache2 php libapache2-mod-php php-gd (ab Ubuntu 16.04 mit PHP7)
Die Pakete [php5-mysql] bzw. [php-mysql] (ab Ubuntu 16.04) und [mysql-server] muss man nur installieren wenn man eine Datenbank benötigt.
[php5-gd] bzw. [php-gd] = Richtet die Grafikbibliothek GDlib ein (diese wird oft benötigt, daher am besten gleich mit installieren).
[php-xml] ist optional, benötigt z. B. das myBB-Forum.
Das Wurzelverzeichnis-Verzeichnis (root-Verzeichnis) für den Apache2-Server befindet sich unter [/var/www/] bzw. unter [/var/www/html/] (neuere Versionen).
Um zu überprüfen ob die Installation geklappt hat, kann man folgende Testdatei verwenden:
nano /var/www/index.php
# Hier fügt man folgendes hinzu:
<?php phpinfo(); ?>
Ruft man die Datei nun im Webbrowser auf (IP-Adresse anpassen), sollte eine PHP-Versionsanzeige erscheinen:
http://192.168.2.1/index.php
Als root-User könnte man jetzt schon beliebigen Inhalt bereit stellen (aus Sicherheitsgründen sollte man dieses jedoch vermeiden).
Vorbereitungen User-Rechtevergabe für den Upload:
Der Apache Webserver reagiert oft sehr empfindlich wenn man direkt die Berechtigungen für den web-root-Ordner verändert (verschiedenste Zugriffsprobleme können dabei auftreten).
Standardmäßig sind für den Ordner [/var/www/html] folgende Berechtigung vergeben:
[drwxr-xr-x 2 root root 4096 Mär 29 09:06 html/] (diese sollte man so belassen).
Hat man diese Berechtigung verändert, so kann man diese wie folgt wieder herstellen:
[chmod -R 755 /var/www] und [chown -R root:root /var/www].
Will man nun die web-Daten nicht als root-User verwalten,
so sollte man den Inhalt am besten in einem extra Unterordner ablegen und
dort die Berechtigungen für einen separaten Benutzer entsprechend festlegen.
Man erzeugt also ein neues Unterverzeichnis:
mkdir /var/www/html/cms
Für dieses Verzeichnis vergibt man folgende Datei-Berechtigung:
chmod -R 755 /var/www/html/cms
Weiterhin ändert man die Besitzrechte auf den Benutzer der später den Inhalt pflegen soll.
Dieser Benutzer benötigt dann keine root-Rechte mehr um den web-Inhalt zu pflegen:
chown -R Benutzer /var/www/html/cms
Weiterhin fügt man den Benutzer zur bestehenden Gruppe [www-data] hinzu:
addgroup Benutzer www-data
Dies ist notwendig, damit man später den kompletten Zugriff auf alle Dateien hat, denn die von einer Webanwendung (z. B. CMS/Forum) erzeugten Dateien gehören immer der Gruppe [www-data] (Apache) an.
Hat man nur statischen Inhalt, so muss man den Benutzer nicht der Gruppe [www-data] hinzufügen.
Webanwendung wie CMS, Forum usw. installieren:
Jetzt kann man das CMS-System hochladen und den Installer starten.
Wenn dann der CMS-Installer nicht schreiben kann, so muss man die Dateiberechtigungen-Zugriffsrechte wie folgt anpassen:
chmod -R 777 /var/www/html/Ordner_oder_Dateien_die_Schreibrechte_benötigen
Hinweis:
Die Dateiberechtigung 777 bedeutet = Vollzugriff für alle.
Man sollte daher diese Rechte nur für die Dateien und Ordner vergeben, für die das CMS-System diese wirklich dringend benötigt.
Die Entsprechenden Ordner sollten in einer guten CMS-Dokumentation beschrieben sein, bzw. beim Installer angezeigt werden.
Sicherheit:
Um die Sicherheit zu erhöhen, sollte man die Schreibrechte von Dateien wieder entziehen, wenn diese nur einmalig beim Installieren benötigt werden.
Dies trifft z. B. häufig auf die [config.php]-Datei zu - hier werden z. B. meist einmalig Datenbankenpfade u. ä. gespeichert, die danach nicht mehr geändert werden.
Beispiel: [chmod -R 644 config.php] = Nur der Eigentümer darf lesen & schreiben, alle anderen dürfen nur lesen. |
Das Modul aktivieren:
a2enmod rewrite
Verzeichnis anlegen (meist schon vorhanden):
mkdir -p /var/run/apache2
Besitz-Berechtigung für den Ordner festlegen:
chown -R www-data /var/run/apache2
Die Module aktivieren:
a2enmod actions
Apache Patchen das [.htaccess] Dateien ausgewertet werden:
nano /etc/apache2/sites-enabled/000-default
nano /etc/apache2/apache2.conf # ab Apache 2.x
Hier in der Passage:
<Directory /var/www>
folgendes ändern:
AllowOverride None
in:
AllowOverride FileInfo
Hinweis:
Die Datei
[/etc/apache2/sites-enabled/000-default] ist hierbei in der Regel ein symbolischer Link auf
die Datei [../sites-available/default]. Welche Datei man editiert ist also egal.
Zuletzt noch den apache2 Server neu starten.
service apache2 restart
|
| Verzeichnisschutz für Verzeichnisse mit .htaccess und .htpasswd (optional): |
Die [.htpasswd]-Datei erzeugen:
htpasswd -c -B -C 13 /var/www/geschuetztes_Verzeichnis/.htpasswd Benutzername
Parameterbeschreibung:
[-c] = eine neue Datei anlegen (eine bestehende wird überschrieben), lässt man den Parameter weg - so wird eine weitere Berechtigung der Datei hinzugefügt (angehängt).
[-m] = MD5 Verschlüsselung (Standard).
[-s] = SHA Verschlüsselung (nicht mehr 100% sicher).
[-B] = bcrypt Verschlüsselung (sehr sicher).
[-C] = legt die Stärke der bcrpt Verschlüsselung fest (nur für bcrypt Verschlüsselung geeignet), es sind dabei die Werte 4 - 31 erlaubt (Standard = 5).
Hinweise:
Die bcrypt-Verschlüsselung mit höheren Werten verzögert deutlich das Login, auch die erste Berechnung der Keys kann bei hohen Werten sehr lange dauern. Die bycrpt-Verschlüsselung ist erst ab Debian 8 und neueren Ubuntu Versionen verfügbar.
Als nächstes erzeut man die [.htaccess]-Datei:
nano /var/www/geschuetztes_Verzeichnis/.htaccess
# Hier fügt man dann folgendes ein:
AuthName "Bitte geben sie ihre Zugangsdaten ein."
AuthType Basic
AuthUserFile /var/www/geschuetztes_Verzeichnis/.htpasswd
require valid-user
Beachtet dabei: Die [.htaccess]-Datei verweist auf die zuvor erstellte [.htpasswd]-Datei.
Damit die [.htpasswd]- und die [.htaccess]-Datei vom apache2 geparst wird muss man die Konfiguration vom apache2 Server anpassen:
nano /etc/apache2/sites-available/default
nano /etc/apache2/apache2.conf # ab Apache 2.x
Hier ändert man unter:
<Directory /var/www/>
Options Indexes FollowSymlinks MultiViews
AllowOverride None
in:
AllowOverride AuthConfig
Hinweis:
Die Datei [/etc/apache2/sites-enabled/000-default] ist hierbei in der Regel ein symbolischer Link auf
die Datei [../sites-available/default]. Welche Datei man editiert ist also egal.
Die geänderte Konfiguration im apache2 einlesen:
service apache2 reload
Hinweis:
Will man [mod_rewrite] und den [Verzeichnisschutz] gleichzeitig verwenden,
so trägt man in der Konfiguration einfach folgendes ein: [AllowOverride FileInfo AuthConfig] ein.
|
Absicherung wenn alles läuft (bei statischen Context) - Achtung dies entzieht komplett den Schreibzugriff (optional):
chmod -R a-w /var/www
Ändert die Dateiberechtigungen von [drwxr-xr-x] auf
[dr-xr-xr-x] - entzieht also die write/Schreibberechtigung.
Umkehren kann man das durch [chmod -R a+w /var/www].
18. Einen MySQL Datenbankserver Server einrichten & die Anbindung an PHP und Apache realisieren:
Eine MySQL-Datenbank benötigt man für verschiedenste Datenbankbasierende Webanwendungen wie z. B. CMS- und Foren-Systeme.
Port: 3306 ist der Standardport.
Original: MySQL Handbuch
Die benötigten MySQL Pakete installieren:
apt-get install mysql-server php5-mysql (bis Ubuntu 15.10 mit PHP5)
apt-get install mysql-server php-mysql (ab Ubuntu 16.04 mit PHP7)
Wichtig:
Aus Sicherheitsgründen wird hierbei ein Passwort für MySQL (MySQL-root-Passwort) für den für den Benutzer root abgefragt, dieses sollte man setzen.
Dieses Passwort sollte gängigen Passwortstrategien entsprechen, man sollte es also nicht zu leicht wählen.
Weiterhin sollte sich das Passwort vom root-User-Passwort unterscheiden, um Hackangriffe zu erschweren.
Rumpelhein1zchen
Die MySQL Installation absichern (u. a. Test- und Anonymous-Zugänge deaktivieren):
mysql_secure_installation
Als nächstes loggt man sich in MySQL ein:
mysql -uroot -pPasswort
Parameterbeschreibung:
[-u] = (user) unter welchem MySQL-User-Account (hier root) wird die Datenbank angelegt?
[-p] = (password) hier wird das MySQL-root-Passwort welches man zuvor vergeben hat eingegeben.
Achtung: Zwischen dem Parameter [-p] und dem vergebenen [Passwort] darf kein Leerzeichen stehen.
Hier kann man dann eine Datenbank erstellen und die Benutzer-Berechtigungen vergeben:
Als nächstes erstellt man eine neue Datenbank, dies geschieht mit folgendem MySQL-Befehl:
CREATE DATABASE Datenbankname;
Parameterbeschreibung:
[
create] = (erstellen), also neu erstellen.
[
database] = (Datenbank), es wird also eine neue Datenbank erstellt.
[
Datenbankname] = der Name ist beliebig frei wählbar (z. B. db, CMS, Forum, Projektname).
[
;] =
Wichtig: Das Semikolon schließt den MySQL Befehl immer ab, dieses also nicht vergessen.
Wenn man den Befehl mit der Eingabe bestätigt, so sollte eine Rückmeldung kommen wie:
[
Query Ok] = (Abfrage ok) = bedeutet der Befehl wurde erfolgreich ausgeführt.
Welcher User erhält das Recht Daten in der Datenbank hinzuzufügen und ein Passwort für die Datenbank festlegen:
GRANT ALL PRIVILEGES ON Datenbankname.* TO 'Benutzername'@'%' IDENTIFIED BY 'Datenbank-Passwort';
GRANT ALL PRIVILEGES ON db_name.* TO 'db_user'@'localhost' IDENTIFIED BY 'db_pass';
Parametererklärung und Hinweise:
[
Datenbankname] = ist hier im Beispiel der Name der Datenbank die man eben erstellt hat.
[
Benutzername] = ist ein neuer beliebiger Benutzername, dieser Benutzer erhält dann Zugriff auf die angegebene Datenbank.
[
@'%'] = erlaubt Zugriff von überall.
[
@'localhost'] = Achtung dies erlaubt den Zugriff nur lokal.
Gibt man nur localhost an, so kommen Fehler wie: [
Could not connect to the database. Verify that username and password ...] bzw.
[
Die Verbindung zur Datenbank konnte nicht hergestellt werden. Bitte prüfen Sie, ob der Benutzername und Kennwort ...].
Aus Sicherheitsgründen sollte der Datenbank-Benutzer auch kein lokales Konto auf dem PC besitzen. Hier also keinen lokalen User verwenden! Man sollte hier auch nicht den User root verwenden!
Falls nämlich ein Hacker die Zugangsdaten zur Datenbank hacken würde, so hätte er möglicherweise Zugriff auf das komplette System.
Man verwendet also für den Benutzernamen einen neuen Namen wie z. B. [
dbuser_Projektname].
Den neuen Benutzernamen sollte man aus Sicherheitsgründen nur für die Datenbank verwenden (also keinesfalls für andere Dienste verwenden).
[
Datenbank-Passwort] = ist das neu zu vergebende Datenbankpasswort (MySQL-db-Passwort).
[
;] =
Wichtig: Das Semikolon schließt den MySQL Befehl immer ab, dieses also nicht vergessen.
[
'] =
Wichtig: Die Hochkomma die den Usernamen, den Domainteil und das Passwort umgeben sollte man mit eingeben - teilweise werden die erwartet.
Im Anschluss sollte wieder eine Meldung kommen [
Query OK].
Ab sofort hat der Benutzer mit Hilfe des vergebenen Passworts Vollzugriff auf die Datenbank.
Hinweis: Die Datenbank ist jetzt sofort Einsatzbereit.
Man kann jetzt mit dem Testen der Verbindung beginnen, das Ausloggen kann man auch später noch erledigen.
Wenn alles läuft kann sich jetzt aus dem MySQL ausloggen. Alternativ kann man auch die Kurzform [
\q] verwenden.
QUIT
Wichtiger Sicherheitshinweis (debian.cnf sichern):
Unter Ubuntu und Debian wird noch ein zweiter MySQL-Benutzer mit dem Namen [debian-sys-maint] angelegt. Dieser ist für verschiedenste Wartungsaufgaben zuständig.
Für diesen User wird in der Datei [/etc/mysql/debian.cnf] das Passwort im Klartext gespeichert. Mit diesem User kann man das root-MYSQL-Passwort zurücksetzen.
Man erhält also über diesen User wieder Vollzugriff auf die Datenbank wenn man mal das Kennwort für MySQL vergessen hat.
Diese Datei sollte man sich daher sichern, da es ggf. passieren kann, dass die Datei [/etc/mysql/debian.cnf] bei einem Upgrade vom mysql-server Paket mit ausgetauscht wird.
cp /etc/mysql/debian.cnf /etc/mysql/debian.cnf.mein-backup
Datenbank-Verwaltung über den Adminer:
Adminer ist eine PHP-Weboberfläche
(ähnelt
phpMyAdmin) mit der man verschiedenste Datenbankaufgaben durchführen kann. Adminer benötigt einen apache2-Webserver.
Verzeichnis für Adminer anlegen:
mkdir /var/www/html/adminer
In das Verzeichnis wechseln:
cd /var/www/html/adminer
Adminer herunter laden (die aktuelle Version findet man immer hier
www.adminer.org/#download):
wget -O adminer.php adminer.org/latest-mysql-de.php = Der Link verweist immer auf die aktuellste Version.
Adminer benötigt folgende Pakete:
apt-get install libpq5 php5-pgsql php5-sqlite = diese Pakete muss man noch nachinstallieren (bis Ubuntu 15.10).
apt-get install php-mysql = folgendes nachinstallieren (ab Ubuntu 16.04 mit PHP7).
apt-get install libapache2-mod-php5 php5-mysql php5-cli = diese Pakete sind meist schon vorhanden.
Apache muss man nun neu starten:
service apache2 reload
Den Adminer kann man dann über einen Webbrowser wie folgt aufrufen:
http://IP-Adresse_oder_localhost/adminer/adminer.php
Das Design vom Adminer kann man mit css-Design anpassen, hierzu legt man im Ordner eine adminer.css Datei an.
Es gibt auf der Homepage mehrere Beispieldateien.
Alle angelegte Datenbanken auflisten:
mysqlshow -pPasswort # Hier muss man das MySQL-root-Passwort angeben.
[information_schema], [mysql] und [performance_schema] sind schon Standardmäßig angelegt.
Hier noch ein paar wichtige SQL-Befehle:
SHOW DATABASES; = alle vorhandenen Datenbanken anzeigen.
SHOW TABLES FROM db_name; = gespeicherte Tabellen der angegebenen Datenbank anzeigen.
USE db_name; = Will man SQL-Befehle innerhalb einer Datenbank ausführen (wie z. B. Tabellen anlegen), so muss man die gewünschte Datenbank zuvor auswählen.
DROP DATABASE db_name; = Datenbank löschen.
Die MySQL-Datenbank sichern:
mysqldump -u root -pPasswort --all-databases > Sicherung.sql # Sichert alle Datenbanken.
mysqldump -u root -pPasswort --all-databases
--ignore-table mysql.events > Sicherung.sql
# Sichert alle Datenbanken & verhindert den Fehler [-- Warning: Skipping the data of table mysql.event. Specify the --events option explicitly.]
mysqldump -u root -pPasswort Projekt > Sicherung_Projekt_Datenbank.sql
# Sichert nur die eine angegebene Datenbank z. B. Projekt.
[Passwort] = ist immer das oben angegebene MySQL-root-Passwort.
Die MySQL-Datenbank wieder herstellen:
mysql -u root -pPasswort < Sicherung.sql # Stellt alle gesicherten Datenbanken wieder her.
mysql -u root -pPasswort Projekt < Sicherung_Projekt_Datenbank.sql
# Stellt nur die gesicherte Datenbank (z. B. Projekt) wieder her.
Sollte man die Datenbank auf einem anderen System wieder herstellen, so sollte man unbedingt noch ein flush privileges durchführen (die Berechtigungen neu setzen):
mysqladmin -u root -pPasswort flush-privileges
[Passwort] = ist immer das oben angegebene MySQL-root-Passwort.
Den Datenbankzugang für das Netzwerk öffnen:
Die folgenden Schritte sind nur nötig wenn man direkt über den Port 3306 (sofern geändert anpassen) vom Netzwerk aus auf die Datenbank zugreifen möchte.
Für Web-Foren, CMS Systeme oder vergleichbare Web-Anwendungen - also Webdienste die in der Regel nur über Port 80 erreichbar sind - ist dieser Block irrelevant.
Zunächst ist der Zugriff auf die MySQL-Datenbank nur auf den localhost (also den lokalen PC) beschränkt.
Will man auch aus dem Netzwerk auf die MySQL-Datenbank zugreifen so muss man die Konfigurationsdatei von MySQL anpassen.
Die Konfigurationsdatei öffnen:
nano /etc/mysql/my.cnf &
# Hier den bereits vorhandenen Wert entsprechend ändern (nur eine Variante auswählen):
bind-address = 0.0.0.0 # Zugriff von überall zulassen. Man kann den Eintrag auch einfach auskommentieren [#] davor setzen.
bind-address = 192.168.0.0 # Zugriff nur aus dem lokalen Netz (192.168.*) erlauben.
bind-address = 192.168.2.100 # Nur der Computer mit der IP-Adresse 192.168.2.100 hat auf die SQL-Datenbank Zugriff.
# Hinweis: Hat man bei bind-address etwas Falsches eingetragen so startet MySQL gar nicht mehr. Es kommt dann immer der Fehler [[FAIL] Starting MySQL database server: mysqld . . . . . . . . . . . . . . failed!].
Hinweis: Änderungen an der MySQL Konfiguration werden erst nach einem neu einlesen der Konfiguration, bzw. nach einem Neustart des mysql-Dienstes übernommen.
service mysql reload
service mysql restart # Achtung, dies trennt bereits bestehende Verbindungen!
service mysql status # Anzeige ob der Dienst läuft oder nicht.
MySQL-root-Passwort zurücksetzen (nur nötig, wenn man das MySQL-root-Passwort vergessen hat/optional):
1. Als User [
debian-sys-maint] an MySQL anmelden:
mysql -u debian-sys-maint -p
2. Das Kennwort zurücksetzen:
update mysql.user set Password=password('neues-Passwort') where User='root';
flush privileges;
quit;
verschiedene Problemlöser:
netstat -ln | grep mysql # Prüfen ob MySQL hört.
eventuell zusätzlich benötigte Pakete [Imagic] z. B. fürs phpBB3 Forum:
apt-get install php5-imagick graphicsmagick-imagemagick-compat
19. Transparenter Bildschirmschoner unter Linux:
Zuerst installiert man folgende Pakete:
apt-get install xtrlock xautolock libnotify-bin xfce4-notifyd notify-osd
Parameterbeschreibung:
[xtrlock] = Sperrt nach dem Start das System, danach sind keinerlei Maus- oder Tastatureingaben mehr möglich.
Das Icon des Mauszeigers verwandelt sich dabei in ein blaues Schloss. Das Schloss-Icon kann man nicht ohne weiteres ändern, da es mit einkompiliert wurde.
Den Befehl 'xtrlock' kann man auch einfach so im Terminal eingeben - danach ist die Sperre sofort aktiv. Wichtig: Zum entsperren des Systems
kommt keine Eingabeaufforderung. Man muss hier einfach blind das Passwort des Users eingeben der das System gesperrt hat. Danach wird das System wieder freigegeben.
[xautolock] = Sorgt dafür das nach einer festlegbaren Leerlauf-Wartezeit ein beliebiger Befehl (Parameter '-locker') gestartet wird.
Man kann hier z. B. einen beliebigen Sperrdienst angeben z. B. eben 'xtrlock' zum Bildschirmsperren.
Vor dem ausführen des locker-Befehls (also vor dem Sperren) kann xautolock noch zusätzlich einen anderen Befehl starten (Parameter '-notifier').
Über diesen Info-Befehl kann man z. B. den User über die anstehende Systemsperre informieren. Dieser kann dann durch Mauswackeln oder durch eine beliebige Tasteneingabe die anstehende Sperre neu verzögern.
[notify-send] = Kann dem User Meldungen darstellen, in der Regel werden diese wie alle anderen Systemmeldungen über Sprechblasen angezeigt.
Je nach System können diese Benachrichtigungsdienste anders heißen.
notify-send benötigt unter Debian/Ubuntu die Pakete [libnotify-bin xfce4-notifyd notify-osd] für die Darstellung der Sprechblasen.
notify-send hat leider einen kleinen Bug, der Parameter -t wird ignoriert. Benachrichtigungen werden immer Systemweit etwa 10 Sekunden lang angezeigt. Die Anzeigedauer der Systemmeldung kann man also nicht verlängern oder verkürzen.
Für den automatischen Bildschirmschonerstart, legt man nun ein Shell-Script an:
mousepad autolock.sh
In der Datei fügt man folgendes hinzu:
#!/bin/bash
xautolock -notify 60 -notifier 'notify-send -i info "Achtung:" "Autolock in 60 Sekunden."' -time 5 -locker 'xtrlock'
Hinweis: Die verschiedenen Anführungszeichen & Hochkomma dienen der Befehlstrennung, diese muss man 1:1 übernehmen.
Die Wartezeit bis zum Sperren beträgt in dem Beispiel 5 Minuten,
60 Sekunden vorher (also nach 4 Minuten) wird die Warnmeldung auf die bevorstehende Sperre ausgegeben.
Als nächstes muss man das Script ausführbar machen:
chmod +x autolock.sh
Das Shell-Script muss man jetzt nur noch in den Autostart einbinden.
Wichtig: Dem Aufruf sollte man noch ein '&' anhängen, so dass der Prozess im Hintergrund gestartet wird.
Also entweder:
./autolock.sh & # Für den Direktaufruf oder
/Pfad_zum_Script/autolock.sh & # für die Einbindung beim Autostart.
Die Ausführung als root ist nicht nötig.
Hinweis: Startet man das Shell-Scrip bzw. xtrlock als root-User, so ist zum entsperren auch das root-User-Passwort nötig.
Weitere Infos hier:
wiki.ubuntuusers.de/Benachrichtigungsdienst
20. GRUB 2 anpassen (Consolenauflösung und Grub-Splash-Screen anpassen) & Kernel Parameter festlegen:
Die GRUB 2 Konfigurationsdatei findet man unter:
nano /etc/default/grub
Hier kann man verschiedene Einstellungen anpassen.
Um die möglichst größte Kompatibilität sicher zu stellen sollte man nur Einstellungen ändern die wirklich wichtig sind.
GRUB_DEFAULT=0
Legt fest welcher Eintrag gestartet werden soll.
Trägt man hier statt '
0' = '
saved' ein, so wird immer der zuletzt ausgewählte Eintrag gestartet.
GRUB_TIMEOUT_STYLE=hidden
Ist der Wert auf 'hidden' gesetzt, so wird direkt durchgestartet. Eine ggf. vorhandene Timeout Angabe wird ignoriert.
Ist der Wert auf 'menu' gesetzt, so wird das typische GRUB2 Menü angezeigt(empfohlen).
Ist der wert auf 'countdown' gesetzt, so wird nur der Countdown angezeigt.
GRUB_TIMEOUT=20
Legt die Wartezeit in Sekunden fest, die gewartet wird
bevor automatisch der unter '
GRUB_DEFAULT' festgelegte Eintrag gestartet wird.
Ist der Wert =
0, so wird direkt durchgestartet (nicht empfohlen).
Ist der Wert =
-1, so wird gewartet bis ein Eintrag manuell ausgewählt wird (kein Autologin mehr).
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
Legt fest, dass nahezu alle Meldungen ausgeblendet werden.
Steht hier "
quiet splash" oder nur "
splash" so wird ein Boot-Splashscreen angezeigt sofern einer eingerichtet ist.
Ist der Wert leer "" so werden alle Meldungen beim Start ausgegeben (ggf. hilfreich bei der Fehlersuche).
GRUB_CMD_LINUX="vga=0x0314 acpi=force"
Hier werden Kernel-Bootparameter übergeben. Unter anderem legt man hier z. B. die Consolenauflösung fest.
Sollten schon Einträge drin stehen, so wird der Parameter angehängt (als Trennzeichen zwischen den Parametern wird ein Leerzeichen verwendet).
Hinweis: Splashscreens funktionieren nur mit 16-bit.
Hier eine Tabelle mit den Kernel-Mode-Nummern für den '
vga=' Boot-Parameter:
\Auflösung
Farbtiefe\ |
640x400 |
640x480 |
800x600 |
1024x768 |
1152x864 |
1280x1024 |
1400x1050 |
1600x1200 |
| 4-bit |
|
|
0x0302 |
|
|
|
|
|
| 8-bit |
0x0300 |
0x0301 |
0x0303 |
0x0305 |
0x0161 |
0x0307 |
|
0x031C |
| 15-bit |
|
0x0310 |
0x0313 |
0x0316 |
0x0162 |
0x0319 |
0x0340 |
0x031D |
| 16-bit |
|
0x0311 |
0x0314 |
0x0317 |
0x0163 |
0x031A |
0x0341 |
0x031E |
| 24-bit |
|
0x0312 |
0x0315 |
0x0318 |
|
0x031B |
0x0342 |
0x031F |
| 32-bit |
|
|
|
|
0x0164 |
|
|
|
Beachtet dabei: Abhängig vom verwendeten System können die Werte manchmal leicht variieren. Aktuelle Infos zeigt hwinfo an siehe
Tipp.
Sonderformate:
vga=normal (entspricht dem Standard 80x25 Zeilen - kann man auch einfach weglassen.)
vga=ext (entspricht 80x50 Zeilen - scheint nicht mehr zu klappen.)
vga=ask (Nachfragen - wird nicht mehr unterstützt.)
acpi=force für alte Computer die ständig in den Stromsparmodus gehen, sich also
ständig schlafen legen, ständig den Bildschirm abschalten,
ja teilweise selbst schon beim Starten von der Live-CD/DVDs hängen bleiben haben möglicherweise ein zu altes Bios. Meist ist bei diesen PCs das Bios-Datum aus dem Jahr 1999 oder älter.
Der Grund das Linux nicht richtig startet/arbeitet liegt daran, dass es nicht den ACPI-Modus verwendet da das Bios zu alt ist. Sondern den APM-Modus versucht der aber immer mal nicht richtig implementiert wurde.
Lösen kann man dies in dem man den Kernel den Parameter [
acpi=force] übergibt, so erzwingt man die Verwendung des ACPI-Modus. Das ständige schlafen legen und hängen bleiben tritt dann nicht mehr auf.
Alternativ würde auch ein aktuelles Bios helfen, welches man für die meiste alten PCs nicht mehr bekommen dürfte.
Startet man von einem Live-Medium, so kann man den Parameter übrigens vor dem Start übergeben (
F6/
Tabulator).
forcepae erzwingt die Nutzung eines Kernels (nur nötig bei älteren CPUs wie z. B. einigen Pentium M's die kein PAE unterstützen).
#GRUB_TERMINAL=console
Aktiviert man den Eintrag (in dem man das # am Zeilenanfang entfernt), so wird im reinen Textmodus gestartet.
Es wird dann kein Hintergrundbild mehr angezeigt.
#GRUB_GFXMODE=800x600
Legt fest in welcher Auflösung das GRUB 2 Hintergrundbild vorliegt (den Eintrag muss man ggf. erst aktivieren/hinzufügen).
Standardmäßig ist hier entweder 640x480 oder 800x600 eingestellt.
Will man ein Bild in der Standardauflösung verwenden, so muss man den Eintrag nicht verändern.
Tipp:
Verfügbare Auflösungen kann man sich z. B. über den Befehl [
hwinfo --framebuffer] anzeigen lassen [
apt-get install hwinfo].
Will man das GRUB 2 Hintergrundbild ändern, so muss man nur ein Bild im PNG-Format in der entsprechenden Auflösung im folgenden Ordner speichern:
/boot/grub/mein_grub_bild.png
Der Bildname ist frei Wählbar. Es wird immer nur das zuerst gefundene Bild (nach dem Alphabet) angezeigt.
Man sollte in dem Ordner also möglichst nur ein Bild ablegen um Verwechslungen zu vermeiden.
Beachtet weiterhin, das Bild muss mindestens eine 8-Bit Farbtiefe aufweisen. Wenn man ein Bild mit wenigen Farben verwendet und dieses Bild mit zopfli u. ä. optimiert, dann wird das Bild möglicherweise nicht korrekt angezeigt, da zopfli ggf. die Bit-Tiefe ändert (verwendet zum optimieren advpng).
GRUB 2-Beispielbild (Darstellung verkleinert):
wget -O /boot/grub/support.png https://ctaas.de/images/support.png
Wichtig: Um die Änderungen zu übernehmen muss man den grub-Bootloader neu schreiben:
update-grub
GRUB 1 Consolenauflösung ändern (historische alte Systeme):
sudo gedit /boot/grub/menu.lst
Hier zu dem Kernel scrollen den man bearbeiten will und in der Zeile, die mit 'kernel' anfängt, das 'vga=0x314' am Ende hinzufügen.
Beispiel: kernel /boot/vmlinuz-2.6.17-10-386 root=UUID=100b704a-2065-49c5-81be-1b4b42362a24 ro vga=0x317
21. Ubuntu auf eine neue Version aktualisieren (Upgrade):
Die Anleitung ist für alle Ubuntu basierenden Distributionen gültig (sowohl Server- als auch Desktop-Systeme).
Die Dokumentation wurde vom Release/Version 10.04 bis zum aktuellen Release/Version 18.10 getestet.
Hinweise vorab:
Vor einem Upgrade sollte man eine Datensicherung durchführen.
Programme aus inoffiziellen Quellen und selbst nachinstallierte Treiber können beim updaten Probleme verursachen.
Des Weiteren wird Software die man ohne Paketquellen installiert hat nicht vom Update-Manager erkannt und berücksichtigt.
Eine Lösungsmöglichkeit wäre daher, derartige 'Fremdprogramme' und 'Treiber' vor dem Update zu deinstallieren und nach dem Upgrade wieder neu zu installieren.
Auch sollte man beachten, das eine neue Version die derzeit verwendete Hardware möglicherweise nicht mehr korrekt unterstützt,
da evtl. die Treiber zu Unterstützung von älterer Hardware (von der Linux-Kernel Unterstützung) entfernt wurden.
Um sicher zu gehen sollte man die Kompatibilität vorher testen (beispielsweise von einem Live-System aus).
Führt man ein Upgrade über eine Remoteverbindung z. B. via SSH durch, so kann es passieren dass die Verbindung beim Aktualisieren unterbrochen wird.
Von den wichtigsten Konfigurationsdateien sollte man eine extra Sicherung anlegen (empfohlen).
Updates über die grafische Oberfläche (Aktualisierungsverwaltung):
Als erstes muss man prüfen ob die 'Aktualisierungsverwaltung' schon installiert ist:
apt-get install update-manager
Anschließend startet man die [Aktualisierungsverwaltung] einfach über das Startmenü, oder über:
update-manager & # um auf die nächste Version zu aktualisieren.
update-manager -d # die devel-release/Entwickler-Version ermöglicht schon vor dem offiziellen erscheinen den Wechsel
auf die nächste Version.
Wichtig: Das Terminal nicht schließen so lange das Update läuft.
Hinweise zum devel-release (Entwickler-Version):
Entwickler-Versionen verändern sich meist häufig. Fehler sind daher nicht auszuschließen und man sollte diese daher nicht auf produktiven Systemen einsetzen.
Je nach Entwicklungsstand kann die Version eine Alpha, Beta bzw. Relase-Candidat Version sein.
Aktualisiert man die devel-release Version regelmäßig, so wird diese automatisch auf die nächste finale Version aktualisiert (alle Einstellungen und installierte Programme bleiben bestehen).
Will man auf die devel-release Version wechseln, so muss die zuletzt verfügbare Version bereits installiert sein.
Hier sollte man zunächst die normalen Updates einspielen. Anschließend kann man
über den Menüpunkt [Einstellungen],
den Karteireiter [Aktualisierungen],
den Auswahldialog [Über neue Ubuntu-Versionen benachrichtigen:],
festlegen nach welchen Aktualisierungen gesucht werden soll.
Update über die Console (für Server ohne GUI & für Desktops mit GUI gleichermaßen geeignet):
Vor dem 'Upgrade' auf eine neue Version sollte man das System auf dem neusten Stand aktualisieren, um Problemen aus dem Weg zu gehen.
Man installiert daher erst mal alle Updates bis das System aktuell ist:
apt-get update # Die Paketquellen aktualisieren (Update-Informationen einlesen).
apt-get upgrade -y # Programm-Pakete auf neue Version aktualisieren (kann man überspringen).
apt-get dist-upgrade -y # Programm-Pakete auf neue Version aktualisieren (installiert und entfernt ggf. neue Pakete). Das ist noch kein System-Upgrade auf eine neue Version.
apt-get autoclean -y # löscht nicht mehr benötigte Pakete (Platz schaffen fürs Upgrade).
apt-get autoremove -y # löscht nicht mehr benötigte Pakete und Kernel-Versionen (Platz schaffen fürs Upgrade).
apt-get clean -y # löscht alle heruntergeladene Pakete (weniger empfohlen).
Als nächstes muss man ggf. den Update-Manager installieren (meistens ist dieser schon vorhanden):
apt-get install update-manager-core
Anschließend legt man fest ob man nur auf LTS-Versionen (Long Term Support) oder auf jede neue Version aktualisieren möchte:
nano /etc/update-manager/release-upgrades
Hier den vorhandenen Wert entsprechend ändern:
Prompt=normal
Parameterbeschreibung:
never = (niemals) deaktiviert die Aktualisierungen komplett.
normal = jede neue Distribution wird angezeigt (... 16.04, 16.10, 17.04, 17.10, 18.04, 18.10 usw.).
lts = nur LTS-Versionen werden angezeigt (aktualisiert: 10.04 direkt auf 12.04, 12.04 direkt auf 14.04, 14.04 direkt auf 16.04, 16.04 direkt auf 18.04 usw.).
Dann kann man die Aktualisierung starten:
do-release-upgrade # auf die nächste Version aktualisieren.
do-release-upgrade -d # die devel-release/Entwickler-Version ermöglicht schon vor dem offiziellen erscheinen den Wechsel auf die nächste Version (beachtet die Hinweise oben zum devel-release).
Man muss nun den Anweisungen auf dem Bildschirm folgen.
Es kommen hier je nach installierter Version verschieden Fragen wie (Update starten?, neue Konfiguration übernehmen oder alte behalten?, automatischen Dienstneustart?, Pakete entfernen?, Neustart?).
Das Update läuft also nicht komplett automatisch durch und man sollte die Ausgaben beobachten.
Paketquellen per Hand bearbeiten (bei Bedarf):
nano /etc/apt/sources.list
Paketquellen komplett neu aufbauen (nur bei einem Fehler):
Erhält man beim Aktualisieren der Paketquellen einen Fehler wie z. B.:
[Das Repository wurde nicht aktualisiert und die vorherigen Indexdateien werden verwendet. GPG-Fehler:] oder
[Einige Indexdateien konnten nicht heruntergeladen werden. Sie wurden ignoriert oder alte an ihrer Stelle benutzt.],
so muss man folgende Schritte durchführen:
rm -rf /var/lib/apt/lists/ = vorhandene Paketlisten löschen.
apt-get clean = den kompletten Paket-Cache leeren.
apt-get update = und die Paketquellen neu einlesen/aktualisieren.
22. BitDefender Antivirus Scanner von einem Ubuntu Live-System aus nutzen:
BitDefender kann man für den privaten Gebrauch frei verwenden.
Hier zeige ich wie man diesen von einer Live-DVD (Xubuntu empfohlen) verwendet:
Zuerst die BitDefender Paketquellen hinzufügen:
sudo add-apt-repository 'deb http://download.bitdefender.com/repos/deb/ bitdefender non-free'
Die Signaturen für die Paketquellen hinzufügen:
wget -q http://download.bitdefender.com/repos/deb/bd.key.asc -O- | sudo apt-key add -
Die Paketquellen neu einlesen (aktualisieren):
sudo apt-get update --allow-insecure-repositories
Den Parameter '--allow-insecure-repositories' benötigt man nur in neueren Ubuntu Versionen, da die BitDefender Paketquelle derzeit noch nicht signiert ist.
Den Virenscanner installieren:
sudo apt-get install bitdefender-scanner
Den Virenscanner starten:
sudo bdscan
Hier dann die
Leertaste (ca. 6 mal) drücken oder einmal q drücken bis am Ende folgende Lizenzabfrage kommt:
Please enter "accept" if you agree to the License Agreement.
Die Lizenz wird bestätigt in dem man hier:
accept
Eingibt und die Eingabe mit Enter bestätigt.
sudo bdscan --info # Zeigt verschiedenste Versinformationen zur Scan-Enginge an.
Zum scannen notwendigen Parameter kann man sich wie folgt anzeigen lassen:
sudo bdscan --help
Oder besser man erzeugt schnell ein kleines Scan-Shell-Script zum scannen (Beispiel):
#!/bin/sh
# Als Shell-Script kennzeichnen.
# Virenscanner aktualisieren:
sudo bdscan --update
# Einen Virenscan durchführen & gefundene versuchen zu bereinigen, Archive (wie z. B. .zip, .gz, ...) und E-Maildatenbanken auslassen, mit Logfile:
sudo bdscan --action=disinfect --no-archive --no-mail --log=BitDefender.log.txt /Scan-Pfad
# Einen Virenscan durchführen & gefundene Virendateien löschen, E-Maildatenbanken auslassen,
# mit einem ausführlichen Logfile (listet auch entpackte Dateien auf),
# Suspekte Dateien werden in den angegebenen Ordner kopiert (diese sollte man separat genauer untersuchen/die Dateien bleiben am Ursprungsort):
sudo bdscan --action=delete --no-mail --verbose --log=BitDefender.log.txt --suspect-copy --quarantine=/Pfad/Quarantaene /Scan-Pfad
Wichtig: Das Quarantäneverzeichnis muss bereits existieren.
Optional:
--no-list = gescannte Dateinamen nicht im Protokoll speichern (kann das Scannen beschleunigen).
--archive-level=20 = Zu scannende ebenen von Archiven angegeben.
--ext=.exe = die angegebenen Dateitypen (nur .exe Dateien) scannen.
--exclude-ext=TYPEN folgende Dateitypen nicht scannen.
Sollte gleich nach dem Start der Fehler [Loading plugins, please wait - Speicherzugriffsfehler (Speicherabzug geschrieben)] kommen,
so führt man folgendes Script in einem Terminal aus (alles kopieren und im Terminal einfügen):
cat /opt/BitDefender-scanner/var/lib/scan/versions.dat.* | \
awk '/bdcore.so.linux/ {print $3}' | \
while read bdcore_so; do
sudo touch /opt/BitDefender-scanner/var/lib/scan/$bdcore_so;
sudo bdscan --update;
sudo mv /opt/BitDefender-scanner/var/lib/scan/bdcore.so /opt/BitDefender-scanner/var/lib/scan/bdcore.so.old;
sudo ln -s /opt/BitDefender-scanner/var/lib/scan/$bdcore_so /opt/BitDefender-scanner/var/lib/scan/bdcore.so;
sudo chown bitdefender:bitdefender /opt/BitDefender-scanner/var/lib/scan/$bdcore_so;
done
Will man den Scanverlauf beobachten, so startet man in einem extra Terminalfenster:
tail -f BitDefender.log.txt
Den Virenscanner wieder deinstallieren (optional):
sudo apt-get remove bitdefender-scanner
23. Linux sichern: Master Boot Record (MBR) und Partitionstabellen und Partitionen sichern & wiederherstellen:
Vorsicht: Änderungen am MBR und den Partitionstabellen bzw. den Partitionen können das System unbrauchbar machen.
Will man ein Linux System komplett sichern, so muss man:
1. Den Master Boot Record (MBR) oder auch (1. Bootsektor) sichern.
2. Die Partitionstabelle sichern (MBR oder GPT) also die Partitionierung sichern (welche Partitionen wurden wie angelegt, Anzahl, Größe, Dateisystem ...).
3. Zuletzt sollte man die eigentlichen Daten sichern. Hier gibt es verschiedene Möglichkeiten.
Empfehlen würde folgende Programme: dd, fsarchiver, partclone und pv (die Programme werden weiter unten beschrieben).
Da ich häufiger Linux-Systeme sichere, habe ich folgendes Sicherungsscript dafür geschrieben.
Das System wird hierbei automatisch über ein Live-System in einer Netzwerkfreigabe gesichert.

Weitere ausführliche Details zum Script werden hier nun beschrieben.
1. Master Boot Record (MBR), Bootloader und die primären Einträge der Partitionstabelle sichern:
Der Boot-Loader belegt die ersten 446 Bytes des MBR, dann folgen die Partitionstabelle (64 Bytes) und die MBR-Signatur.
Man sollte aber noch einige weitere Sektoren sichern, da diese evtl. von GRUB 2 verwendet werden.
Ist der Datenträger mit GPT-Partitionen ausgestattet so wird Partitionstabelle wo anders gespeichert.
Anzeigen:
dd if=/dev/sda count=1 | hexdump -C | more = Hexadezimale-Anzeige des Bootsektors.
Sichern:
Am besten ist es alle Sektoren bis zum Anfang der ersten Partition mit zu sichern (dies sichert ggf. auch Boot-Manager für Dualboot Systeme und GRUB 2 mit).
Um dies zu ermöglichen sind zwei Punkte wichtig.
Zum einen muss man die 'Sektorgröße' des Datenträgers wissen und den 'Anfang der ersten Partition' herausfinden.
Beides kann man mit fdisk herausfinden:
fdisk -l
Man erhält hier in etwa folgende Ausgabe:
Disk /dev/loop0: 934,4 MiB, 979812352 bytes, 1913696 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sda: 16 GiB, 17179869184 bytes, 33554432 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x000f3b42
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 29360127 29358080 14G 83 Linux
/dev/sda2 29362174 33552383 4190210 2G 5 Extended
/dev/sda5 29362176 33552383 4190208 2G 82 Linux swap / Solaris
Hier liest man dann die Sektorgröße und den Startsektor der ersten Partition ab.
Die ausgelesenen Werte setzt man hier entsprechend ein:
bs=Sektorgröße in Bytes (z. B. 512).
count=bestimmt die Anzahl der zu lesenden Sektoren (z. B. 2048).
dd if=/dev/sda of=backup_mbrgrub_only.img bs=446 count=1 =
sichert nur den MBR (GRUB 2 Bootloader), dies ist insbesondere sinnvoll vor Windows-Neuinstallationen bei Dualboot-Installationen.
dd if=/dev/sda of=backup_mbrgrub_part.img bs=512 count=1 =
sichert den gesamten MBR inkl. der Partitionstabelle von der ersten Festplatte (sda) als Datei im aktuellen Verzeichnis.
dd if=/dev/sda of=backup_mbrgrub_63.img bs=512 count=63 =
sichert den MBR inkl. der Partitionstabelle & GRUB (bei herkömmlichen Festplatten sind es meist 63 Sektoren).
dd if=/dev/sda of=backup_mbrgrub_2048.img bs=512 count=2048 =
sichert den MBR inkl. der Partitionstabelle & GRUB (bei VMs & SSDs sind es meist 2048 Sektoren).
Rücksichern:
dd if=beliebiges_backup.img of=/dev/sda bs=446 count=1 = stellt nur den MBR (GRUB 2 Bootloader) (die ersten 446 Bytes) wieder her, sinnvoll bei Dualboot-Installationen.
dd if=backup_mbr.img of=/dev/sda bs=512 count=1 = kompletten MBR inkl. Partitionstabelle) rücksichern.
dd if=backup_mbrgrub_63.img of=/dev/sda bs=512 count=63 = die ersten 63 Sektoren (MBR inkl. Partitionstabelle & GRUB) rücksichern (meist herkömmliche Festplatten).
dd if=backup_mbrgrub_2048.img of=/dev/sda bs=512 count=2048 = die ersten 2048 Sektoren (MBR inkl. Partitionstabelle & GRUB) rücksichern (meist VMs und SSDs).
Im Anschluss sollte man zusätzlich die logischen Partitionstabellen sichern (entweder MBR oder GPT).
2. MBR-Partitionstabellen (Master-Boot-Record-Partition-Table) anzeigen und sichern (Datenträger bis maximal 2 TB):
sfdisk kann nicht mit GPT-Partitionen und großen Partitionen (größer 2 TB) umgehen.
sfdisk verwendet man daher für die meist kleineren herkömmlichen Festplatten (Datenträger).
Anzeigen:
sfdisk -l /dev/sda = MBR-Partitionstabelle (MPT) anzeigen / Partitionen anzeigen.
Sichern:
sfdisk -d /dev/sda > backup_sda.mpt = MBR-Partitionstabelle von der ersten Festplatte (sda) sichern.
Rücksichern:
swapoff -a = (swapping deaktivieren) es kann sonst passieren das, das Live-System die swap-Partition verwendet und so ein Rücksichern verhindert.
sfdisk /dev/sda < backup_sda.mpt = die MBR-Partitionstabelle zurücksichern.
2. GPT-Partitionstabellen (GUID-Partition-Table) anzeigen und sichern
(neue Datenträger gemäß der EFI-Spezifikation - insbesondere alle Datenträger über 2 TB):
Auf GPT-Datenträgern wird aus Kompatibilitätsgründen ein sogenannter Schutz-MBR verwendet.
Dieser sorgt dafür, dass Betriebssysteme bzw. Programme, die noch nicht mit GPT zurechtkommen, statt eines leeren Datenträgers eine einzige Partition sehen, die über den ganzen Datenträger geht.
Will man von einem GPT-Datenträger starten, so benötigt man in der Regel Hardware die (Unified Extensible Firmware Interface) UEFI unterstützt.
Anzeigen:
sgdisk -p /dev/sda = GPT-Partitionen des Datenträges anzeigen / Partitions-Informationen anzeigen.
Erhält man hier eine Ausgabe [... Found invalid GPT and valid MBR ...], so bedeutet dies dass hier keine GPT-Informationen gespeichert sind.
Sichern:
sgdisk -b backup_sda.gpt /dev/sda = (backup) Partitionstabelle sichern.
Rücksichern:
sgdisk -l backup_sda.gpt /dev/sda = (load backup) Partitionstabelle wieder herstellen (dies sollte man nur auf demselben Datenträger ausführen).
24. GRUB 2 von einem Live System aus reparieren / MBR wieder herstellen (Ubuntu):
Diese Anleitung bezieht sich auf einfache Standard Desktop Systeme bei denen der MBR (Bootsektor/Bootloader) nach einer Windows-Installation überschrieben wurde.
Behandelt wird hier nur die Ubuntu-Version von GRUB 2 (ab Version 1.99 oder neuer).
Um Problemen aus dem Weg zu gehen sollte man bevorzugt das gleiche Installationsmedium bzw. eine möglichst gleiche Version verwenden.
root-directory-Methode:
Wichtig: Die verwendetet Live-CD muss die gleiche GRUB 2 Version verwenden.
mount /dev/sda1 /mnt # mounten der Linux root-Partition (sda1 entsprechend anpassen).
mount /dev/sdxBOOT /mnt/boot # Falls man eine extra boot-Partition verwendet, so muss man diese vorab einhängen (mounten).
mount /dev/sdxUEFI /mnt/boot/efi # Falls man eine UEFI-Partition verwendet, so muss man diese vorab eingehängen (mounten).
grub-install --root-directory=/mnt /dev/sda # Neuen GRUB 2 Bootsektor (MBR) schreiben.
chroot-Methode:
Wichtig: Die verwendete Live-CD muss der gleichen Architektur entsprechen (also 32-Bit oder 64-Bit beachten).
mount /dev/sda1 /mnt # mounten der Linux root-Partition (sda1 entsprechend anpassen).
mount /dev/sdxBOOT /mnt/boot # Falls man eine extra boot-Partition verwendet, so muss man diese vorab einhängen (mounten).
mount /dev/sdxUEFI /mnt/boot/efi # Falls man eine UEFI-Partition verwendet, so muss man diese vorab eingehängen (mounten).
mount -o bind /dev/ /mnt/dev # Umgebung vorbereiten.
mount -o bind /sys/ /mnt/sys # Umgebung vorbereiten.
mount -t proc /proc/ /mnt/proc # Umgebung vorbereiten.
chroot /mnt # Wechseln der Umgebung.
grub-install /dev/sda # Neuen GRUB 2 Bootsektor (MBR) schreiben.
Weiterführende Links für andere Systeme (z. B. RAID-Systeme):
GRUB 2 (ab 1.99 und neuer), Super Grub Disk
25. Problemlösung: horizontal doppelt/gespiegelt/gesplittete Darstellung ab 800x600 Pixeln unter VMWare ESXi beheben:
In Virtuellen Umgebungen (VMs) z. B. unter VMWare ESXi kann es passieren das der Bildschirminhalt ab einer Auflösung von 800x600 Pixeln, horizontal doppelt/gespiegelt/gesplittet - also mit Darstellungsfehlern angezeigt wird.
Der Fehler kann auch erst nach einem Update auftreten, wenn der Kernel aktualisiert wurde.
Bei mir trat der Fehler unter anderem unter Ubuntu 12.04 und Ubuntu 14.04 auf.
Es gibt hierbei zwei Lösungsmöglichkeiten:
1. Zuerst aktualisiert man die Virtualisierungssoftware also z. B. VMWare ESXi selbst.
Danach aktualisiert man die Hardware-Version der Virtuellen Maschine auf mindestens 10.
2. Sollte dies nicht möglich sein, da man die Virtuelle Umgebung nicht so einfach upgraden kann, so muss in der installierten Ubuntu Version folgende Änderungen vorgenommen werden:
sudo gedit /etc/modprobe.d/vmwgfx-fbdev.conf
Hier dann den Wert:
vmwgfx enable_fbdev=1
ändern auf:
vmwgfx enable_fbdev=0
Danach noch folgenden Befehl ausführen (Treiber für den Systemstart neu aufbauen):
sudo update-initramfs -u
und einen Neustart durchführen:
sudo reboot
Screenshot mit Lösungsweg (anklicken zum Vergrößern):
.")
26. VirtualBox VMs per Batchscript (cmd) starten und beenden:
Batchscript zum Starten von mehreren VMs (unter Windows):
start "ServerVM1" cmd /S /C ""C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" startvm headless "ServerVM1" --type headless"
start "ServerVM2" cmd /S /C ""C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" startvm headless "ServerVM2""
Gibt man den Parameter [--type headless] mit an, so startet die VM komplett im Hintergrund.
Die doppelten Anführungszeichen [""] muss man so eingeben.
Zum sauberen beenden von VMs sollte man die [Ausschalten per ACPI] Funktion verwenden.
Das System fährt dann beim Betätigen des Ein-/Ausschalters (powerbutton) immer sauber herunter.
Die ACPI Funktion muss man unter Linux noch entsprechend anpassen.
In der Datei:
nano /etc/acpi/powerbtn.sh
# fügt man am Anfang folgendes ein:
shutdown -P now # bei Ubuntu.
shutdown -h now # bei Debian.
Anschließend kann man die VMs mit folgendem Batchscript beenden (Windows):
"C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" controlvm "ServerVM1" acpipowerbutton
"C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" controlvm "ServerVM2" acpipowerbutton
27. gelöschte Bilder/Fotos wieder herstellen (recoverjpeg):
recoverjpeg durchsucht beliebige Speichermedien (z. B. ganze Festplatten, Partitionen, SD-Karten oder USB-Sticks) nach gelöschten jpg/jpeg Dateien und stellt diese wieder her.
Am leichtesten kann man recoverjpeg von einem Live-Medium verwenden.
Verwendet man eine Ubuntu-Live-DVD so muss man zuerst die [universe]-Paketquellen hinzufügen um die Installation zu ermöglichen (z. B. über das [Ubuntu Software-Center]).
Bei einer Debian 8 Live-DVD ist dieser Schritt nicht notwendig.
Hat man die Paketquellen verändert, so muss man diese erst noch aktualisieren (neu einlesen):
sudo apt-get update
Anschließend kann man recoverjpeg installieren:
sudo apt-get install recoverjpeg
Wichtig: Gefundene Dateien werden in dem Verzeichnis gespeichert aus welchem das Programm gestartet wurde.
Man muss daher zuerst auf die Festplatte oder Freigabe wechseln wo man die wiederhergestellten Bilder speichern möchte.
Anschließend kann man die Wiederherstellung wie folgt starten:
sudo recoverjpeg /dev/sda = durchsucht die komplette 1. Festplatte und speichert die gefundenen im aktuellen Verzeichnis ab.
sudo recoverjpeg /dev/sda1 = durchsucht die 1. Partition der 1. Festplatte und speichert die gefundenen im aktuellen Verzeichnis ab.
28. Datenrettung mit photorec:
photorec stellt von intakten und beschädigten Dateisystemen (auch von Images) mehr als 180 Dateiformate wieder her.
Es werden also nicht nur Fotos, sondern auch Office-, Musik-, Archiv-Dateien uvm. wiederhergestellt.
photorec installieren:
apt install testdisk
Wichtig:
Gefundene Dateien werden in dem Verzeichnis gespeichert aus welchem das Programm gestartet wurde.
Man muss daher zuerst auf die Festplatte oder Freigabe wechseln wo man die wiederhergestellten Bilder speichern möchte.
photorec ausführen:
photorec dd_image_oder_/dev/sdx
Es erscheint draufhin ein Textmenü, wo man Quell und Zielangaben sowie verschiedene Suchdetails festlegen kann.
Den eigentlichen Suchlauf startet man dann mittels der Taste c.
29. Datenrettung mit foremost:
foremost stellt verschiedene Dateitypen her. Weitere neue such Typen (Suchmuster) kann man manuell hinzufügen.
foremost installieren:
apt install foremost
Wichtig:
Gefundene Dateien werden in dem Verzeichnis gespeichert aus welchem das Programm gestartet wurde.
Man muss daher zuerst auf die Festplatte oder Freigabe wechseln wo man die wiederhergestellten Bilder speichern möchte.
Das Zielverzeichnis muss leer sein.
Suchlauf starten:
foremost -t all -v dd_image_oder_/dev/sdx
30. Datenrettung/Undelete (tsk_recover):
Das Forensik-Toolkit Sleuthkit (die Spürhund-Schnüffel-Tools) installieren:
apt get install sleuthkit
Zunächst am besten ein Image des zu untersuchenden Laufwerks erstellen:
dd if=/dev/sdX of=sdX_image status=progress bs=1M
Danach den Offset (den Beginn der verschiedenen Partitionen) ermitteln:
mmls sdX_image
Man erhält hier eine Ausgabe der Partitionen (hier ein Beispiel einer SD Karte):
DOS Partition Table
Offset Sector: 0
Units are in 512-byte sectors
Slot Start End Length Description
000: Meta 0000000000 0000000000 0000000001 Primary Table (#0)
001: ------- 0000000000 0000008191 0000008192 Unallocated
002: 000:000 0000008192 0015122431 0015114240 Win95 FAT32 (0x0b)
Die eigentliche Wiederherstellung startet man dann mittels:
tsk_recover -ev -o 8192 sdX_image /Ausgabepfad/
Parameterbeschreibung:
[-ev] 'e' alle Dateien wiederherstellen, 'v' (verbose) einen Verlauf anzeigen.
[-o 8192] ist die Offsetangabe, welche man entsprechend der Partitionen selbst anpassen muss.
[/Ausgabepfad/] bestimmt wo die restaurierten Daten gesichert werden. Der Ausgabepfad sollte logischerweise nicht auf das zu untersuchende/zu rettende Dateisystem verweisen.
31. Paketquellen/Repositories hinzufügen (main universe restricted multiverse):
Paketquellen (Repositories) sind eine Art Programm-Archiv-Sammlung, diese enthalten also eine Vielzahl von verschiedensten Programmen (Pakete) wie z. B. Treiber, Programme, Bibliotheken, Grafiken, Quellcode, Themas usw.
Installiert man einen neuen Ubuntu Server ab der Version 18.04, dann ist neuerdings nur noch die 'main' Paketquellen aktiv.
Will man nun Programme aus anderen Paketquellen installieren, dann muss man diese zuerst dem System hinzufügen.
Standardmäßig sind in Ubuntu die folgenden 4 Paketquellen/Repositories verfügbar:
main = enthält freie und open-source Software (Support durch Canonical).
universe = enthält freie und open-source Software (Support durch die Community).
restricted = enthält unter anderem proprietäre Treiber für Hardware.
multiverse = enthält Software die durch ein Copyright geschützt ist.
Live-Medien (DVDs) verwenden dabei die Paketquellen 'main' und 'restricted'.
'restricted' wird dabei insbesondere verwendet, um verschiedene Hardware Treiber wie Netzwerk- oder Hardware-RAID Treiber im Live-System zu aktivieren. So das man im Live-System auf alle Daten/Systeme/Netzwerke zugreifen kann.
Zu beachten ist das 'restricted' nur während der Live-Instanz aktiv ist. Nach einer Installation aus einem Live-System heraus wird 'restricted' nicht wieder automatisch aktiviert.
Paketquellen fügt man wie folgt zu:
add-apt-repository main universe restricted multiverse
Wichtig: Man sollte hier möglichst nur die Paketquelle/n hinzufügen die man tatsächlich benötigt.
Fremde/fehlerhafte Paketquellen können ggf. das System beschädigen.
Daher gilt:
Je weniger Paketquellen man verwendet, umso stabiler läuft ein System (weniger Abhängigkeiten/weniger Fehler).
Meist dürfte die 'universe' Paketquelle fehlen (für Copy & Paste):
add-apt-repository universe
In älteren Ubuntu Versionen muss man hier noch den kompletten Pfad zur Paketquelle mit angeben:
sudo add-apt-repository "deb http://archive.ubuntu.com/ubuntu $(lsb_release -sc) main universe restricted multiverse"
Fremde/Partner Paketlisten fügt man wie folgt hinzu:
sudo add-apt-repository "deb http://archive.canonical.com/ubuntu $(lsb_release -sc) partner"
Bei fremden/eignen Adressen muss man den Link entsprechend anpassen.
Beachtet auch folgendes: [lsb_release -sc] ermittelt während der Laufzeit den zum aktuellen Release vergebenen Namen (z. B. 'bionic' bei Ubuntu 18.04).
Statt '$(lsb_release -sc)' kann man also auch den aktuellen Release-Namen verwenden, in dem Beispiel 'bionic'.
Nachdem man die Paketquellen aktualisiert hat, muss man diese ggf. noch einmal aktualisieren (teilweise geschieht das auch automatisch - dies ist Versionsabhängig):
apt-get update
Erst dann kann man Pakete aus den neu hinzugefügten Paketquellen installieren.
Man kann die Paketliste wie folgt
editieren:
nano /etc/apt/sources.list
Nicht mehr benötigte Paketquellen kann man durch auskommentieren der Zeilen mit einem Rautezeichen '#' deaktivieren.
Oder man entfernt nur die nicht mehr benötigten Paketquellen Namen wie z. B. main, universe, restricted, multiverse aus den vorhandenen Zeilen.
Wichtig: Beachtet dabei, das man Programme die man über eine deaktivierte Paketquelle installiert hat nicht mehr aktualisieren kann!
Das kann dann auch schnell zu einem Sicherheitsproblem führen. Man sollte daher vom Anfang an, nur die Paketquellen aktivieren, welche man wirklich benötigt.
Paketquellen im Nachhinein zu deaktivieren bringt meiner Meinung nach auf lange Sicht hin eher nur Fehler. Ich persönlich rate jedem von einer Deaktivierung ab.
Weiterführende Informationen findet man hier: help.ubuntu.com/community/Repositories/Ubuntu/
32. FSlint (filesystem lint):
FSlint [GitHub] dient zum Aufräumen der Festplatte.
FSlint bietet hierzu viele Funktionen an. Hier soll es jedoch hauptsächlich darum gehen größere Datenarchiv-Sammlungen (Fotos/Musik/ISOs usw.) zu bereinigen.
Vermutlich kennt jeder das Problem:
Oft legt man schnell mal eine lokale Sicherheitskopie einer Datei an oder man sucht man ein paar Bilder zum Ausdrucken heraus.
Oft vergisst man dann diese doppelten Kopien wieder zu löschen.
Diese doppelten Dateien kann man nun mittels FSlint suchen und löschen.
Eine bessere Alternative Variante ist duff (meine Empfehlung).
wichtige Hinweise vorab:
- In der Version 2.44 unter Ubunt 18.10 wurden bei mir nicht immer alle doppelten Dateien gefunden (2019-01-09), daher würde ich von der Nutzung vorerst abraten.
- Zum Scannen sollte man möglichst nur physische Pfade (direkte Pfade auf das entsprechende Directory) angeben.
Denn eine Pfadangabe auf eine Verlinkung kann dazu führen das Dateien doppelt erfasst werden (einmal physisch und einmal über die Verlinkung).
Diese würden dann ggf. unwiederbringlich gelöscht.
- Eine Datensicherung sollte vorhanden sein. Testet die Aufrufe wenn möglich erst in einer Testumgebung.
Allgemein gilt für FSlint immer: Hardlinks werden wie normale Dateien behandelt, also mit gelöscht wenn sie doppelt vorkommen (bis auf eine). Softlinks bleiben alle erhalten.
FSlint legt im Ordner '/usr/share/fslint/fslint/' mehrere Scripte (Python) ab, daher ist zum Aufruf immer der komplette Pfad zum Programm/Script nötig.
Insbesondere wenn man schon Phython einsetzt sollte man sich FSlint ansehen.
Bis Version 2.44 werden leere Dateien nicht mit berücksichtig.
Ab der Version 2.46 werden leere Dateien (mit der Dateigröße 0) wieder mit berücksichtig, das Verhalten ist ab der Version 2.46 mit dem Parameter: [-size +0c] anpassbar.
FSlint installieren:
apt install fslint
FSlint hat auch eine GUI (grafische Oberfläche). Diese startet man entweder über das entsprechende Icon im Startmenü oder mittels:
fslint-gui
Wichtig: Das Terminal Fenster erst schließen wenn alles erledigt ist.
Vorsicht: Man kann hier auch alle Dateien löschen, so dass kein Original übrig bleibt! Ich würde daher von der grafischen Oberfläche eher abraten.
Insbesondere wenn man viele doppelte Dateien bereinigen will sollte man die folgenden Aufrufe verwenden.
/usr/share/fslint/fslint/findup -h
= Die Hilfe anzeigen.
/usr/share/fslint/fslint/findup -v
= Die installierte Version anzeigen (unter Ubuntu 18.10 wird derzeit FSlint 2.44 installiert).
Eine neuere Version ist ggf. hier verfügbar.
nur scannen (hier wird nichts verändert):
/usr/share/fslint/fslint/findup /Pfad /Pfad2
= Scannt die angegebenen Ordner, auch rekursiv, nach doppelten Dateien (beliebig viele Pfade sind möglich, ohne Pfadangabe wird das aktuelle Verzeichnis gescannt).
/usr/share/fslint/fslint/findup -r /Pfad = Scannt nur im angegebenen Ordner nach doppelten Dateien, die rekursive Suche wird verhindert (-r = no subdirectory).
/usr/share/fslint/fslint/findup --summary /Pfad
= Scannt den angegebenen Ordner, auch rekursiv nach doppelten Dateien und ermittelt grob den möglicherweise eingesparten Speicherplatz (summary). Der Parameter -summary kann nicht mit -d oder -m kombiniert werden.
/usr/share/fslint/fslint/findup -d -t /Pfad
= Scannt den angegebenen Ordner, auch rekursiv und zeigt an was gelöscht werden würde (delete test).
doppelte Dateien löschen:
/usr/share/fslint/fslint/findup -d /Pfad
= Sucht alle doppelten Dateien im angegebenen Ordner, auch rekursiv und löscht diese ohne jegliche Rückfrage (delete).
Während des löschens erhält man keine Statusanzeige.
doppelte Dateien als Hardlink verlinken (nur innerhalb derselben Partition möglich/weniger empfohlen):
/usr/share/fslint/fslint/findup -m -t /Pfad
= Scannt den angegebenen Ordner, auch rekursiv und zeigt an welche Dateien mit einem Hardlink verlinkt versehen würde (merge hardlink test).
/usr/share/fslint/fslint/findup -m /Pfad
= Scannt den angegebenen Ordner, auch rekursiv und erzeugt zu doppelten Dateien Hardlinks (merge hardlink).
Während des verlinkens erhält man keine Statusanzeige.
fehlerhafte symbolische Links finden (z. B. Links die ins Leere laufen):
/usr/share/fslint/fslint/findbl /Pfad
= Listet fehlerhafte Softlinks auf (bad links). Zum Beispiel Links die auf gelöschte Dateien/nicht mehr existierende Dateien verweisen.
optionaler Parameter:
[-f] = Zu den gefundenen Dateien wird der relative Pfad (ab dem Suchpfad) mit ausgegeben.
33. duff (DUplicate File Finder):
duff [GitHub] sucht doppelte Dateien.
Auf Grund des anpassbaren Hash-Algorithmus und der vielseitigen Parameter ist duff derzeit mein Favorit zum Bereinigen doppelter Dateien. Die Version 0.5.2 ist seit dem 29. Januar 2012 stable (fehlerfrei).
Allgemein gilt für duff immer:
Hardlinks werden Standardmäßig wie normale Dateien behandelt, also mit gelöscht (bis auf eine Datei) wenn sie doppelt vorkommen (zum Ändern des Verhaltens siehe Parameter '-p' unten).
Symbolischen Links (Softlinks) wird grundsätzlich niemals gefolgt, diese bleiben immer alle erhalten.
Während eines Suchlaufes nach doppelten Dateien sollte man keine Dateien verändern oder öffnen (vorab möglichst alle Programme schließen).
Vorsicht: Man darf niemals zweimal denselben Pfad angeben, denn es werden sonst ggf. auch einzelne Dateien gelöscht (da diese dann zweimal gefunden werden).
Wichtig: Die Hockkomma (') um die Pfadangaben sind notwendig wenn der Pfadname Leerzeichen enthält, man sollte diese daher immer mit angeben.
duff installieren:
apt install duff
schnelle Variante mit SHA256 Prüfsumme zum Auflisten und löschen von doppelten Dateien:
#!/bin/bash
duff -arzd sha256 '/Pfad' '/Pfad2'
= Alle doppelten Dateien mit der SHA256 Prüfsumme gruppiert ausgeben (gekürzte Version). Mehrere Pfade sind immer möglich.
duff -0arzed sha256 '/Pfad' | xargs -0rn1 echo
= Nur die zu löschenden doppelten Dateien ausgeben (dies ist kein löschen).
duff -0arzed sha256 '/Pfad' | xargs -0r rm -fv
= Löscht alle doppelten Dateien (bis auf eine).
wichtiger Hinweis:
Beim Löschen von doppelten Dateien mit der schnellen Variante wird die Datei die zuerst gefunden wird behalten. Die Reihenfolge des Namens, des Directorys oder die Zeit der letzten Änderung usw. wird hier nicht berücksichtigt.
Besser ist es daher eine der folgenden Varianten zu verwenden, da hier alle Dateien vor der Weiterverarbeitung erst sortiert werden.
aufsteigend sortiert - übergeordnete Ordner 📁
für Downloads und Kopien 💿 und ähnliches:
Zeigt alle doppelte Dateien gruppiert an (die erste Datei bleibt erhalten):
find '/Pfad' -type f -printf '%d %p\0'
| sort -nz | sed -z 's/^[^ ]* //'
| duff -0arzdsha256 | xargs -0rn1 echo
| tee doppelte_Dateien.txt
Nur die zu löschenden doppelten Dateien ausgeben (dies ist kein löschen):
find '/Pfad' -type f -printf '%d %p\0'
| sort -nz | sed -z 's/^[^ ]* //'
| duff -0arzedsha256 | xargs -0rn1 echo
| tee doppelte_Dateien.txt
Löscht alle doppelten Dateien (bis auf eine):
find '/Pfad' -type f -printf '%d %p\0'
| sort -nz | sed -z 's/^[^ ]* //'
| duff -0arzedsha256 | xargs -0r rm -fv
| tee doppelte_Dateien.txt
Bei dieser Variante wird immer die Datei die am höchsten liegt behalten (im übergeordneten Verzeichnis).
'sort -nz' sortiert die gefundenen Dateien aufsteigend von 0-9 und a-Z, bevor sie weiter verarbeitet werden. Am Ende wird wieder ein Nullbyte '-z = zero' angehängt.
Hier noch ein Beispiel für 'sort -nz' (aufsteigend sortiert/übergeordneter Ordner):
/Downloads/Bild.jpg <- Diese übergeordnete Datei wird behalten.
/Downloads/Bild (1).jpg <- Diese Kopie der Datei wird gelöscht.
/Downloads/ausgesuchte-Bilder/Bild.jpg <- Diese untergeordnete Kopie der Datei wird gelöscht.
absteigend sortiert - untergeordnete Ordner 📁
für sortierte Fotos, MP3s 🎹 und vergleichbare Mediensammlungen (empfohle Variante):
Zeigt alle doppelte Dateien gruppiert an (die erste Datei bleibt erhalten):
find '/Pfad' -type f -printf '%d %p\0'
| sort -nrz | sed -z 's/^[^ ]* //'
| duff -0arzdsha256 | xargs -0rn1 echo
| tee doppelte_Dateien.txt
Nur die zu löschenden doppelten Dateien ausgeben (dies ist kein löschen):
find '/Pfad' -type f -printf '%d %p\0'
| sort -nrz | sed -z 's/^[^ ]* //'
| duff -0arzedsha256 | xargs -0rn1 echo
| tee doppelte_Dateien.txt
Löscht alle doppelten Dateien bis auf eine:
find '/Pfad' -type f -printf '%d %p\0'
| sort -nrz | sed -z 's/^[^ ]* //'
| duff -0arzedsha256 | xargs -0r rm -fv
| tee doppelte_Dateien.txt
Bei dieser Variante wird die Dateien die am tiefsten liegt behalten (im untergeordneten Verzeichnis).
'sort -nzr' sortiert die gefundenen Dateien absteigend '-r = rekursiv' von Z-a und 9-0, bevor sie weiter verarbeitet werden. Am Ende wird wieder ein Nullbyte '-z = zero' angehängt.
Hier noch ein Beispiel für 'sort -nzr' (rekursiv/absteigend sortiert/untergeordneter Ordner):
/Downloads/Bild.jpg <- Diese Kopie der Datei wird gelöscht.
/Downloads/Bild (1).jpg <- Diese Kopie der Datei wird gelöscht.
/Downloads/ausgesuchte-Bilder/Bild.jpg <- Diese untergeordnete Kopie der Datei wird behalten.
Parametererklärungen:
[find] = sucht im angegebenen Pfad (mehrere Pfade sind möglich) rekursiv (in allen Unterordnern) alle Dateien/Verzeichnisse.
[-type f] = filtert nur nach Dateien 'f = file' unter anderem werden hier Verzeichnisse übersprungen.
[-printf] = gibt die gefundenen Daten wie folgt formatiert aus:
[%d ] = ist die Verzeichnistiefe als ganze Zahl. Danach wird später entsprechend sortiert. Das darauffolgende Leerzeichen dient als Trennzeichen.
[%p] = enthält den kompletten Dateinamen mit dem Pfad.
[\0] = hängt am Ende immer ein Nullbyte an den gefundenen Dateinamen an, dies ist notwendig, um Dateinamen mit Leerzeichen oder Sonderzeichen korrekt voneinander zu trennen.
[sort -nrz] = sortiert die gefundenen Dateinamen von 0-9 bzw. a-Z aufsteigend '-n = numeric-sort', bevor sie weiter verarbeitet werden.
Mit dem Parameter '-r = rekursiv' wird die Sortierung absteigend durchgeführt. Am Ende wird wieder ein Nullbyte '-z = zero' angehängt.
[sed -z 's/^[^ ]* //'] = schneidet nach der Sortierung die Zahl am Anfang '^' und das einzelne Leerzeichen '[^ ]' ab. Der Rest bleibt unverändert '*'. Daten werden wieder mit Hilfe des Nullbytes getrennt '-z = zero'.
[|] über die Pipe werden die gefundenen Dateinamen erst an duff übergeben, duff Filtert die doppelten Dateien entsprechend und übergibt die gefilterten Dateinamen erneut über die Pipe [|] an den nachfolgenden Befehl.
[duff] = sucht die doppelten Dateien unter Berücksichtigung der nachfolgenden Parameter heraus.
[-0] = trennt den Datenstrom von der Standardeingabe immer am Nullbyte.
[-a] = dabei werden alle versteckte Dateien und alle versteckten Verzeichnisse mit berücksichtigt, ohne dem Parameter werden versteckte übersprungen.
[-r] = sucht auch rekusiv in allen Unterverzeichnissen, ohne dem Parameter wird nur das aktuelle Verzeichnis überprüft.
[-z] = alle leere Dateien (mit der Dateigröße 0) ignorieren, ohne diesem Parameter bleibt eine leere Datei bestehen.
Tipp: Mehrere leere Dateien löscht man mit find.
[-d sha256] = bestimmt den Hash-Algorithmus. Möglich ist: sha1, sha256, sha384 oder sha512, ohne dem Parameter wird Standardmäßig sha1 verwendet.
Da SHA1 bereits seit 2005 nicht mehr 100% sicher ist sollte man hier mindestens SHA256 einsetzen.
Um den Hash-Algorithmus zu testen, kann man die folgenden 2 Dateien verwenden: Link1, Link2 (empfohlen).
Beachtet hier vor allem, die 2 Dateien haben einen unterschiedlichen Inhalt, aber die gleiche SHA-1 Prüfsumme.
Weitere Informaionen dazu sind hier zu finden: shattered.it, Secure Hash Algorithm,
Kollisionsangriff.
[-e] = (excess mode) Löscht alle doppelten Dateien bis auf eine.
[xargs -0rn1] = trennt den Datenstrom von der Standardeingabe am Nullbyte '-0' und fügt einen Zeilenumbruch '-n1' ein.
Der nachfolgende Befehl wird nur dann ausgeführt, wenn Daten von der Standardeingabe
kommen '-r = --no-run-on-empty'.
Die ermittelten Dateinamen werden dann an den nachfolgenden Befehl übergeben.
[echo] = gibt dann den entsprechenden Datenstrom, die Namen und Pfade zu den doppelten Dateien aus.
[rm -fv] = löscht die Dateien ohne Rückfrage
'-f = force' ggf. nicht löschbare Dateien überspringen (z. B. bei Dateien mit unzureichender Berechtigung) und
'-v = verbose' anzeigen was gelöscht wird.
[tee doppelte_Dateien.txt] = (optional) gibt die Namen und Pfade der doppelten Dateien auf dem Bildschirm (der Standardausgabe) aus.
Zusätzlich wird die Ausgabe in die Datei: 'doppelte_Dateien.txt' umgeleitet. Diese Datei kann man dann zum Prüfen verwenden ob alles richtig ist.
Beachtet dabei folgendes, die erste Datei einer Gruppe bleibt bei einem späteren löschen immer übrig.
die Suche mittels 'find' kann man noch beliebig erweitern hier noch ein paar Beispiele:
find '/Pfad' -type f -name ".mp3"
-printf '%d %p\0'|sort -nrz
|sed -z 's/^[^ ]* //'
|duff -0arzedsha256|xargs -0rn1 echo
= Sucht nur nach Dateien die exakt auf '.mp3' enden.
find '/Pfad' -type f -iregex ".*\.jpe?g"
-printf '%d %p\0'|sort -nrz
|sed -z 's/^[^ ]* //'
|duff -0arzedsha256|xargs -0rn1 echo
= Sucht nur nach Dateien die auf '.jpg' oder '.jpeg' enden. Die die Groß- und Kleinschreibung wird dabei nicht berücksichtigt (findet also auch '.JPG', '.jpeg', '.Jpg').
find '/Pfad' -type d -name "Bilder"
-printf '%d %p\0'|sort -nrz
|sed -z 's/^[^ ]* //'
|duff -0arzedsha256|xargs -0rn1 echo
= Sucht nur in Verzeichnissen die exakt den Namen 'Bilder' tragen.
find '/Pfad' -type d -iname "*Bilder*"
-printf '%d %p\0'|sort -nrz
|sed -z 's/^[^ ]* //'
|duff -0arzedsha256|xargs -0rn1 echo
= Sucht nur in Verzeichnissen die den Namen 'Bilder' enthalten. Die Groß- und Kleinschreibung wird dabei nicht berücksichtigt (findet also auch 'Urlaubsbilder').
Das alles waren nur Anregungen.
Auch eine Suche nach: Dateigröße, Benutzernamen, Benutzerrechten, Dateialter, letzten Zugriffen bzw. Änderungen usw. kann man realisieren, mehr dazu findet man unter find.
ergänzende Parameter für duff insbesondere für Verlinkungen:
[-H] = Folgt nur symbolischen Links die man auch als Parameter mit übergeben hat (nicht empfohlen).
[-L] = Folgt allen symbolischen Links - auf beliebige andere Verzeichnisse (nicht empfohlen).
Vorsicht: Die Verfolgung von symbolischen Links kann dazu führen, dass eine einzelne Datei ggf. doppelt gefunden und gelöscht wird (wenn innerhalb des Suchpfades auf ein und dasselbe Verzeichnis verlinkt wurde).
[-P] = Symbolischen Links auf andere Verzeichnisse nicht folgen (hebt den Parameter '-H' und '-P' wieder auf). Die Angabe ist nicht notwendig, da dies die Standardeinstellung ist.
[-p] = Hardlinks auf Dateien innerhalb eines physischen Laufwerks (physical mode) werden nicht als doppelt erkannt. Alle Hardlinks dann bleiben bestehen (dies ist ggf. erwünscht).
[-t] = Dateien Byte-weise vergleichen, falls man kein Vertrauen in den Hash-Algorithmus hat (nicht empfohlen).
ergänzendes Beispiel zur Anpassung der Ausgabe beim Suchen von doppelten Dateien (optional):
duff /Pfad -a -r -d sha256
-f $'\nAnzahl der doppelten Dateien: %n\nDateigröße: %s\nHash: %d\nbelegte Cluster: %i'
Zusammenfassend anzeigen:
Wie oft kommen die einzelnen Dateien doppelt vor '%n = number',
wie groß ist eine einzelne Datei '%s = size',
die Prüfsumme '%d = digest' der Datei (hier SHA256) und
wie viele Cluster belegt eine Datei '%i = cluster index'.
34. rdfind (redundant data find):
rdfind [GitHub] sucht doppelte Dateien.
Vorab Hinweise:
Viele rdfind Parameter sind erst ab der Version 1.4 möglich. Ich empfehle daher die rdfind Nutzung erst ab Ubuntu 19.04 bzw. ab Debian 10.
In der neuen Version 1.4 sind mir keine Fehler aufgefallen, soweit passt also alles. Einer produktiven Nutzung steht also nichts im Wege.
Verwendet auf anderen älteren Systemen lieber duff (nach wie vor meine Empfehlung).
Wichtig: Pfadangaben müssen bei rdfind grundsätzlich immer am Ende stehen.
rdfind installieren:
apt install rdfind
nach doppelten Dateien suchen (nur Statusbericht):
rdfind -checksum sha1 -ignoreempty false "/Pfad" "/Pfad2" = Scannt die angegebenen Ordner, auch rekursiv, nach doppelten Dateien. Leere Dateien (0 Byte) berücksichtigen.
doppelte Dateien und ggf. Links löschen:
rdfind -checksum sha256 -deleteduplicates true "/Pfad" = Alle doppelten Dateien löschen, Hardlinks und Softlinks bleiben bestehen (auch rekursiv).
rdfind -checksum sha256 -deleteduplicates true -removeidentinode false "/Pfad" = Alle doppelten Dateien und Hardlinks löschen (auch rekursiv).
rdfind -checksum sha256 -deleteduplicates true -followsymlinks true "/Pfad" = Alle doppelten Dateien und Softlinks löschen (auch rekursiv).
doppelte Dateien verlinken (nicht löschen):
rdfind -checksum sha256 -makehardlinks true "/Pfad" = Alle doppelten Dateien als Hardlink anlegen (ggf. empfohlen).
rdfind -checksum sha256 -makesymlinks true "/Pfad" = Alle doppelten Dateien als symbolischen Link verlinken (nicht empfohlen).
Parametererklärungen:
["/Pfad" "/Pfad2"] = mehrere Pfadangaben sind möglich. Es werden beide Pfade zusammengefasst betrachtet.
So kann man damit z. B. systemübergreifend mehrere Festplatten mit nur einem Lauf bereinigen. Pfadangaben sollten in Anführungszeichen (") stehen um Pfade mit Sonderzeichen/Leerzeichen zu ermöglichen.
Bitte beachten Pfadangaben müssen immer am Ende stehen. Steht der Pfad am Anfang der Parameter so wird dieser ggf. ignoriert (Versionsabhängig).
[-checksum sha256] = Verwendet zum Überprüfen der Binärgleichheit der Dateien den angegeben Hash-Algorithmus.
Folgende Standards sind möglich:
[md5] = Standard bis Version 1.3.5 (nicht mehr 100% sicher).
[sha1] = Standard ab Version 1.4 (bedingt geeignet).
[sha256] = erst ab der Version 1.4 bzw. ab Ubuntu 19.04 bzw. Debian 10 möglich (empfohlen).
Ob Dateien wirklich 1:1 identisch sind wird immer anhand einer Prüfsumme berechnet.
Da SHA1 bereits seit 2005 nicht mehr 100% sicher ist sollte man hier mindestens SHA256 einsetzen.
Um den Hash-Algorithmus zu testen, kann man die folgenden 2 Dateien verwenden: Link1, Link2 (empfohlen).
Beachtet hier vor allem, die 2 Dateien haben einen unterschiedlichen Inhalt, aber die gleiche SHA-1 Prüfsumme.
Weitere Informaionen dazu sind hier zu finden: shattered.it, Secure Hash Algorithm,
Kollisionsangriff.
[ -deleteduplicates true] = true, löscht dopplte Dateien bzw. Links. false = nichts löschen ist Standard.
[-removeidentinode false] = Löscht Dateien mit demselben inode Verweis (also Hardlinks). Es werden dann alle doppelten Dateien definitiv gelöscht.
Ohne dem Parameter bleiben Dateien mit Hardlinks bestehen.
Ohne dem Parameter werden also nur doppelte Dateien (Kopien) gelöscht, die nicht verlinkt sind.
Weitere Informationen zu Links findet man unter ln.
[-ignoreempty false] = Leere Dateien (0 Byte) werden berücksichtig. true = leere Dateien werden ignoriert ist Standard.
[-followsymlinks true] = Folgt beim Scannen symbolischen Links. Symbolische Verknüpfung werden gelöscht.
Vorsicht: Dies kann dazu führen das einzelne Dateien doppelt gefunden werden, wenn innerhalb des Suchpfades auf dasselbe Verzeichnis nochmal verlinkt wurde (loops).
[-deterministic false] = Sortierung ausschalten (unspezifiziert). Die zuletzt gefundene Datei bleibt bestehen (weniger empfohlen). Dieser Parameter ist erst ab der Version 1.4 möglich.
[-makeresultsfile false] = Keine Ergebnisdatei ausgeben. Standardmäßig wird im ausführenden Verzeichnis die Datei 'results.txt' erstellt. Eine ggf. bereits bestehende Datei wird überschrieben.
[-outputname "/Pfad/Ergebnis.txt"] = Hiermit kann man den Pfad und den Name zur Ergebnisdatei (Standard 'results.txt') verändern.
[-dryrun true] = Alle Änderungen werden nicht vorgenommen. Mögliche Veränderungen werden nur am Bildschirm angezeigt.
[-sleep 100ms] = Nach jeder Datei eine Pause von
(0,1-5,10,25,50,100) Millisekunden einlegen (es sind nur exakt die hier angegenen Werte möglich), um die Systemlast zu minimieren (weniger empfohlen).
[-minsize X] = Scannt den angegebenen Ordner, auch rekursiv, nach doppelten Dateien, Dateien die kleiner als X Bytes sind werden ignoriert/übersprungen. Der Standardwert 1, entspricht einer leeren Datei, den Wert kann man beliebig verändern. Dieser Parameter ist erst ab der Version 1.4 möglich.
Man kann rdfind auch mit einem Datenstrom über die Standardeingabe bzw. Standardausgabe verwenden und so vorab schon verschiedene Filter definieren:
find /Pfad -type d -name "Bilder" -print0|xargs -0r rdfind = Sucht nur in Verzeichnissen die exakt den Namen 'Bilder' tragen.
find /Pfad -type d -iname "*Bilder*" -print0|xargs -0r rdfind = Sucht nur in Verzeichnissen die den Namen 'Bilder' enthalten, die Groß- und Kleinschreibung wird hier nicht berücksichtigt (findet also z. B. auch 'Urlaubsbilder').
35. .eml Dateien entpacken:
E-Mails werden in der Regel als Text übertragen. Enthaltene Dateianhänge werden dabei immer MIME-codiert übertragen.
Hat man nun eine gespeicherte .eml-Datei erhalten und möchte auf die Anhänge zugreifen, so geht man wie folgt vor:
Zuerst installiert man den MIME-Packer:
apt install mpack
Anschließend kann man die Dateianhänge wie folgt extrahieren:
munpack -t -f zu_entpackende_email.eml
Parametererklärungen:
[-t] (type) MIME codierte Inhalte mit entpacken.
[-f] (force) vorhandene Zieldateien überschreiben.
[-C] (Change) anderes Zielverzeichnis vorgeben (optional). Standardmäßig wird ins aktuelle Verzeichnis entpackt.
Zum Packen verwendet man [mpack].
36.
Mit dem exiftool (Dokumentation,
FAQ,
renaming examples,
filename) kann man Metainformationen von Bild-, Video- oder Musik-Dateien auslesen und verändern.
Man kann Beispielsweise das exiftool dazu verwenden um Bilder nach dem Aufnahmedatum umzubenennen oder um Aufnahmen zeitlich sortiert in Ordner zu verschieben.
Dies ist insbesondere dann sehr hilfreich, wenn man Fotoaufnahmen von verschiedenen Apparaten vereinheitlichen will.
exiftool installieren:
apt install libimage-exiftool-perl
Wichtige Hinweise vorab:
Die Hochkommas (') um die Parameter sollte man immer mit angeben, denn ohne der Angabe kann es dazu kommen das die Shell versucht Daten aus der Standardeingabe (<) zu lesen.
Auch bei der Maskierung von Pfad- und Dateinamen mit Leerzeichen ist die Angabe der Hochkommas notwendig. Diese sollte man daher immer mit angeben.
Beachtet auch, wenn man exiftool unter Windows nutzt muss man statt den Hochkommas (') teilweise Anführungszeichen (") verwenden.
alle Exif Daten anzeigen:
exiftool IMG.jpg # = zeigt alle im Tag (Exif) gespeicherten Daten zu der Mediendatei (Bild, Musik, Video usw.) an.
exiftool -l IMG.jpg # = (long) zeigt alle im Tag gespeicherten Metadaten an.
exiftool -h -g IMG.jpg > HTML-Datei.txt # = speichert alle Metadaten im HTML-Format, gruppiert (sortiert) ab. Alternativ: [-G] = der Gruppenname steht vor jedem Tag.
exiftool -l -X IMG.jpg > Datei.xml # = speichert alle Metadaten in der angegebenen RDF/XML-Datei ab. Ideal zur weiteren Verarbeitung.
exiftool -TAG -Exif:Make IMG.jpg # = zeigt die Metadaten nur von dem einen entsprechenden Exif Tag an (Make = ist hier Beispielsweise der Hersteller).
Bilder umbenennen:
Es wird hier immer nur der Dateiname verändert, der Dateiinhalt wird nicht verändert.
zum Testen - Datum und Uhrzeit, nicht rekursiv (mögliche Änderungen werden nur angezeigt):
exiftool '-TestName<${DateTimeOriginal}%-c.%le'
-d '%y%m%d_%H%M%S' '/Pfad'
Variante A - Datum, Uhrzeit, Auflösung, Hersteller, Modell, ggf. laufende Nr., kleine Dateiendung, rekursiv:
exiftool '-FileName<${DateTimeOriginal}
_${ImageSize}_${Make;}_${Model;}%-c.%le'
-d '%Y%m%d-%H%M%S' -r '/Pfad'
Variante B - Datum, Uhrzeit, ggf. laufende Nr., nur .jpg & .jpeg, rekursiv (empfohlen):
exiftool '-FileName<${DateTimeOriginal}%-c.%le'
-d '%y%m%d_%H%M%S' -r -ext jpg -ext jpeg '/Pfad'
Variante C - Datum, Uhrzeit, ggf. laufende Nr., nur .jpg & .jpeg, rekursiv, mit Abständen (empfohlen, besser lesbar):
exiftool '-FileName<IMG_${DateTimeOriginal}%-c.%le'
-d '%Y-%m-%d_%H.%M.%S' -r -ext jpg -ext jpeg '/Pfad'
Dateinamen Beispiele:
Variante A - Datum, Uhrzeit, Auflösung, Hersteller und Modell:
20190131_231500_4320x2432_Panasonic_DMC_TZ31.jpg
Variante B - Datum und Uhrzeit kompakt:
20190131_231500.jpg
Variante C - Datum und Uhrzeit optisch besser lesbar:
IMG_2019-01-31_23.15.00.jpg
Parametererklärungen:
['-TestName<${DateTimeOriginal}'] = die möglichen Änderungen werden nur angezeigt, aber nicht durchgeführt.
['-FileName<${DateTimeOriginal}'] = bedeutet die Datei wird nach dem Original Aufnahmedatum umbenannt.
[-d] = (dateformat) bestimmt das Format des Datums anhand der nachfolgenden Werte.
[%Y%m%d] = Jahr (vierstellig), Monat, Tag (zweistellig), alternativ: [%y] das Jahr nur zweistellig.
[%H%M%S] = Stunden, Minuten, Sekunden immer zweistellig.
[%-c] = (counter) Falls zwei Dateien dieselben Daten enthalten werden diese fortlaufend durchnummeriert.
Beispielsweise: 20191231_120601.jpg, 20191231_120601-1.jpg, 20191231_120601-2.jpg, ...
Das Minus '-' (ein anderes Zeichen ist nicht möglich) fügt eine Trennung ein, so dass man die Nummerierungen besser erkennen kann.
[.%le] = (lower extension) die Dateierweiterung wird in Kleibuchstaben umgewandelt.
[.%ue] = (upper extension/Alternative 1) die Dateierweiterung wird immer groß geschrieben.
[.%e] = (extension/Alternative 2) die original Dateierweiterung bleibt unverändert.
[-r] = (recursiv) auch die Unterordner mit durchsuchen.
[-ext jpg] = (extension) bestimmt die zu durchsuchende Dateierweiterung. Die Option kann bei Bedarf auch mehrfach angegeben werden. Ohne dem Parameter werden alle Dateien bearbeitet.
[/Pfad] = die Bilder werden ab dem angegeben Pfad umbenannt. Auch einzelne Dateien sind möglich.
Bilder umbenennen mit kurzem Herstellernamen - Bash/Shell-Scipt - meine Empfehlung:
den folgenden Inhalt sollte man komplett in einer Script-Datei speichern & entsprechend als ausführbar kennzeichnen:
#!/bin/bash
# Im angegebenen Pfad alle jpg/jpeg Bilddateien (in beliebiger Schreibweise) suchen.
find /Pfad -type f
-iname "*.jpg" -o -iname "*.jpeg" | # Hier den Pfad und ggf. die Dateitypen anpassen.
while read img;
do
# $img = enhält den Pfad und den aktuellen Dateinamen.
echo -e "Datei:" "${img}"; # Optionale Anzeige des aktuellen Dateinamens.
# $marke = enthält den auf 4 Buchstaben gekürzten Herstellernamen.
marke=$(exiftool -TAG -Exif:Make "${img}" |
cut -d':' -f2 | cut -c2-5);
#
# Parametererklärungen:
# [exiftool -TAG -Exif:Make "${img}"] = Ermittelt den vollen Herstellernamen aus dem Exif-Tag (sofern vorhanden).
# [cut -d':' -f2] = Trennt die ermittelte Zeichenkette am Doppelpunkt ':' in 2 Spalten. Nur die 2. Spalte wird weitergereicht.
# [cut -c2-5)] = Schneidet von der Zeichenkette die Zeichen 2-5 aus. Das erste Zeichen enthält hier immer ein Leerzeichen.
# Der original Herstellername wird somit auf 4 Zeichen gekürzt (länger würde ich nicht empfehlen).
# Die 4 Zeichen sind meine Empfehlung, da einige Herstellernamen wirklich sehr lang sind.
#
# Hier mal ein paar Beispiele ('abgekürzte Version' und 'original Hersteller Kennung' vom Exif-Tag):
# Appl = Apple
# BQ = bq
# Cano = Canon
# EAST = EASTMAN KODAK COMPANY
# FUJI = FUJIFILM
# Huaw = Huawei
# KONI = KONICA MINOLTA DIGITAL CAMERA
# MOTO = Motorola
# NIKO = NIKON CORPORATION
# Noki = Nokia
# OLYM = OLYMPUS DIGITAL CAMERA
# Pana = Panasonic
# PENT = PENTAX
# sams = samsung
# SONY = SONY
# ... usw. Wie man sieht, ist die Herstellerkennung manchmal sehr kurz, manchmal sehr lang.
# Daher sollte man diese möglichst einkürzen (einheitliche Schreibweise).
# Da die Herstellerkennung in verschiedenen Schreibweisen vorhanden ist
# (teilweise sogar komplett klein geschrieben), sollte man diese umwandeln.
marke="${marke^^}"; # Den abgekürzten Herstellernamen in Großbuchstaben umwandeln (einheitliche Darstellung).
echo -e "Marke:" "${marke}"; # Optionale Anzeige des abgekürzten Herstellernamens.
# Wenn ein Herstellername gefunden wurde (also nur wenn die Variable 'marke' nicht leer ist),
# dann einen führenden Unterstrich '_' zur besseren Lesbarkeit der Dateinamen vorranstellen.
if ! [ "${marke}" == "" ];
then marke=_"${marke}"; fi;
# Dateien umbenennen. Entsprechende genauere Erläuterungen findet man im Kasten darüber. Hier wurde nur die abgekürzte Herstellerkennung ergänzt.
exiftool '-FileName<IMG_${DateTimeOriginal}%-c.%le' -d '%Y-%m-%d_%H.%M.%S'"${marke}" -r "${img}" -q -q;
# [-q -q] = unterdrückt Fehler und Warnungen. Diese treten z. B. bei Bildern ohne Exif-Informationen auf.
# Dateien ohne Metadaten Information werden nicht verändert, daher ist die Angabe hier unbedenklich.
# Alle Anführungszeichen, Hochkommas und Leerzeichen immer exakt so wie hier angegeben mit übernehmen.
echo -e "---------------------------"; # Optionale Ausgabe zur optischen Trennung.
done; # Ende der while Schleife.
# Das Script erzeugt Beispielsweise folgende Dateinamen:
# IMG_2019-02-09_08.10.00_APPL.jpg # Apple iPhone
# IMG_2019-02-09_08.15.00_BQ.jpg # BQ
# IMG_2019-02-09_09.45.30_SAMS.jpg # Samsung
# IMG_2019-02-09_16.00.00_PANA.jpg # Panasonic
# Ein derartig formatierter Dateiname ist wirklich leicht lesbar.
# Das Script wurde unter Ubuntu 16.04 bis 18.10 entwickelt und getestet.
# Versionsnummer: 2019-02-10 © ctaas.de
den original Dateisystem Zeitstempel, das 'Datum der letzten Änderung' (Geändert/Modifiziert) wiederherstellen:
Korrigiert das Datum im Dateisystem, rekursiv (empfohlen):
exiftool '-FileModifyDate<${DateTimeOriginal}' -r '/Pfad'
Das 'Datum der letzten Änderung' im Dateisystem wird auf das originale Erstellungsdatum aus dem Meta Tag (Exif) gesetzt.
Die Datei selbst wird dabei nicht verändert. Es wird nur das Dateidatum im Dateisystem entsprechend korrigiert.
Dies ist z. B. dann sinnvoll wenn das Aufnahmedatum durch verschieben oder kopieren im Dateisystem nicht mehr stimmt.
Das 'Datum der letzten Änderung' ist das Datum welches Standardmäßig im Dateisystem als aktuelles Datum angezeigt wird.
Bilder nach Datum in Ordner verschieben (einsortieren):
Die Bilder werden wie folgt in Unterordner verschoben (siehe Beispiel unten), der Dateiinhalt wird nicht verändert.
Variante A - nur nach Datum sortieren:
exiftool -ext jpg -ext jpeg '-Directory<${DateTimeOriginal}'
-d '/Pfad/Ziel/%Y/%m/%d' -r '/Pfad/Quelle/' # 2-mal den Pfad.
Variante B - meine Variante (empfohlen für größere Fotosammlungen, da besser lesbar):
exiftool -ext jpg -ext jpeg '-Directory<${DateTimeOriginal}'
-d '/Pfad/%Y/%m_%b/%d.%m.%y' -r '/Pfad/' # 2-mal den Pfad.
Wichtig: Beachtet hier, dass man den Pfad hier zweimal angegeben sollte. Den Pfad sollte man hier mit den abschließenden Backslashes '/' am Pfadende eingeben.
Lässt man den ersten Pfad weg, dann werden alle Bilder im aktuellen Script Ordner (also im aktuellen Pfad/von wo man den Aufruf gestartet hat) einsortiert.
Wenn man die Bilder im gleichen Ordner sortieren will (das ist sehr wahrscheinlich oft der Fall), dann gibt man hier einfach 2-mal den gleichen Pfad an.
Die Bilder werden dann im gleichen Ordner nach Jahren sortiert.
Ordner Beispiele:
Variante A - kurze Form:
2019/01/31/20080613_121300.jpg
Variante B - längere, aber besser lesbare Form (insbesondere wenn man in den einzelnen Unterordnern steht):
2008/06_Jun/13.06.08/20080613_121300.jpg
2019/01_Jan/31.01.19/20190131_231500.jpg
2019/02_Feb/28.02.19/20190228_093023.jpg
Parametererklärungen:
[-ext jpg] = (extension) bestimmt die zu durchsuchende Dateierweiterung. Die Option kann bei Bedarf auch mehrfach angegeben werden. Ohne dem Parameter werden alle Dateien bearbeitet.
['-Directory<${DateTimeOriginal}'] = Bilder anhand des Aufnahmedatums in entsprechende Unterverzeichnisse verschieben. Fehlende Verzeichnisse werden automatisch angelegt.
[-d] = (dateformat) bestimmt das Format des Datums.
[%Y] = (year) ist das Jahr als vierstellige Zahl.
[%y] = (year) ist das Jahr als zweistellige Zahl.
[%m] = (month) ist der Monat zweistellig als Zahl.
[%b] = ist der Monatsname in Kurzform (mit 3 Buchstaben).
[%B] = ist der ausgeschriebene Monatsname als Wort (alternative Variante).
[%d] = ist der Tag als zweistellige Zahl.
[/] = hier wird ein neues Unterverzeichnis angelegt.
[/Pfad] = Bilder aus dem angegeben Pfad werden in die entsprechenden Unterordner verschoben. Auch einzelne Dateien sind möglich.
ergänzende Hinweise:
Beim Verschieben kann es durchaus zu zahlreichen Warnungen und Hinweisen kommen (z. B. [Error: ...], [Warning ...] ... usw.). Diese kann man alle ignorieren.
exiftool meldet hierbei z. B. fehlerhafte oder fehlende Tags. Dateien die nicht verschiebbar sind (ohne Datum) bleiben einfach unverändert an ihrer originalen Stelle im Dateisystem.
Der Dateiinhalt wird hier (egal ob ok, oder ob Warnung/Fehler/Hinweis) nicht verändert.
Hierzu noch folgenden wichtigen ergänzenden Hinweis:
Im Anschluss muss man ggf. hier noch die Berechtigungen der Dateien anpassen.
Es kann sonst ggf. sein das man auf freigegebene Dateien keinen Zugriff mehr hat.
Beachten sollte man in dem Zusammenhang, dass für Freigaben über Samba immer zwei Rechte gelten.
Zum einen die in Samba definierten Rechte und die Rechte die auf Dateisystemebene definiert sind.
Insbesondere die Rechte innerhalb der Dateisystemebene können sich ggf. durch das verschieben durch das Skript verändern.
Mit diesem Befehl setzt man im Nachgang die Rechte für alle User.
Bei Freigaben im Netzt gelten dann nur noch die entsprechenden Samba Rechte:
chmod -R 777 '/Pfad/Ziel/' # Empfohlen: Den Pfad hier entsprechend anpassen.
chmod -R 777 /mnt/raid/DATA/Fotos_Videos_sortiert # Beispiel. Hinweis: Der Pfad enthält hier keine Leerzeichen, daher hier ausnahmsweise die Angabe ohne Hochkomma.
Tipp:
find '/Pfad' -type d -empty -print # Sucht alle leeren Verzeichnisse. Gibt die Pfade entsprechend auf der Standardausgabe aus.
find '/Pfad' -type d -empty -delete # Sucht und löscht alle leeren Verzeichnisse. Dies ist Hilfreich wenn man doch mal die Formatierung ändern möchte.
Verschieben der Aufnahmezeit:
Das Verschieben der Aufnahmezeit von einer Aufnahme, ist z. B. dann notwendig, wenn man im Urlaub eine Zeitverschiebung hatte.
Denn mit der Ankunft (z. B. nach der Landung mit einem Flugzeug) stimmt die Uhrzeit nicht mehr mit der lokalen Ortszeit überein.
Moderne Smartphones passen die Uhrzeit meist automatisch an, sodass man hier die Zeiten nicht verschieben muss.
Betroffen sind hier in der Regel also nur Fotoapparate und Kameras ohne GPS bzw. ohne automatischer Zeitumstellung.
folgendes stellt die Zeit 6 Stunden vor (die Zeit entsprechend anpassen):
exiftool '-overwrite_original' -ext jpg -ext jpeg
'-AllDates+=06:00' '/Pfad' # + Stunden.
folgendes stellt die Zeit 6 Stunden zurück (die Zeit entsprechend anpassen):
exiftool '-overwrite_original' -ext jpg -ext jpeg
'-AllDates-=06:00' '/Pfad' # - Stunden.
mehrere Jahre, Monate oder Tage zürückstellen:
exiftool '-overwrite_original' -ext jpg -ext jpeg
'-AllDates-=03:02:01 00:00' '/Pfad' # -3 Jahre, -2 Tage, -1 Tag, -0 Stunden und -0 Minuten.
folgendes stellt die Zeit nur bei Bildern des Herstellers 'Panasonic' zurück (auf einen beliebigen Hersteller anpassbar):
exiftool '-overwrite_original' -ext jpg -ext jpeg
'-AllDates-=06:00' -if '${Make} eq "Panasonic"' '/Pfad' # - Stunden, nur bei Hersteller ...
Hinweis: Die Leerzeichen, Anführungszeichen und Hockommas sollte man alle so wie hier gezeigt mit übernehmen.
Parametererklärungen:
[
-overwrite_original] = überschreibt die Originaldatei mit der veränderten Version. Ohne dem Parameter werden die Originaldateien umbenannt mit zusätzliche Dateiendung '
_original'.
[
-ext jpg] = (extension) bestimmt die zu durchsuchende Dateierweiterung. Die Option kann bei Bedarf auch mehrfach angegeben werden. Ohne dem Parameter werden alle Dateien bearbeitet.
[
-AllDates] = ist ein kürzel um die einzelnen Werte: '
DateTimeOriginal', '
CreateDate' und '
ModifyDate' alle gleichzeitig zu verändern.
Es wird hier also der 'Exif' Eintrag, das 'Datum der Erstellung' sowie das 'Datum der letzten Änderung' verändert.
[
-if '${Make} eq "Panasonic"'] = ist eine if (wenn) Abfrage. Die Datei wird nur verändert, wenn die Variable ${Make} den gleichen (eq = equal) Hersteller enthält wie der danach angegeben wurde.
[
/Pfad] = alle Dateien im angegebenen Pfad erhalten das gleiche Datum. Auch einzelne Dateien sind möglich.
Wichtig:
Im Nachgang sollte man noch das
Datum im Dateisystem und den
Dateinamen im Dateisystem korrigieren.
Hierzu noch folgender Tipp:
Um zukünftig das korrigieren des Datums zu vereinfachen, empfiehlt es sich immer mal eine Uhr zu Fotografieren.
Das heißt im Urlaub sollte man immer mal eine Uhr, sei es der Flugplan oder ähnliches Fotografieren.
Denn anhand dieser Aufnahme kann man dann leichter eine eventuelle Abweichung errechnen.
Bilder mit Copyrightvermerk kennzeichnen:
In allen jpg/jpeg Bildern im angegebenen Verzeichnis die folgenden Exif Tags hinzufügen bzw. verändern:
exiftool -P -overwrite_original -ext jpg -ext jpeg
'-Copyright=DEIN NAME, DEINE@E-MAIL.DE'
'-Comment=Dieses Bild ist urheberrechtlich geschützt.
Jede Art der Nutzung von Bildinhalten, insbesondere die Verwendung, Weitergabe und Vervielfältigung Bedarf der vorherigen schriftlichen Zustimmung.' '/Pfad'
Die Dateigröße ändert sich durch das hinzufügen bzw. verändern der Exif Tags.
Die das Bild an sich bleibt jedoch unverändert (die Qualität verändert sich nicht).
Parametererklärungen:
[-P] = (preserve) das originale Dateidatum bleibt erhalten. Das 'Datum der letzten Änderung' im Dateisystem wird nicht verändert.
Der Zeitpunkt der Aufnahme ist dann immer noch am Dateidatum ablesbar (man sollte diesen Parameter daher hier immer mit angeben).
[-overwrite_original] = überschreibt die Originaldatei mit der veränderten Version. Ohne dem Parameter werden die Originaldateien umbenannt mit zusätzliche Dateiendung '_original'.
[-Copyright] und [-Comment] = sind entsprechende Exif Tags, diese werden hinzugefügt, bzw. entsprechend verändert (der Name, die E-Mailadresse und der Text kann natürlich beliebig verändert werden).
Aufnahmedatum/Exif verändern:
Vorsicht: Der 'Exif' Eintrag wird verändert (dies ist normalerweise nur in besonderen Fällen notwendig):
exiftool '-AllDates=20001231 12:30:00'
'-overwrite_original' -ext jpg '/Pfad'
Parametererklärungen:
[-AllDates] = ist ein kürzel um die einzelnen Werte: 'DateTimeOriginal', 'CreateDate' und 'ModifyDate' alle gleichzeitig zu verändern.
Es wird hier also der 'Exif' Eintrag, das 'Datum der Erstellung' sowie das 'Datum der letzten Änderung' verändert.
[20001231 12:30:00] = ist hier der 31.12.2000 um 12:30 Uhr. Das Datum muss exakt so in diesem Format angegeben werden.
[-overwrite_original] = überschreibt die Originaldatei mit der veränderten Version. Ohne dem Parameter werden die Originaldateien umbenannt mit zusätzliche Dateiendung '_original'.
[-ext jpg] = (extension) Bestimmt die zu durchsuchende Dateierweiterung. Die Option kann bei Bedarf auch mehrfach angegeben werden. Ohne dem Parameter werden alle Dateien bearbeitet.
[/Pfad] = alle Dateien im angegebenen Pfad erhalten das gleiche Datum. Auch einzelne Dateien sind möglich.
37. Bilder konvertieren: bmp in png umwandeln (mit ImageMagick):
Im angegebenen Pfad alle .bmp Dateien in .png Dateien konvertieren (auch rekursiv). Benötigt ein installiertes ImageMagick:
apt update; apt install imagemagick
find /Pfad -type f -name "*.bmp" | while read img;
do echo "$img";
convert "$img" "${img%.bmp}.png";
rm "$img"; done
Bei dieser einfachen Variante werden nur Dateien mit kleingeschriebener Dateiendung konvertiert.
Bereits bestehende .png Dateien werden ohne Rückfrage überschrieben.
Wichtig: Dieses Script enthält keine Fehlerbehandlung.
Das nachfolgende Script konvertiert auch Dateien mit groß geschriebener Dateiendung .bmp, .BMP, .Bmp, usw. in .png Dateien.
Dort werden dann auch vorhandene .png Dateien übersprungen und ggf. auftretende Fehler berücksichtigt. Die folgende Variante wird daher bevorzugt empfohlen.
ImageMagick installieren:
apt install imagemagick
zum Umwandeln der Dateien ein neues Script anlegen:
nano bmp_in_png.sh
Hier dann folgendes einfügen (Pfad anpassen nicht vergessen):
#!/bin/bash
# image_convert = ist eine selbstdefinierte Funktion für die Konvertierung. Die Funktion muss am Anfang im Script stehen.
image_convert() {
echo -e "Konvertiere:" "$2";
convert "$1" "$2"; # Dies ist die eigentliche Konvertierung mittels ImageMagick.
# $1 = ist der zuerst übergebene Parameter (der Pfad und der Name zur Originaldatei).
# $2 = ist der zweite übergebene Parameter (der Pfad und der Name zur Zieldatei).
# Prüfen ob die Zieldatei korrekt erzeugt wurde.
if [ -f "$2" ] # Wichtig: Die Leerzeichen so mit übernehmen.
then # Wenn die neue Datei existiert, dann ...
echo -e "OK: Die neue konvertierte Datei wurde erzeugt.";
# rm -fv "$1"; # Die Originaldatei wird nur gelöscht, wenn man hier die führende Raute '#' entfernt.
else # Fehlerausgabe, nur falls das konvertieren fehlgeschlagen ist (Berechtigungsprobleme/keine Schreibrechte u. ä.).
echo -e "\n############\nFehler.....:" "${img}" "\nDie Datei wurde nicht konvertiert, die Originaldatei bleibt bestehen.\n";
fi; # Ende der if Schleife.
} # Ende der Funktion.
# Alle '.bmp' Dateien suchen. Die Groß- und Kleinschreibung wird dabei nicht beachtet.
# Wenn man andere Dateiformate konvertieren möchte, dann hier .bmp entsprechend anpassen.
find "/Pfad" -type f -iname "*.bmp" | # Den Pfad entsprechend anpassen.
while read img; # while, do, done Schleife - durchlauf über alle Gefundenen Dateien.
do
# $img = enthält den Pfad und den kompletten original Dateinamen (beliebige Groß- und Kleinschreibung).
# Variablen definieren für die Dateinamen - hier sollte man nichts ändern.
# $ext_org = enthält die original Dateiendung.
ext_org="${img##*.}"; # Enthält z. B. 'BMP', 'bmp', 'Bmp' (in beliebiger Schreibweise).
# $file_path = enthält den Pfad zur aktuellen Datei.
file_path=$(dirname "${img}");
# $file_name = enthält den Dateinamen ohne Pfad & ohne Dateiendung. Also z. B. 'IMG_190131_164530'.
file_name=$(basename "$img" .${ext_org}); # Der Punkt '.' und die original Dateiendung wird entfernt.
# $new_name = enthält den Pfad und den Dateinamen mit der neuen Dateiendung .png.
new_name=${file_path}/${file_name}.png;
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.png' - ohne original Dateiendung, stattdessen mit .png.
# Optionale Ausgaben zur Kontrolle.
# Den Pfad und den originalen Dateinamen ausgeben.
echo -e "" # Leerzeile zur Trennung der einzelnen Dateien.
echo -e "img........:" "${img}";
# Den Pfad und den Dateinamen mit der neuen Dateiendung ausgeben.
echo -e "new_name...:" "${new_name}";
# Prüfen ob schon eine konvertierte Datei vorhanden ist. Diese Prüfung kann man ggf. weglassen.
if [ -f "${new_name}" ]; # Wichtig: Die Leerzeichen so mit übernehmen.
then echo -e "Eine konvertierte Datei ist bereits vorhanden, die Datei wird daher übersprungen.";
else echo -e "Starte Konvertierung:";
image_convert "${img}" "${new_name}"; # Aufruf der oben definierten Funktion (mit Parameterübergabe, zwei Pfade und Dateinamen).
# Prüft man die Existenz der Zieldatei nicht vorab, dann wird diese überschrieben.
fi; # Ende der if Schleife.
done; # Ende der while Schleife.
# Das Script wurde unter Ubuntu 16.04 bis 18.10 entwickelt und getestet.
# Versionsnummer: 2019-01-27 © ctaas.de
Das Script ausführbar machen:
chmod +x bmp_in_png.sh
Das Script kann man nun wie folgt starten:
./bmp_in_png.sh
38. Bilder konvertieren: jpg/jpeg & png in webp umwandeln (mit cwebp):
WebP [GitHub] (mirrow) ist das neue Bildformat, das besonders für Webserver empfohlen wird.
Im angegebenen Pfad alle .png Dateien in .webp Dateien konvertieren (auch rekursiv). Benötigt ein installiertes webp:
apt install webp
find /Pfad -type f -name "*.png" | while read img;
do echo "$img";
cwebp "$img" -o "${img%.png}.webp" -z 9;
rm "$img"; done
Hinweis: Das Script kann auch verwendet werden um .jpg in .webp Dateien umzuwandeln (einfach .png durch .jpg ersetzen).
Bei dieser einfachen Variante werden nur Dateien mit kleingeschriebener Dateiendung konvertiert.
Bereits bestehende .webp Dateien werden ohne Rückfrage überschrieben.
Wichtig: Dieses Script enthält keine Fehlerbehandlung.
cwebp Parametererklärungen:
[-lossless] = verlustfreie Komprimierung, insbesondere für .png Dateien, insbesondere für flächige Logos.
[-z 9] = verlustfreie Komprimierung, höchste Kompression insbesondere für .png Dateien, empfohlen insbesondere für flächige Logos.
[-near_lossless 100] = alternative verlustbehaftete Komprimierung (Qualitätsangabe von 0-100/hohe Qualität).
[-q 100] = alternative verlustbehaftete Komprimierung - eine Qualitätsangabe von 0-100 ist möglich, '82' ist meine Empfehlung für jpg Dateien.
[rm "$img"] = Vorsicht dieses löscht das Originalbild (optional).
Das nachfolgende Script konvertiert auch Dateien mit groß geschriebener Dateiendung .png, .PNG, .Jpg, usw. in .webp Dateien.
Vorhandene Dateien werden übersprungen (kann man deaktivieren) und ggf. auftretende Fehler werden berücksichtigt. Die folgende Variante wird daher bevorzugt empfohlen.
cwebp installieren:
apt install webp
zum Umwandeln der Dateien ein neues Script anlegen:
nano png_jpg_in_webp.sh
hier dann folgendes einfügen (Pfad anpassen nicht vergessen):
#!/bin/bash
# Script-Beschreibung: Konvertiert jpg, jpeg & png in webp, optimierte Qualität & Größe, ideal für Internet-Webserver, Apps u. ä.
# 1. image_convert = ist eine selbstdefinierte Funktion für die Konvertierung. Die Funktion muss am Anfang im Script stehen.
image_convert() {
# Bilder bzw. Fotos können aber sehr verschieden sein.
# Ein flächiges Logo mit wenig Farben bwz. einfarbigen Flächen lässt sich meist verlustfrei/lossless besser packen,
# als Beispielsweise ein Foto von ein einer bunten Wiese. Letzteres lässt sich verlustbehaftet/lossy besser packen.
# Aus diesem Grund erzeugt das folgende Script immer zuerst beide Varianten (lossless und lossy) und vergleicht diese im Anschluss.
# So wird immer die optimalste/kleinstmögliche Variante behalten.
echo -e "Konvertiere lossless Variante (png/Logos):";
cwebp "$1" -o "$2.lossless" -z 9 -progress -mt -v; # Dies ist die eigentliche Konvertierung mittels cwebp (verlustfrei für Logos u. ä.).
check_size "$2.lossless"; # Auf 0 Byte Dateigröße prüfen.
echo -e "Konvertiere lossy Variante (jpg/Fotos):"; # Hier ggf. bei Bedarf die Qualität anpassen.
cwebp "$1" -o "$2.lossy" -q 82 -progress -mt -pass 10 -m 6; # Dies ist die eigentliche Konvertierung mittels cwebp (verlustbehaftet für Fotos).
check_size "$2.lossy"; # Auf 0 Byte Dateigröße prüfen.
# $1 = ist der zuerst übergebene Parameter (der Pfad und der Name zur Originaldatei).
# $2 = ist der zweite übergebene Parameter (der Pfad und der Name zur Zieldatei).
# -z 9 = bestimmt die Qualität bei verlustfreier/lossles Komprimierung (0 - 9), der Wert 9 ist die beste Komprimierung.
# -q 82 = bestimmt die Qualität bei verlustbehafteter/lossy Komprimierung (0 - 100), der Wert 82 ist meine Empfehlung (Standard 75).
# Die Qualität kann man bei Bedarf entsprechend anpassen (Parameter).
# -mt = multi-threading (falls verfügbar) dies beschleunigt ggf. die Kompression.
# -pass 10 = gibt die Anzahl der Encoding durchläufe an. Höhere Werte können die Bildqualität bei niedrigen Bitraten verbessern.
# -m 6 = gibt die Stärke der Kompressionsmethode an. Achtung wichtig: Der Parameter darf nur bei der lossy (verlustbehafteten) Kompression genutzt werden.
# -progress = zeigt in % an wie weit die Komprimierung bereits fortgeschritten ist (optional).
# -v = aktiviert eine detallierte Ausgabe gibt unter anderem die Zeitdauer aus (optional).
# Welche Datei ist kleiner, lossless oder lossy?
if [ $(stat -c%s "$2.lossless") -le $(stat -c%s "$2.lossy") ]; then # Wenn $2.lossless kleiner oder gleich (less or equal) als $2.lossy ist dann,
echo "Die lossless Datei ist kleiner, lösche die nicht benötigte lossy Datei.";
rm -fv "$2.lossy"; mv -v "$2.lossless" "$2"; # die größere $2.lossy Datei löschen & die $2.lossless Datei als neue Zieldatei $2 benennen.
else # Wenn nicht dann,
echo "Die verlustbehaftete Datei ist kleiner, lösche die nicht benötigte lossless Datei.";
rm -fv "$2.lossless"; mv -v "$2.lossy" "$2"; # die größere $2.lossless Datei löschen & die $2.lossy Datei als neue Zieldatei $2 benennen.
fi;
# Es bleibt also nur eine Datei (die kleinere von beiden) übrig, entweder verlustfrei/lossles oder verlustbehaftet/lossy.
# Prüfen ob die Zieldatei korrekt erzeugt wurde.
if [ -f "$2" ] # Wichtig: Immer alle Leerzeichen bei den if Anweisungen mit übernehmen.
then # Wenn die neue Datei existiert, dann ...
echo -e "OK: Die neue konvertierte Datei wurde erzeugt.";
# Dateigrößen für die original Datei und die konvertierte Datei ermitteln:
size1=$(stat -c%s "$1");
size2=$(stat -c%s "$2");
# Prüfen ob die neue Datei kleiner oder gleich groß ist.
if [ "${size1}" -le "${size2}" ]; then # Wenn die Originaldatei $1 kleiner oder leich (less or equal) groß ist wie die neue Datei $2, dann folgende Meldung ausgeben.
echo -e "\n############\nGrößer.....:" "$2" "\nDie konvertierte Datei ist größer oder gleich groß, die Originaldatei bleibt bestehen.\n";
rm -fv "$2"; # Die konvertierte (größere/gleich große Datei) wird automatisch gelöscht, denn es sollen ja möglichst nur kleine Dateien im Web sein.
return 0; # Wichtig: Die Funktion vorab zu beenden ist wichtig, damit die Originaldatei bestehen bleibt.
fi;
# rm -fv "$1"; # Die Originaldatei wird nur gelöscht, wenn man hier die führende Raute '#' entfernt.
else # Fehlerausgabe, nur falls das konvertieren fehlgeschlagen ist (Berechtigungsprobleme/keine Schreibrechte u. ä.).
echo -e "\n############\nFehler.....:" "${img}" "\nDie Datei wurde nicht konvertiert, die Originaldatei bleibt bestehen.\n";
fi; # Ende der if Schleife.
} # Ende der Funktion.
# 2. check_size = ist eine selbstdefinierte Funktion zur Prüfung ob die Datei 0 Byte groß ist. Fehlerbehandlung bei zu großen Bildern.
check_size () {
# Wichtig:
# Der errorlevel/return code [echo $?;] von cwebp ist immer Null '0', auch bei Fehlern (das ist ein bug bis mind. Version 1.0.2).
# Daher kann man den errorlevel nicht dazu verwenden um zu überprüfen, ob die Konvertierung geklappt hat (bug 1).
# Probleme bereiten insbesondere Bilder mit einer Breite oder Höhe über 16383 Pixeln.
# Wenn man versucht eine zu große Bilddatei zu konvertieren, entsteht eine nur "0 Byte" große Datei (bug 2).
# Prüfen auf 0 Byte Datei und ggf. diese löschen (große Bilder bug abfangen).
if [ $(stat -c%s "$1") -eq 0 ]; then # Wenn die Dateigröße der Datei die an die Funktion übergeben wurde (gleich/equal) 0 ist dann,
rm -fv "$1"; # die 0 Byte Datei löschen.
echo -e "\n############\nFehler.....:" "\nDie Datei wurde nicht konvertiert da sie ist zu groß ist (über 16383 Pixel), die Originaldatei bleibt bestehen.\n";
fi;
} # Ende der Funktion.
# Maximale Bildgrößen: webp/vp8 bitstream = 16383x16383 Pixel, jpeg = 65535x65535 Pixel, png = keine Grenzen, wird durch den RAM begrenzt.
# 3. Alle 'png/jpg/jpeg' Dateien suchen. Die Groß- und Kleinschreibung wird dabei nicht beachtet.
find /Pfad -type f -iname "*.png"
-o -iregex ".*\.jpe?g" | # Den Pfad und die Dateitypen entsprechend anpassen.
# Regex Erklärungen:
# '.' = der Punkt entspricht einem beliebigen Zeichen. '.*' bedeutet eine beliebige Zeichenfolge.
# '\' = hebt die Bedeutung des danach folgenden Zeichens auf. '\.' bedeutet also nur der '.' Punkt.
# Der Punkt wird also durch den Backslash maskiert, damit er nicht als beliebiges Zeichen erkannt wird.
# '?' = das Fragezeichen bedeutet, dass das davor stehende Zeichen ggf. vorkommen kann.
while read img; # while, do, done Schleife - durchlauf über alle Gefundenen Dateien.
do
# $img = enthält den Pfad und den kompletten original Dateinamen (beliebige Groß- und Kleinschreibung).
echo "___________________________"; # Optische Trennung der einzelnen Konvertierungen.
# Variablen definieren für die Dateinamen - hier sollte man nichts ändern.
# $ext_org = enthält die original Dateiendung.
ext_org="${img##*.}"; # Enthält z. B. 'PNG', 'Jpg', 'jpeg' (in beliebiger Schreibweise).
# $smal_ext = enthält die original Dateiendung im kleingeschriebenen Format.
smal_ext="${ext_org,,}"; # enthält also entweder 'png', 'jpg' oder 'jpeg'.
# $file_path = enthält den Pfad zur aktuellen Datei.
file_path=$(dirname "${img}");
# $file_name = enthält den Dateinamen ohne Pfad & ohne Dateiendung. Also z. B. 'IMG_190131_164530'.
file_name=$(basename "$img" .${ext_org}); # Der Punkt '.' und die original Dateiendung wird entfernt.
# $new_name = enthält den Pfad und den Dateinamen mit der neuen Dateiendung.
# Achtung: Hier nur eine Variante entsprechend auskommentieren (aktivieren).
# new_name=${file_path}/${file_name}.webp; # = Pfad, Dateiname und nur die Endung .webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.webp' - ohne original Dateiendung, stattdessen mit .webp.
# new_name=${file_path}/${file_name}.${ext_org}.webp; # = Pfad, Dateiname, original Dateierweiterung und .webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.JPG.webp' - mit unveränderter original Dateiendung und .webp.
new_name=${file_path}/${file_name}.${smal_ext}.webp; # = Pfad, Dateiname, kleingeschriebene original Dateierweiterung und .webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.jpg.webp'. - immer mit kleiner Dateiendung/einheitliche Dateinamen (empfohlen).
# Optionale Ausgaben zur Kontrolle.
# Den Pfad und den originalen Dateinamen mit einer Leerzeile zur Trennung ausgeben.
echo -e "\nimg........:" "${img}";
# Den Pfad und den Dateinamen mit der neuen Dateiendung ausgeben.
echo -e "new_name...:" "${new_name}";
# 4. Prüfen ob schon eine konvertierte Datei vorhanden ist. Diese Prüfung kann man ggf. weglassen.
if [ -f "${new_name}" ]; # Wichtig: Die Leerzeichen so mit übernehmen.
then echo -e "Eine konvertierte Datei ist bereits vorhanden, die Datei wird daher übersprungen.";
else echo -e "Starte Konvertierung:";
image_convert "${img}" "${new_name}"; # Aufruf der oben definierten Funktion (mit Parameterübergabe, zwei Pfade und Dateinamen).
# Prüft man die Existenz der Zieldatei nicht vorab, dann wird die bereits bestehende Datei ohne Rückfrage überschrieben.
fi; # Ende der if Schleife.
done; # Ende der while Schleife.
# Das Script wurde unter Ubuntu 16.04 bis 19.04 entwickelt und getestet.
# Version: 2019-09-25 © ctaas.de
Das Script ausführbar machen:
chmod +x png_jpg_in_webp.sh
Das Script kann man nun wie folgt starten:
./png_jpg_in_webp.sh
webp unter Ubuntu/Debian kompilieren:
WebP wird derzeit noch häufig verbessert, wer eine aktuelle Version verwenden will sollte daher wie folgt den Quellcode selbst übersetzen:
Notwendige Compilertools (g++) und Bibliotheken für .jpeg, .png, .tiff und .gif Dateien installieren:
apt install build-essential libpng-dev libjpeg-dev libtiff-dev libgif-dev freeglut3-dev libsdl1.2-dev
Hinweise: Ohne die 'gelb' hervorgehobenen Parameter wird nur cwebp und dwebp kompiliert (
libsdl.org).
Die neuere Version libsdl2-dev (2.x) wird aktuell nicht unterstützt - verwendet wie hier im Script angegeben die ältere libsdl1.2-dev (1.x) Bibliothek.
Die aktuelle Version herunterladen (
den Link entsprechend anpassen):
wget https://storage.googleapis.com/
downloads.webmproject.org/
releases/webp/libwebp-1.5.0.tar.gz
Das herunter geladene Archiv entpacken (die Version anpassen):
tar xvzf libwebp-1.5.0.tar.gz # 1.5.0 = ist die Version vom 20.12.2024.
Ins Quellverzeichnis wechseln (die Version anpassen):
cd libwebp-1.5.0
Und das Programm kompilieren:
./configure --enable-libwebpmux --enable-libwebpdemux --enable-libwebpdecoder --enable-libwebpextras
Hinweise: Der Parameter:
--enable-libwebpencoder wird im aktuellen Release nicht mehr benötigt, der Parameter wurde daher entfernt.
Wenn Sie ein älteres Release kompilieren möchten dann sollten Sie den Parameter ggf. entsprechend ergänzen.
Das Eingabe- (Input) und Ausgabe-Format (Output) WIC (Windows Imaging Component) wird nicht mit kompiliert (dies ist nur für Windows).
make
make install # Erzeugt die Programme:
anim_diff, anim_dump, cwebp, dwebp, gif2webp, img2webp, vwebp, webpinfo, webpmux.
Hinweis: Die Programme: anim_diff und anim_dump starten aktuell (Stand Version 1.5.0) nur mit voller Pfadangabe. Verwendet für diese Programme ggf. einen
Alias.
Dynamische Links (shared libraries/Funktionsbibliotheken) aktualisieren:
ldconfig /usr/local/lib/
Hinweise: Ohne der Aktualisierung der Libraries kommt es ggf. zu dem Fehler:
[
cwebp: error while loading shared libraries: libwebp.so.7: cannot open shared object file: No such file or directory]
Nach der Aktualisierung der Libraries sind alle soeben kompilierten Programme sofort systemweit verfügbar.
Sofern Sie die Programme aufgrund meiner Dokumentation aktualisieren sollten Sie ggf. alte Versionen und insbesondere
Aliase in der Datei ~/
.bash_profile entfernen.
Die fertig ausführbaren Programme liegen in dem
example Verzeichnis (die Version anpassen):
libwebp-1.5.0/examples/cwebp #
Parameter-Dokumentation, cwebp zum packen.
libwebp-1.5.0/examples/dwebp #
Parameter-Dokumentation, dwebp zum entpacken.
Version: 2022-05-23
webp in png zurück konvertieren:
dwebp image.webp -o image.png # (decompress) WebP Images in ein anderes Format umwandeln.
Ergänzende Befehle zum webm Projekt (open web media project):
Konvertiert gif Dateien (auch animierte) ins webp Format (zum Script):
gif2webp -min_size Datei.gif -o Datei.gif.webp
Erzeugt von einer Bildersequenz eine webp Animation:
img2webp -min_size -mixed -m 6 -loop 10 -d 3000
Bild01.png Bild02.png Bild03.png Bild04.png
-o Animation.webp
= Lossy-mixed/verlustbehaftete Kompression (für Animationen als Alternative).
img2webp -min_size -d 10000
Bild*.png
-o Animation.webp
= Mehrere Bilder (z. B. Bild01.png ... Bild99.png) kann man einfach mit einem Joker ('*' oder '?') übergeben.
Lossless/verlustfrei - beste Qualität (für Logos empfohlen).
Parametererklärungen für gif2webp und img2webp:
[-min_size] = erzeugt die kleinstmögliche Datei (packt am besten). Den Parameter sollte man daher immer mit angeben.
[-mixed] = bestimmt heuristisch für jedes Frame der Animation ob dieses lossless/verlustfrei oder lossy/verlustbehaftet komprimiert wird.
Den Parameter -min_size sollte man bei -mixed trotzdem mit angeben, denn dieser wird dann bei den ggf. verlustfrei komprimierbaren Frames berücksichtigt.
[-m 6] = bestimmt die Kompressionsmethode/Stärke von 0 = schnell bis 6 = langsam. Die Stufe 6 packt dabei in der Regel immer am besten.
[-lossy] = optionale verlustbehaftete Komprimierung (die verlustfreie Komprimierung ist Standard).
[-q] = (quality) bestimmt die Qualität bei verlustbehafteter Komprimierung (1-100 ist möglich, 75 ist Standard). Der Parameter wird nicht empfohlen.
[-o] = (output) bestimmt den Dateinamen für die konvertierte Datei.
Parametererklärungen für img2webp:
[-loop 10] = bestimmt die Anzahl der Durchläufe
(0 = ist unendlich/ist Standard). Den Parameter muss man also nur angeben, wenn man die Durchlaufzahl begrenzen will (hier z. B. 10).
[-d 3000] = (duration) bestimmt die Wartezeit in Millisekunden (3000 ms = 3 Sekunden).
39. Bilder konvertieren: gif Bilder & gif Animationen in webp umwandeln (mit cwebp):
WebP [GitHub] (mirrow) ist das neue Bildformat, das besonders für Webserver empfohlen wird.
Benötigt ein installiertes webp:
apt install webp
gif Dateien (Bilder & Animationen) automatisiert in webp umwandeln.
#!/bin/bash
# Script-Beschreibung: Konvertiert gif Bilder/Animationen in webp, optimierte Qualität & Größe, ideal für Internet-Webserver, Apps u. ä.
# 1. check_size = ist eine selbstdefinierte Funktion für den Größenvergleich. Die Funktion muss am Anfang im Script stehen.
check_size() {
# Übergeben wird folgendes: $1 = ist die original Datei, $2 = ist die neu konvertierte Datei, $3 = enthält den Text-String 'lossless' oder 'lossy-mixed'.
# Dateigrößen der 2 übergebenen Dateien ermitteln.
size1=$(stat -c%s "$1");
size2=$(stat -c%s "$2");
# Prüfen ob die neue Datei kleiner ist.
if [ "${size1}" -lt "${size2}" ]; then # Wenn die Originaldatei $1 kleiner ist (less than) als die neue Datei $2, dann folgende Meldung ausgeben.
echo -e "\nHinweis:\nLösche die konvertierte" "$3" "Datei, da sie größer als das Original ist.\nDie Originaldatei bleibt unverändert bestehen.";
rm -fv "$2"; # Die konvertierte (größere Datei) wird automatisch gelöscht, denn es sollen ja möglichst nur kleine Dateien im Web sein.
fi; # Ende der if Schleife.
} # Ende der Funktion.
# 2. Alle 'gif' Dateien im Pfad suchen. Die Groß- und Kleinschreibung wird dabei nicht beachtet.
find /Pfad -type f -iname "*.gif" | # Den Pfad und die Dateitypen entsprechend anpassen.
while read img; # while, do, done Schleife - durchlauf über alle gefundenen Dateien.
do
# $img = enthält den Pfad und den kompletten original Dateinamen (beliebige Groß- und Kleinschreibung).
echo "___________________________"; # Optische Trennung der einzelnen Konvertierungen.
# Variablen definieren für die Dateinamen - hier sollte man nichts ändern.
# $ext_org = enthält die original Dateiendung.
ext_org="${img##*.}"; # Enthält z. B. 'GIF', 'Gif', 'gif' (in beliebiger Schreibweise).
# $smal_ext = enthält die original Dateiendung im kleingeschriebenen Format.
smal_ext="${ext_org,,}"; # enthält hier immer 'gif'. Man könnte hier auch 'smal_ext="gif"' verwenden. Bei verschiedenen Eingangsformate sollte man aber diese Funktion verwenden.
# $file_path = enthält den Pfad zur aktuellen Datei.
file_path=$(dirname "${img}");
# $file_name = enthält den Dateinamen ohne Pfad & ohne Dateiendung. Also z. B. 'IMG_190131_164530'.
file_name=$(basename "$img" .${ext_org}); # Der Punkt '.' und die original Dateiendung wird entfernt.
# $new_name = enthält den Pfad und den Dateinamen mit der neuen Dateiendung.
# Achtung: Hier nur eine Variante entsprechend auskommentieren (aktivieren).
# new_name=${file_path}/${file_name}.webp; # = Pfad, Dateiname und nur die Endung .webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.webp' - ohne original Dateiendung, stattdessen mit .webp.
# new_name=${file_path}/${file_name}.${ext_org}.webp; # = Pfad, Dateiname, original Dateierweiterung und .webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.GIF.webp' - mit unveränderter original Dateiendung und .webp.
new_name="${file_path}/${file_name}.${smal_ext}.webp"; # = Pfad, Dateiname, kleingeschriebene original Dateierweiterung und .webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.gif.webp'. - immer mit kleiner Dateiendung/einheitliche Dateinamen (empfohlen).
# $new_name_mixed = enthält einen separaten Namen für lossy-mixed/verlustbehaftete Kompression (als Alternative).
new_name_mixed="${file_path}/${file_name}.${smal_ext}.lossy-mixed.webp"; # = Pfad, Dateiname, kleingeschriebene original Dateierweiterung und .lossy-mixed.webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.gif.lossy-mixed.webp'. - immer mit kleiner Dateiendung/einheitliche Dateinamen (empfohlen).
# Prüfen ob schon eine konvertierte Datei vorhanden ist. Diese Prüfung kann man ggf. weglassen.
# Prüft man die Existenz der Zieldatei nicht vorab, dann wird die bereits bestehende Datei ohne Rückfrage überschrieben.
if [ -f "${new_name}" ] || [ -f "${new_name_mixed}" ]; # Prüfen ob eine Datei lossy-Datei oder (||) eine lossy-mixed Datei vorhanden ist.
then echo -e "Eine konvertierte Datei für :" "${file_name}.${ext_org}" "\nist bereits vorhanden, die Datei wird daher übersprungen.";
continue; # Die while-do Schleife mit der nächsten Datei fortsetzen (das Konvertieren wird übersprungen).
# else echo -e "Starte Konvertierung:"; # Kommentar fürs Debug.
fi; # Ende der if Schleife.
echo -e "Konvertiere lossless/verlustfrei - für Logos - beste Qualität (empfohlen):";
gif2webp "${img}" -min_size -o "${new_name}";
# -o = (output) Name der Zieldatei.
# gif2webp erzeugt ohne zusätzliche Parameter eine optimierte lossless/verlustfreie Datei. Derzeit ist keine weitere Optimierung möglich.
# Wichtig: Zusätzliche Parameter schalten in der Regel immer in eine lossy/verlustbehaftete Kompression um.
check_size "${img}" "${new_name}" "lossless";
echo -e "\nKonvertiere lossy-mixed/verlustbehaftet - für Animationen - hohe Kompression (als Alternative):";
gif2webp "$img" -min_size -m 6 -mixed -o "$new_name_mixed";
# -min_size = eine kleine Ausgabegröße erzeugen.
# -m 6 = bestimmt die Kompressionsmethode/Stärke von 0 = schnell bis 6 = langsam. Die Stufe 6 packt dabei in der Regel immer am besten.
# -mixed = bestimmt heuristisch für jedes Frame (insbesondere bei Animationen) ob dieses lossless/verlustfrei oder lossy/verlustbehaftet komprimiert wird.
# Die Parameter '-min_size -m 6 -mixed' empfehle ich für die lossy/verlustbehafteter Kompression, da die Ausgabedatei noch eine relativ gute Qualität hat.
# Alternativer Parameter:
# -q 95 = bestimmt die Qualität von 0 = klein bis 100 = groß. Die Dateien werden durchaus noch kleiner, allerdings bei deutlich schlechterer Qualität (nicht empfohlen).
check_size "${img}" "${new_name_mixed}" "lossy-mixed";
# Prüfungen wenn bei beiden Konvertierungen "lossless/verlustfrei" und "lossy-mixed/verlustbehaftet" Dateien erzeugt wurden.
# 3. Prüfung: beide gleich groß?
if [ -f "${new_name}" ] && [ -f "${new_name_mixed}" ]; # Wenn beide Dateien (lossless und lossy-mixed) vorhanden sind, dann ...
then
# Dateigrößen für die original Datei und die konvertierte Datei ermitteln:
size1=$(stat -c%s "${new_name}");
size2=$(stat -c%s "${new_name_mixed}");
# Prüfen ob die Dateien gleich groß sind (insbesondere bei kleinen, einfachen Dateien tritt dieses Symtom auf).
if [ "${size1}" == "${size2}" ]; then # Wenn die Originaldatei gleich groß (==) wie die neue Datei ist, dann folgende Meldung ausgeben.
echo -e "\nHinweis:\nDie konvertierten Dateien lossless & lossy-mixed sind gleich groß.\nDie nicht benötigte lossy-mixed Datei wird gelöscht. Die Originaldatei bleibt bestehen.";
rm -fv "${new_name_mixed}"; # Die überflüssige (gleich große Datei) lossy-mixed wird automatisch gelöscht, eine kleine Datei reicht ja aus.
fi; # Ende der if Schleife.
fi;# Ende der if Schleife.
# 4. Prüfung: lossless kleiner als lossy?
if [ -f "${new_name}" ] && [ -f "${new_name_mixed}" ]; # Wenn beide Dateien (lossless und lossy-mixed) vorhanden sind, dann...
then
# Dateigrößen für die original Datei und die konvertierte Datei ermitteln:
size1=$(stat -c%s "${new_name}");
size2=$(stat -c%s "${new_name_mixed}");
# Prüfen ob die "Verlustfreie lossless" Datei kleiner ist als die "Verlustbehaftete lossy-mixed" Datei.
if [ "${size1}" -lt "${size2}" ]; then # Wenn die lossless Datei kleiner als (less than) die lossy-mixed Datei ist, dann ...
echo -e "\nHinweis:\nDie konvertierte verlustbehaftete lossy-mixed Datei ist größer als die verlustfreie lossless Datei.";
echo -e "Die nicht benötigte lossy-mixed Datei wird gelöscht. Die Originaldatei bleibt bestehen.";
rm -fv "${new_name_mixed}"; # Die überflüssige (gleich große Datei) lossy-mixed wird automatisch gelöscht, eine kleine Datei reicht ja aus.
fi; # Ende der if Schleife.
fi; # Ende der if Schleife.
# sleep 40; clear; # Pause für Debugzwecke.
done; # Ende der while Schleife.
# Das Script wurde unter Ubuntu 16.04 bis 19.04 entwickelt und getestet.
# Version: 2019-06-26 © ctaas.de
WebP wird derzeit noch häufig verbessert, wer eine aktuelle Version verwenden will sollte daher wie folgt den Quellcode selbst übersetzen.
40. heif-convert (libheif) die Bildformate: .avif, .heic, .heif, .png, .jpg untereinander konvertieren/umwandeln:
Das neue HEIC Format begegnet einem spätestens seit dem es Apple auf dem iPhone und Mac Computer häufiger verwendet immer öfter.
Wer diese Bilder nicht weiter verwenden kann muss diese HEIC/HEIF Dateien in png/jpg konvertieren.
Auch das neue .avif Bildformat wird immer häufiger auftauchen.
Ich möchte euch hier zeigen wie man Bilder zwischen den verschiedenen Formaten einfach umwandeln kann.
Zum Konvertieren von Bildern kann man z. B. die auf libheif basierenden Programme heif-convert bzw. heif-enc verwenden.
Wichtiges:
Die Bibliothek libheif kann Bilder nicht nur in das .heic Format sondern auch in das neuere und bessere .avif Format konvertieren.
Interessant ist hier insbesondere das .avif Format (AV1 Image File Format).
Das neue lizenzfreie .avif Format wurde von der Alliance for Open Media hinter der zahlreiche führende Unternehmen wie Beispielsweise
Amazon, Apple, ARM, Cisco, Facebook, Google, IBM, Intel, Microsoft, Mozilla, Netflix, Nvidia, Samsung, Tencent stehen entwickelt.
Eine finale Spezifikation der Version 1.0.0 des AVIF-Formates wurde erst 2019 festgelegt, sodass die tatsächliche Nutzung praktisch erst aktuell beginnt.
Bilder im .avif Format haben durch verbesserte/neuere Kompressionsalgorithmen im Vergleich mit .jpeg oder .webp Bildern oft eine deutlich geringere Dateigröße bei praktisch gleicher Bildqualität.
Aufgrund dieser zahlreichen Vorteile wird sich .avif wahrscheinlich eher durchsetzen als alle bisherigen Versuche anderer neuer Bildformate.
Insbesondere im Web-/Internetbereichen wird man hier vermehrt einen Aufschwung erleben, da sich dadurch Ladezeiten von Webseiten signifikant verkürzen lassen.
Hier in diesem Punkt soll es aber nur darum gehen Bilder (Fotos) in guter Qualität ins .avif (bevorzugt) bzw. .heic Format zu konvertieren,
bzw. um diese neuen modernen Formate in in ein älteres Format wie z. B. .png/.jpg zurück zu konvertieren.
Achtung wichtiger Hinweis:
Die folgenden Skripte sind nur zur Konvertierung von Bildern vorgesehen.
Beachtet hier also, dass ihr keine Animationen z. B. aus webp, gif usw. verwendet,
denn die darin enthaltenen Animationen würden sonst verloren gehen.
Den Konverter installieren (ab Ubuntu 18.04/Debian 10):
apt install libheif-examples
libheif (heif-convert ...) unter Ubuntu/Debian kompilieren:
Das .heic/.avif-Format wird derzeit noch häufig verbessert, wer eine aktuelle Version verwenden will sollte daher wie folgt den Quellcode selbst übersetzen:
Notwendige Compilertools (g++) und Bibliotheken für: x265, .jpeg, .png, H.265-Videocodecs, AOmedia, AOMedia Video 1 (AV1) decoder ... installieren:
apt install build-essential make automake libtool pkg-config libx265-dev x265 libpng-dev libjpeg-dev libde265-dev libgdk-pixbuf2.0-dev libaom-dev libdav1d-dev
Hinweise:
Der Bibliotheksname libgdk-pixbuf2.0-dev lautet ab Ubuntu 21.04 libgdk-pixbuf-2.0-dev (neuere Version).
Die Bibliothek libdav1d-dev ist erst ab Ubuntu 21.04 verfügbar (in älteren Versionen einfach weglassen).
Die Bibliothek
librav1e-dev (rust AV1 video encoder) ist aktuell unter Ubuntu noch nicht verfügbar.
Konvertierungen von Bildern ins AVIF-Format (.avif) sind aber möglich.
Das Paket x265 ist wahrscheinlich nicht zwingend notwendig, es wird auf der libheif Webseite aber als Voraussetzung genannt.
Die aktuelle Version herunterladen/den source-code lokal spiegeln:
git clone https://github.com/
strukturag/libheif
Ins Quellverzeichnis wechseln:
cd libheif
Und das Programm kompilieren:
./autogen.sh
./configure
make # Erzeugt die Programme:
heif-convert, heif-enc, heif-info, heif-test, heif-thumbnailer und weitere.
Die fertig ausführbaren Programme liegen nun im
example Verzeichnis:
libheif/examples/heif-convert # Global zum packen.
libheif/examples/heif-enc # Der eigentliche Konverter mit zahlreichen Parametern und Möglichkeiten (ein Direktaufruf wird empfohlen).
libheif/examples/heif-info # Kann Datei-Infos zu .heic/.avif Dateien anzeigen.
Um die Ausführung der Programme zu vereinfachen sollte man am besten einen
Alias anlegen.
Öffnet dazu die 'Autostart-Datei' mit einem Editor:
nano ~/.bash_profile
Und fügt hier folgendes ein:
alias heif-convert=~/libheif/examples/heif-convert
alias heif-enc=~/libheif/examples/heif-enc
alias heif-info=~/libheif/examples/heif-info # ... für die weiteren Programme je nach Bedarf entsprechend wiederholen.
source ~/.bash_profile = Aliase sofort aktivieren (ohne Neustart).
Oder nach einem Neustart ist der Konverter dann über den Befehle [
heif-convert] bzw. [
heif-enc] ansprechbar.
Ergänzende Tipps: gccgo-go, golang-go = Sind notwendige Pakete zum kompilieren der auf der Programmiersprache Go basierenden Versionen.
Version: 2021-09-23
HEIC Bilder in png/jpg konvertieren:
heif-convert IMG_xxxx.HEIC IMG_xxxx.png = Verlustfreie Konvertierung (empfohlen). Benötigt man hochwertige .jpg Bilder, dann konvertiert man diese .png Bilder im Nachgang mit guetzli.
heif-convert IMG_xxxx.HEIC IMG_xxxx.jpg = Verlustbehaftete Konvertierung mit dem Standard-Qualitätswert 90.
heif-convert -q84 IMG_xxxx.HEIC IMG_xxxx.jpg = (quality) Werte von 1-100 sind möglich. Standard ist 90, 84 wird empfohlen.
Der Parameter -q wirkt nur bei verlustbehafteter Konvertierung/Komprimierung (jpg).
Mehrere .HEIC Dateien in .jpg Dateien umwandeln:
#!/bin/bash
find /Pfad -type f -name "*.HEIC" | while read img; do heif-convert -q84 "${img}" "${img%.HEIC}.jpg"; done # Die Anführungszeichen so mit übernehmen.
Bei dieser einfachen Variante werden nur Dateien mit kleingeschriebener Dateiendung konvertiert.
Bereits bestehende .jpg Dateien werden ohne Rückfrage überschrieben.
Das Script ist auch zur Umwandlung in .png Dateien geeignet. Hier einfach .jpg durch .png ersetzen.
Image Informationen anzeigen (auch für andere Datei/Bildformate wie .heic, ...):
heif-info Datei.avif = Zeigt Datei-Infos wie, Auflösung, Image-Anzahl usw. an.
x265 HEVC encoder:
png/jpg Bilder in HEIC konvertieren:
heif-enc -P = Listet alle wichtigen Parameter für den x265 HEVC encoder auf.
heif-enc Bild.png = konvertiert die Datei 'Bild.png' verlustbehaftet in die Datei 'Bild.heic'.
heif-enc Bild.jpg -o IMG_Name.heic = (output) konvertiert die Datei 'Bild.jpg' verlustbehaftet in die Datei 'IMG_Name.heic' (anderer Zieldateiname).
heif-enc Bild.png -L -p chroma=444 --matrix_coefficients=0 Bild.heic = (lossless) konvertiert mit verlustfreier Komprimierung.
Der Parameter -q (sofern angegeben) wird ignoriert (empfohlen für Logos).
heif-enc Bild.jpg -q84 Bild.heic = (quality) bestimmt den Qualitätswert 0-100 ist möglich, 84 empfohlen, Standard ist 50 (ohne -q).
heif-enc Bild.png -vq84 -o IMG_Name.heic = (verbose, quality und output) ausführliche Anzeige beim Konvertieren. Die Ausgabe erfolgt verlustbehaftet mit dem Qualitätswert 84 in den angegebenen Dateinamen (empfohlen für Fotos).
AOMedia Project AV1 Encoder:
png/jpg Bilder in .avif konvertieren:
heif-enc -A -P = Listet alle wichtigen Parameter für den AOMedia Project AV1 Encoder auf.
heif-enc -A Bild.png = konvertiert die Datei 'Bild.png' verlustbehaftet in die Datei 'Bild.avif'.
heif-enc -A Bild.jpg -o IMG_Name.avif = (output) konvertiert die Datei 'Bild.jpg' verlustbehaftet in die Datei 'IMG_Name.avif' (anderer Zieldateiname).
heif-enc -A Bild.png -L -p chroma=444 --matrix_coefficients=0 Bild_lossless.avif = (lossless) konvertiert mit verlustfreier Komprimierung.
Der Parameter -q (sofern angegeben) wird ignoriert (empfohlen für Logos).
heif-enc -A Bild.jpg -q70 Bild.avif = (quality) bestimmt den Qualitätswert 0-100 ist möglich, ~ 70 empfohlen, Standard ist 50 (ohne -q).
heif-enc -A Bild.png -vq70 -o IMG_Name.avif = (verbose, quality und output) ausführliche Anzeige beim Konvertieren. Die Ausgabe erfolgt verlustbehaftet mit dem Qualitätswert 70 in den angegebenen Dateinamen (~ empfohlen für Fotos).
Das nachfolgende Script konvertiert auch Dateien mit groß geschriebener Dateiendung .png, .PNG, .Jpg, usw. in .avif Dateien.
Vorhandene Dateien werden übersprungen (kann man deaktivieren) und ggf. vorhandene webp-Dateien werden berücksichtigt, sodass nur sehr kleine Dateien entstehen. Die folgende Variante wird daher bevorzugt empfohlen.
zum Umwandeln der Dateien ein neues Script anlegen:
nano _avif_convert_png_jpg_to_avif.sh
hier dann folgendes einfügen (Pfad anpassen nicht vergessen):
#!/bin/bash
# Script-Beschreibung: Konvertiert jpg, jpeg & png in avif, optimierte Qualität & Größe, ideal für Internet-Webserver, Apps u. ä.
# 1. image_convert = ist eine selbstdefinierte Funktion für die Konvertierung. Die Funktion muss am Anfang im Script stehen.
image_convert() {
# Bilder bzw. Fotos können aber sehr verschieden sein.
# Ein flächiges Logo mit wenig Farben bwz. einfarbigen Flächen lässt sich meist verlustfrei/lossless besser packen,
# als Beispielsweise ein Foto von ein einer bunten Wiese. Letzteres lässt sich verlustbehaftet/lossy besser packen.
# Aus diesem Grund erzeugt das folgende Script immer zuerst beide Varianten (lossless und lossy) und vergleicht diese im Anschluss.
# So wird immer die optimalste/kleinstmögliche Variante behalten.
echo -e "Konvertiere lossless Variante (png/Logos):";
~/libheif/examples/heif-enc -AL "$1" -o "$2.lossless"; # Dies ist die eigentliche Konvertierung mittels heif-enc (verlustfrei für Logos u. ä.).
echo -e "Konvertiere lossy Variante (jpg/Fotos):"; # Hier ggf. bei Bedarf die Qualität anpassen.
~/libheif/examples/heif-enc -A -q70 "$1" -o "$2.lossy"; # Dies ist die eigentliche Konvertierung mittels heif-enc (verlustbehaftet für Fotos).
# $1 = ist der zuerst übergebene Parameter (der Pfad und der Name zur Originaldatei).
# $2 = ist der zweite übergebene Parameter (der Pfad und der Name zur Zieldatei).
# $3 = ist der dritte übergebene Parameter (der Pfad und der Name zur webp-Datei sofern vorhanden).
# -A = legt die Konvertierung ins avif Format Fest.
# -L = legt die verlustfreie (lossless) Komprimierung fest.
# -q 70 = bestimmt die Qualität bei verlustbehafteter/lossy Komprimierung (0 - 100), der Wert 70 ist meine Empfehlung (Standard 50).
# Die Qualität kann man bei Bedarf entsprechend anpassen (Parameter).
# Welche Datei ist kleiner, lossless oder lossy?
if [ $(stat -c%s "$2.lossless") -le $(stat -c%s "$2.lossy") ]; then # Wenn $2.lossless kleiner oder gleich (less or equal) als $2.lossy ist dann,
echo -e "Die lossless (\033[32mverlustfreie\033[0m) Datei ist kleiner, lösche die nicht benötigte lossy (verlustbehaftete) Datei.";
rm -fv "$2.lossy"; mv -v "$2.lossless" "$2"; # die größere $2.lossy Datei löschen & die $2.lossless Datei als neue Zieldatei $2 benennen.
else # Wenn nicht dann,
echo -e "Die lossy (\033[33mverlustbehaftete\033[0m) Datei ist kleiner, lösche die nicht benötigte lossless (verlustfreie) Datei.";
rm -fv "$2.lossless"; mv -v "$2.lossy" "$2"; # die größere $2.lossless Datei löschen & die $2.lossy Datei als neue Zieldatei $2 benennen.
fi;
# Es bleibt also nur eine Datei (die kleinere von beiden) übrig, entweder verlustfrei/lossles oder verlustbehaftet/lossy.
# Prüfen ob die Zieldatei korrekt erzeugt wurde.
if [ -f "$2" ] # Wichtig: Immer alle Leerzeichen bei den if Anweisungen mit übernehmen.
then # Wenn die neue Datei existiert, dann ...
echo -e "OK: Die neue konvertierte Datei wurde erzeugt.";
# Dateigrößen für die original Datei und die konvertierte Datei und die webp Datei ermitteln:
size1=$(stat -c%s "$1");
size2=$(stat -c%s "$2");
size3=$(stat -c%s "$3");
# Prüfen ob die neue Datei kleiner oder gleich groß ist (im Vergleich zur Originaldatei).
if [ "${size1}" -le "${size2}" ]; then # Wenn die Originaldatei $1 kleiner oder leich (less or equal) groß ist wie die neue Datei $2, dann folgende Meldung ausgeben.
echo -e "\n\033[41mGrößer.....:\033[0m" "${2}" "\nDie konvertierte Datei ist \033[31mgrößer oder gleich groß\033[0m. Nur die \033[31mOriginaldatei\033[0m und ggf. eine WebP-Datei bleibt bestehen.\n";
rm -fv "$2"; # Die konvertierte (größere/gleich große Datei) wird automatisch gelöscht, denn es sollen ja möglichst nur kleine Dateien im Web sein.
return 0; # Wichtig: Die Funktion vorab zu beenden ist wichtig, damit die Originaldatei bestehen bleibt.
fi;
# Prüfen ob die neue Datei kleiner oder gleich groß ist (im Vergleich zur webp-Datei).
# Der Hintergrund ist praktisch alle Webbrowser unterstützen .webp.
# Wenn die .webp-Datei bereits kleiner ist als die .avif-Datei, dann wird die .avif-Datei nicht benötigt.
# Die .avif-Datei wird hier in dem Skript also nur beibehalten wenn die .avif-Datei sowohl kleiner als das original und kleiner als ein eventuell vorhandene .webp-Datei ist.
# Meist trifft dies nur auf größere Bilder mit mehr Farben zu.
# Sehr kleine Logos und Bilder mit wenigen Farben lassen sich im .webp-Format meist besser komprimieren.
# Daher wird hier gegengeprüft und ggf. zu große Bilder gelöscht.
if [ "${size3}" -le "${size2}" ]; then # Wenn die webp-Datei $1 kleiner oder gleich (less or equal) groß ist wie die neue Datei $2, dann folgende Meldung ausgeben.
echo -e "\n\033[41mGrößer.....:\033[0m" "${2}" "\nDie konvertierte Datei ist \033[31mgrößer oder gleich groß\033[0m als die vorhandene \033[31mwebp-Datei\033[0m. Nur die Originaldatei & WebP-Datei bleiben.\n";
rm -fv "$2"; # Die konvertierte (größere/gleich große Datei) wird automatisch gelöscht, denn es sollen ja möglichst nur kleine Dateien im Web sein.
return 0; # Wichtig: Die Funktion vorab zu beenden ist wichtig, damit die Originaldatei bestehen bleibt.
fi;
# rm -fv "$1"; # Die Originaldatei wird nur gelöscht, wenn man hier die führende Raute '#' entfernt.
else # Fehlerausgabe, nur falls das konvertieren fehlgeschlagen ist (Berechtigungsprobleme/keine Schreibrechte u. ä.).
echo -e "\n\033[41mFehler.....:\033[0m" "${img}" "\nDie Datei wurde nicht konvertiert, die Originaldatei bleibt bestehen.\n";
fi; # Ende der if Schleife.
} # Ende der Funktion.
# 3. Alle 'png/jpg/jpeg' Dateien suchen. Die Groß- und Kleinschreibung wird dabei nicht beachtet.
find /Pfad -type f -iname "*.png" -o -iregex ".*\.jpe?g" | # Den Pfad und die Dateitypen entsprechend anpassen.
# Regex Erklärungen:
# '.' = der Punkt entspricht einem beliebigen Zeichen. '.*' bedeutet eine beliebige Zeichenfolge.
# '\' = hebt die Bedeutung des danach folgenden Zeichens auf. '\.' bedeutet also nur der '.' Punkt.
# Der Punkt wird also durch den Backslash maskiert, damit er nicht als beliebiges Zeichen erkannt wird.
# '?' = das Fragezeichen bedeutet, dass das davor stehende Zeichen ggf. vorkommen kann.
while read img; # while, do, done Schleife - durchlauf über alle Gefundenen Dateien.
do
# $img = enthält den Pfad und den kompletten original Dateinamen (beliebige Groß- und Kleinschreibung).
echo -e "__ __ __ __ __ __ __ __ __ __ __ __ __ __ __"; # Optische Trennung der einzelnen Konvertierungen.
# Variablen definieren für die Dateinamen - hier sollte man nichts ändern.
# $ext_org = enthält die original Dateiendung.
ext_org="${img##*.}"; # Enthält z. B. 'PNG', 'Jpg', 'jpeg' (in beliebiger Schreibweise).
# $smal_ext = enthält die original Dateiendung im kleingeschriebenen Format.
smal_ext="${ext_org,,}"; # enthält also entweder 'png', 'jpg' oder 'jpeg'.
# $file_path = enthält den Pfad zur aktuellen Datei.
file_path=$(dirname "${img}");
# $file_name = enthält den Dateinamen ohne Pfad & ohne Dateiendung. Also z. B. 'IMG_190131_164530'.
file_name=$(basename "$img" .${ext_org}); # Der Punkt '.' und die original Dateiendung wird entfernt.
# $new_name = enthält den Pfad und den Dateinamen mit der neuen Dateiendung.
# Achtung: Hier nur eine Variante entsprechend auskommentieren (aktivieren).
# new_name=${file_path}/${file_name}.avif; # = Pfad, Dateiname und nur die Endung .avif.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.avif' - ohne original Dateiendung, stattdessen mit .avif.
# new_name=${file_path}/${file_name}.${ext_org}.avif; # = Pfad, Dateiname, original Dateierweiterung und .avif.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.JPG.avif' - mit unveränderter original Dateiendung und .avif.
new_name=${file_path}/${file_name}.${smal_ext}.avif; # = Pfad, Dateiname, kleingeschriebene original Dateierweiterung und .avif.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.jpg.avif'. - immer mit kleiner Dateiendung/einheitliche Dateinamen (empfohlen).
# Pfad zur .webp-Datei ermitteln sofern vorhanden (optional/Empfohlen).
webp_name=${file_path}/${file_name}.${smal_ext}.webp; # = Pfad, Dateiname, kleingeschriebene original Dateierweiterung und .webp.
# Dateinamen Beispiel: '/home/Benutzer/IMG_190131_164530.jpg.webp'. - immer mit kleiner Dateiendung/einheitliche Dateinamen (empfohlen).
# Optionale Ausgaben zur Kontrolle.
# Den Pfad und den originalen Dateinamen mit einer Leerzeile zur Trennung ausgeben.
echo -e "\nimg........:" "${img}";
# Den Pfad und den Dateinamen mit der neuen Dateiendung ausgeben.
echo -e "new_name...:" "${new_name}";
# 4. Prüfen ob schon eine konvertierte Datei vorhanden ist. Diese Prüfung kann man ggf. weglassen.
# Wichtig: Die Leerzeichen so mit übernehmen.
if [ -f "${new_name}" ];
then echo -e "Eine konvertierte Datei ist bereits vorhanden, die Datei wird daher übersprungen."
else echo -e "Starte Konvertierung:"
image_convert "${img}" "${new_name}" "${webp_name}"; # Aufruf der oben definierten Funktion (mit Parameterübergabe, Pfaden und Dateinamen).
# Prüft man die Existenz der Zieldatei nicht vorab, dann wird die bereits bestehende Datei ohne Rückfrage überschrieben.
fi; # Ende der if Schleife.
done; # Ende der while Schleife.
# Das Script wurde unter Ubuntu 22.04 entwickelt und getestet.
# Version: 2022-09-12 © ctaas.de
Das Script ausführbar machen:
chmod +x _avif_convert_png_jpg_to_avif.sh
Das Script kann man nun wie folgt starten:
./_avif_convert_png_jpg_to_avif.sh
Ergänzend: wichtige Programme die das neue .avif Format unterstützen (Liste ist nicht abschließend):
Google Chrome - ab Version 85 PC, ab Version 89 für Android
Mozilla Firefox - ab der Version 93, ab Version 86 experimentell nicht Standardmäßig aktiv
XnView
Gimp2
Paint.Net
Ergänzende Links:
Zum Konvertieren von Videos kann man z. B. SVT-AV1", libde265 verwenden.
Für Entwickler gibt es zahlreiche Bibliotheken die man in eigene Projekte einbinden kann z. B.: aomedia.googlesource.com/aom/
https://github.com/AOMediaCodec/libavif = Ist eine Bibliothek zum codieren und dekodieren von .avif-Dateien.
github.com/xiph/rav1e = rav1e ist ein freier AV1-Encoder. Der Name steht für Rust AV1-Encoder - die Software wird in Programmiersprache Rust programmiert.
github.com/videolan/dav1d = dav1d ist ein freier AV1-Decoder der die gesamte AV1-Spezifikation und Funktionen abdeckt.
41. guetzli: jpg Dateien in hoher Qualität erzeugen (für Webseiten):
guetzli (Keks) ist ein JPEG-Encoder der bei längerer Packdauer kleinere Dateien erzeugt.
Im Vergleich mit der oft verwendeten libjpeg-Bibliothek sind die mit guetzli erzeugten Bilder um ca. 35 Prozent kleiner.
Trotzdem weisen diese Bilder im Vergleich mit herkömmlichen Bildern oft weniger Artefakte (Bildfehler) auf.
Um die Fehler zu minimieren orientiert sich der Algorithmus unter anderem an der menschlichen Wahrnehmung.
Die Bildqualität bei gleicher Dateigröße steigt also (ideal für Webseitenbetreiber, APPs, Projekte).
Die Komprimierung ist wie bei jpg typisch verlustbehaftet.
Aus den Paketquellen installieren:
apt install guetzli
Alternativ die Installation der aktuellsten Version aus dem Quellcode (source-code):
Die selbst kompilierte Version packt ggf. etwas besser, wenn diese neuer ist (Versionsabhängig).
Beachtet dabei aber, die selbst kompilierte Version wird nicht mit den normalen Updates mit aktualisiert.
notwendige Compilertools installieren (g++):
apt-get install build-essential libpng-dev git pkg-config # Zusätzlich wird noch die PNG-Bibliothek installiert.
source-code lokal spiegeln:
git clone https://github.com/google/guetzli # Original Google Quellcode.
ins Quellverzeichnis wechseln:
cd guetzli
und das Programm kompilieren:
make
Hinweis: Den Punkt und Backslash './' vor dem 'guetzli' Befehl (den Pfad zum Programm) darf man nur bei der source-code Version mit angeben.
Hintergrund: Selbstkompilierte Programme werden nicht über den Pfad gefunden. Aus Sicherheitsgründen wird auch nicht im aktuellen Pfad gesucht.
Daher muss man vor selbstkompilierten Programmen immer den Pfad angeben, './' ist dabei der aktuelle Pfad.
Natürlich kann man auch den kompletten Pfad zum Programm angeben z. B. '/home/Benutzername/guetzli/bin/Release/guetzli'.
Datei packen:
cd bin/Release # Das Programm selbst liegt unter dem relativen Pfad '/guetzli/bin/Release' bei der selbstkompilierten Version.
./guetzli --verbose --nomemlimit --quality 95 input.png output.jpg # Eine einzelne Datei mit der Qualitätseinstellung 95 umwandeln.
Hinweise:
Als Quelldatei kann man auch jpg Dateien verwenden.
Besser sind jedoch nicht vorab komprimierte png Dateien.
bmp Dateien kann man nicht übergeben.
Die Qualität kann man nur von 84-100 eingestellen.
Mehrere .png Dateien in optimierte .jpg Dateien umwandeln (empfohlen für Webseiten):
#!/bin/bash
find /Pfad -type f -name "*.png" | while read img; do ./guetzli --verbose --quality 84 "${img}" "${img%.png}.jpg"; done # Die Anführungszeichen so mit übernehmen.
Bei dieser einfachen Variante werden nur Dateien mit kleingeschriebener Dateiendung konvertiert.
Bereits bestehende .jpg Dateien werden ohne Rückfrage überschrieben.
42. zopfli: png, htm, html, php, css, js, xml ... Dateien optimiert packen:
zopfli (Zopf/Hefezopf) ist ein Packer der Daten im Deflate-Format (gzip/zlib) sehr effizient verlustfrei packen kann.
Das packen dauert zwar länger, dafür erhält man aber deutlich kleinere Dateien.
zopfli kann beispielsweise png Dateien verlustfrei packen, so dass diese weniger Speicherplatz belegen.
Aus den Paketquellen installieren:
apt install zopfli
Alternativ die Installation der aktuellsten Version aus dem Quellcode (source-code):
Die selbst kompilierte Version packt ggf. etwas besser, wenn diese neuer ist (Versionsabhängig).
Beachtet dabei aber, die selbst kompilierte Version wird nicht mit den normalen Updates mit aktualisiert.
notwendige Compilertools installieren (g++):
apt-get install build-essential git
source-code lokal spiegeln:
git clone https://github.com/google/zopfli # Original Google Quellcode.
ins Quellverzeichnis wechseln:
cd zopfli
und die Programme übersetzen:
make zopflipng
make zopfli
Hinweis: Den Punkt und Backslash './' vor dem 'zopfli' bzw. 'zopflipng' Befehl (den Pfad zum Programm) darf man nur bei der source-code Version mit angeben.
Hintergrund: Selbstkompilierte Programme werden nicht über den Pfad gefunden. Aus Sicherheitsgründen wird auch nicht im aktuellen Pfad gesucht.
Daher muss man vor selbstkompilierten Programmen immer den Pfad angeben, './' ist dabei der aktuelle Pfad.
Natürlich kann man auch den kompletten Pfad zum Programm angeben z. B. '/home/Benutzername/zopfli/zopfli' bzw. '/home/Benutzername/zopfli/zopflipng'.
zopflipng Variante 1 - einzelne Dateien optimal packen:
time ./zopflipng --iterations=500 --filters=01234mepb --lossy_8bit --lossy_transparent -y input.png output.png # Nehmt zum Testen am besten erstmal eine kleine Datei.
Parameterbeschreibung:
[--iterations=15] = Parameter für zopflipng.
[--i15] = Parameter für zopfli.
Bestimmt die Anzahl der Durchläufe. Eine höhere Zahl von Durchläufen erhöht die Kompression, bei entsprechend längerer Laufzeit.
Standardwert ist '15', '5' wird für größere Dateien empfohlen.
Man kann auch noch viel höhere Werte angeben (beliebige Zahlen sind möglich z. B. 100, 2500, 32768, 1000000 ...). Höhere Werte sollte man jedoch nur bei kleineren Dateien verwenden, da sich die Packzeit deutlich erhöht - auch mehrere Stunden, Tage sind möglich. Den idealen Wert aus Kompression und Geschwindigkeit muss man daher je nach Datenbestand und Rechnerleistung individuell selbst ermitteln.
zopflipng Variante 2 - Mehrere png Dateien verkleinern/komprimieren (als Script bzw. manueller Aufruf):
#!/bin/bash
find . -type f -iname '*.png' -exec time ./zopflipng '{}' '{}' -y --iterations=4000 \;
Alle .png Dateien ab dem aktuellen Pfad '.' suchen (auch rekursiv) und ggf. verkleinern. time (optional) zeigt die Dauer pro Bild an.
Tipp:
Die Apostrophe (') sind bei Datei- oder Verzeichnisnamen mit Leerzeichen/Sonderzeichen zwingend notwendig (diese sollte man daher immer mit angeben).
for img in *.png; do time ./zopflipng '$img' '$img' -y --iterations=4000; done
Die Version mit der for/do/done Schleife durchsucht nur den aktuellen Ordner (nicht rekursiv). time (optional) zeigt die Dauer pro Bild an.
zopflipng Variante 3 (empfohlen) - Mehrere png Dateien gleichzeitig (parallel) und sortiert von 0-9/a-z/A-Z verkleinern/komprimieren (als Script bzw. manueller Aufruf):
#!/bin/bash
time find /pfad/ -type f -iname '*.png' -print0 | sort -nz | xargs -0rn1 --max-procs=8 -I{} \
time ./zopflipng '{}' '{}' -y --iterations=10000 &
Alle .png Dateien ab dem aktuellen Pfad '.' suchen (auch rekursiv) und ggf. verkleinern.
Da der zopflipng Prozess jeweils nur einen CPU-Kern (single-core) verwendet werden bei dieser Variante mehrere Instanzen parallel gestartet (multi-core = jeder CPU-Kern packt eine eigene Datei).
Parametererklärungen und Hinweise:
[time] = Ermittelt die Laufzeit. Die erste time Angabe misst die Gesamtlaufzeit (die Dauer zum packen aller Dateien). Die zweite time Angabe ermittelt die Dauer für einzelne Bilder/Dateien.
[-print0] = hängt am Ende des Dateinamens eine Nullbyte '0' an, um auch Dateinamen mit Leerzeichen/Sonderzeichen zu berücksichtigen.
[sort -nz] = Sortiert alle gefundenen Dateien (-n) Numerisch aufsteigend (also nach dem Alphabet). Am Ende wird wieder ein Nullbyte '0' (-z =zerro) angehängt.
[xargs -0rn1 --max-procs=8 -I{}] = trennt den Datenstrom von der Standardeingabe am Nullbyte '-0' und fügt einen Zeilenumbruch '-n1' ein.
Der nachfolgende Befehl wird nur dann ausgeführt, wenn Daten von der Standardeingabe kommen '-r = --no-run-on-empty'.
Der Parameter '--max-procs=X' legt dabei die Anzahl der maximal gleichzeitig laufenden Prozesse fest. Hier sollte man die Anzahl der vorhanden CPU Cores angeben.
Der Parameter '-I{}' legt fest wie der gefundene Dateiname (die Zeichenkette mit Pfad) übergeben wird. Standardmäßig wird der Name '{}' automatisch am Ende hinzugefügt (wenn man nichts anderes angibt).
Die Angabe ist hier notwendig, da der Dateiname im nachfolgenden Befehl mehrfach vorkommt und nicht am Ende steht.
[\] = Der Backslash am Ende der ersten Zeile kennzeichnet, das der Befehl auf der nächsten Zeile weitergeht.
[./zopflipng '{}' '{}' -y --iterations=10000] = Startet zopflipng mit einer Anzahl beliebigen Anzahl von Suchdurchläufen (--iterations=X).
Zahlen von 0 ... unendlich sind hier möglich. Für den Start sollte man mit 15 arbeiten. Bei wirklich kleinen Logos, verwende ich durchaus auch Werte bis 1000000 (1 Million) und mehr.
Beachtet dabei aber, die Packdauer kann insbesondere bei höheren Werten durchaus mehrere Tage pro Bild dauern.
Fangt daher zuerst mit kleinen Werten 5, 15, 30 .... 100 oder so an.
[&] = Der Prozess wird im Hintergrund ausgeführt, sodass sofort ein weiterer gestartet werden kann.
Hinweise:
Beachtet dass hier im Script (Version 3 & 4) die einzelnen Prozesse mittels '&' in den Hintergrund geschickt werden. Es laufen daher mehrere zopflipng Prozesse parallel.
Bei Problemen (z. B. bei zu hoher Systemlast) kann man alle laufenden Prozesse mittels [killall -g zopflipng] beenden (führt diesen Befehl ggf. in einem weiteren Terminal aus).
Beachtet auch, durch die parallele/gleichzeitige Abarbeitung kann es weiterhin zu Verschiebungen bei der Ausgabe der Packergebnisse kommen.
Denn wenn die Daten waren einfacher zu packen, dann kann ein später gestarteter Prozess tatsächlich vor einem zuvor gestarteten Prozess fertig sein (die Verschiebung beträgt dabei maximal die Anzahl der eingesteuerten Prozesse).
Abgearbeitet (eingesteuert) werden die Dateien natürlich exakt in der Reihenfolge wie sie gefunden/sortiert wurden. Es werden natürlich auch immer alle Dateien behandelt.
zopflipng Variante 4 - Alternativ zur Version 3: Dateien nach Dateigröße sortiert behandeln (kleinste Dateien zuerst).
#!/bin/bash
time find /pfad/ -type f -iname '*.png' -print0 | xargs -0 du -b0 | sort -nz | cut -f2 -z | xargs -0rn1 --max-procs=8 -I{} \
time ./zopflipng '{}' '{}' -y --iterations=100 &
Mit dieser Variante kann man ggf. leichter die Gesamtdauer abschätzen. Beachtet, wenn kleine Dateien schon lange dauern, dann benötigen größere Dateien noch ein Vielfaches länger.
Parametererklärungen:
[xargs -0 du -b0] = Trennt am Nullbyte und gibt die Disk-Nutzung (du) in Bytes aus und hängt wieder ein Nullybte an. Nach der Dateigröße den Bytes wird dann aufsteigend sortiert.
[cut -f2 -z] = Gibt nur die 2. Spalte aus (die Dateigröße wird abgeschnitten). Der Parameter '-z' (zero) hängt hier ebenso ein Nullbyte an.
zopfli gzip Variante A - alle anderen Dateien packen (.htm, .html, .php, .css, .js, .xml usw.):
time ./zopfli --gzip --i1000000 -v datei.htm # Eine einzelne Datei packen.
zopfli gzip Variante B - Mehrere Dateien mit zopfli optimal packen (als Script bzw. manueller Aufruf):
#!/bin/bash
time find . -type f \( -iname '*.htm' -o -iname '*.php' \) -exec time ./zopfli '{}' -v -y --i100000 \; # Die Leerzeichen um die Klammern entsprechend mit übernehmen.
Alle HTML- und PHP-Dateien im aktuellen Verzeichnis, auch rekursiv packen. time (optional) misst die Packzeit. Die Dateitypen entsprechend anpassen/ergänzen.
zopfli gzip Variante C (empfohlen) - Mehrere png Dateien gleichzeitig (parallel) und sortiert von 0-9/a-z/A-Z mit zopfli verkleinern/komprimieren (als Script bzw. manueller Aufruf):
#!/bin/bash
time find . -type f \( -iname '*.htm' -o -iname '*.php' -o -iname '*.css' \) -print0 | \
sort -nz | xargs -0rn1 --max-procs=8 -i{} \
time ./zopfli '{}' -v -y --i100000 \;
Der Parameter '--max-procs=X' legt dabei die Anzahl der maximal gleichzeitig laufenden Prozesse fest. Hier sollte man die Anzahl der vorhanden CPU Cores angeben.
Die so erzeugten .gz Dateien kann man dann Beispielsweise auf einem Webserver bereitstellen (kürzere Ladezeiten, schnellere Webseite).
Damit der Server die Daten ausliefert muss man in der Regel noch einige Anpassungen, meist an der .htaccess-Datei, auf dem Webserver vornehmen.
Alternativen:
Quelldateien: https://github.com/search?q=zopfli
langsame Javascript Version: http://imaya.github.io/zopfli.js/
43. advpng: png ... Dateien optimiert packen:
Wer png Bilder optimal packen will sollte auch advpng vom advancemame Project (AdvanceCOMP) Beachtung schenken.
Denn der von Google bereitgestellte zopfli Algorithmus packt trotz hoher Packstufe nicht immer am besten.
Insbesondere png Dateien mit wenigen Farben (unter 256) also Logos werden nicht immer optimal gepackt.
advpng verwendet zwar auch den zopfli Algorithmus aber möglicherweise wurde dieser hier anders optimierter implementiert.
Wer also das letzte Quäntchen herausholen will der sollte in einem zweiten Lauf advpng verwenden.
Aus den Paketquellen installieren:
apt-get install advancecomp
Alle im angegebenen Pfad gefundenen png Dateien optimiert packen (lossless/verlustfrei):
find /Pfad -type f -iname "*.png" -exec advpng -4 -z -i 100 "{}" \;
Es werden nur kleinere Dateien geschrieben.
Parameterbeschreibung:
[-4] = den zopfli Algorithmus verwenden.
[-z] = die Datei neu komprimieren. Standardmäßig wird die Datei nur überschrieben wenn die komprimierte Datei kleiner war.
[-i 100] = bestimmt die Anzahl der Iterationen (Durchläufe). Von 0 - 1.000.0000 (und mehr) ist hier jeder Wert möglich. Empfehlenswert sind Werte zwischen 100 und 10000 (je nach Dateigröße).
empfohlen: Mehrere png Dateien gleichzeitig (parallel) und sortiert von 0-9/a-z/A-Z verkleinern/komprimieren (als Script bzw. manueller Aufruf):
#!/bin/bash
time find . -type f -iname "*.png" -print0 | sort -nz | xargs -0rn1 --max-procs=8 -I{} \
time ~/advancecomp/advpng -4 -z -i 100 '{}' \;
Eine ausführliche Parameterberschreibung finden Sie hier.
Hinweise:
Beachtet dass die einzelnen Prozesse mittels '&' in den Hintergrund geschickt werden. Es laufen daher mehrere advpng Prozesse parallel.
Bei Problemen (z. B. bei zu hoher Systemlast) kann man alle laufenden Prozesse mittels [killall -g advpng] beenden (führt diesen Befehl ggf. in einem weiteren Terminal aus).
Alternativ die Installation der aktuellsten Version aus dem Quellcode (source-code):
Die selbst kompilierte Version packt ggf. etwas besser, wenn diese neuer ist (Versionsabhängig).
Beachtet dabei aber, die selbst kompilierte Version wird nicht mit den normalen Updates mit aktualisiert.
notwendige Compilertools installieren (g++):
sudo apt-get install automake autoconf git g++ valgrind
git clone https://github.com/amadvance/advancecomp
cd advancecomp
autoupdate -v # Konvertiert die Makronamen in der Datei configure.ac in das neue Format.
./autogen.sh
./autogen.sh # Hinweis: Dieser Befehl muss zweimal hinter einander ausgeführt werden.
./configure
make # Hinweis: Dieser Schritt dauert etwas länger (erzeugt das startbare Programm).
make check # Im Anschluss kann man noch eine Prüfung durchführen, ob alles korrekt kompiliert wurde (optional).
Die kompilierten Programme:
advdef, advmnp, advpng und advzip liegen direkt im advancecomp Verzeichnis.
Um die Ausführung der Programme zu vereinfachen sollte man am besten einen
Alias anlegen.
Öffnet dazu die 'Autostart-Datei' mit einem Editor:
nano ~/.bash_profile
Und fügt hier folgendes ein:
alias advpng=~/advancecomp/advpng
source ~/.bash_profile = Aliase sofort aktivieren (ohne Neustart).
Oder nach einem Neustart ist das Programm dann über den Befehl [
advpng] ansprechbar.
Ergänzt die weiteren Programme je nach Bedarf entspechend genau so.
Hinweis: Version angepasst für die neue Version 2.5 vom 22.01.2023.
44. brotli: htm, html, php, css, js, xml Dateien ... optimiert packen:
brotli (Brötli/Brot) ist ein Packer der Daten im LZ77 bzw. Huffmann-Kodierung sehr effizient verlustfrei packen kann.
brotli verwendet zusätzlich zum Packen ein vordefiniertes Wörterbuch, das insbesondere auf Text- und HTML-Dateien optimiert wurde.
Das Packen der Daten geht sehr schnell.
Webbasierte Dateien werden in der Regel immer kleiner als mit anderen vergleichbaren Packern.
Ideal also zur Bereitstellung von Webinhalten (wir setzen das auch weitestgehend ein).
Aus den Paketquellen installieren:
apt install brotli
Alternativ die Installation der aktuellsten Version aus dem Quellcode (source-code):
Die selbst kompilierte Version packt ggf. etwas besser, wenn diese neuer ist (Versionsabhängig).
Beachtet dabei aber, die selbst kompilierte Version wird nicht mit den normalen Updates mit aktualisiert.
notwendige Compilertools installieren (g++):
apt-get install build-essential git
source-code lokal spiegeln:
git clone https://github.com/google/brotli # Original Google Quellcode.
ins Quellverzeichnis wechseln:
cd brotli
und das Programm kompilieren:
./configure && make
cd bin # Das Programm selbst liegt unter dem relativen Pfad '/brotli/bin' bei der selbstkompilierten Version.
Hinweis: Den Punkt und Backslash './' vor dem 'brotli' Befehl (den Pfad zum Programm) darf man nur bei der source-code Version mit angeben.
Hintergrund: Selbstkompilierte Programme werden nicht über den Pfad gefunden. Aus Sicherheitsgründen wird auch nicht im aktuellen Pfad gesucht.
Daher muss man vor selbstkompilierten Programmen immer den Pfad angeben, './' ist dabei der aktuelle Pfad.
Natürlich kann man auch den kompletten Pfad zum Programm angeben z. B. '/home/Benutzername/brotli/bin/brotli'.
Dateien packen:
./brotli -f datei.htm # einzelne Datei packen - neue Version.
#!/bin/bash
find /Pfad -type f \( -iname "*.htm" -o -iname "*.php" \) -exec ./brotli '{}' -f \; # mehrere Dateien packen - neue Version - auch rekursiv.
Alle HTML- und PHP-Dateien im aktuellen Verzeichnis, auch rekursiv packen. Die Dateitypen entsprechend anpassen/ergänzen.
./bro -q 11 -i datei.htm -o datei.htm.br -f # einzelne Datei packen - nur für die alte Version.
Dateien entpacken:
/.brotli -d datei.htm.br # einzelne Datei entpacken - neue Version.
#!/bin/bash
/.brotli -d *.br # mehrere Dateien entpacken - neue Version.
/.bro -d -i datei.htm.br -o datei.htm # einzelne Datei entpacken - nur für die alte Version.
Parametererklärungen:
[-d] = (decompress) eine gepackte Datei entpacken.
[-f] = (force) eine bereits bestehende Datei wird überschrieben.
[-q 11] = (quality) bestimmt das Kompressionslevel (0-11 ist möglich). Die beste Komprimierung (11) ist in den neueren Versionen bereits Standard (kann man daher weglassen).
[-i] = (input) bestimmt die Quelldatei. Den Parameter gibt es nur bei alten Versionen.
[-o] = (output) bestimmt die Zieldatei.
Die so erzeugten .br Dateien kann man dann Beispielsweise auf einem Webserver bereitstellen (kürzere Ladezeiten, schnellere Webseite).
Damit der Server die Daten ausliefert muss man in der Regel noch einige Anpassungen, meist an der .htaccess-Datei, auf dem Webserver vornehmen.
45. lepton: jpg/jpeg Bilder/Fotos verlustfrei im lep Format packen (ideal zum archivieren):
lepton kann jpg/jpeg Bilder verlustfrei (ohne jeglichen Qualitätsverlust, 1:1 Binär unverändert) packen.
Im Gegensatz zu anderen herkömmlichen Packern die meist kaum Platzersparnis bringen, werden mit lepon gepackte Bilder im Durchschnitt um ca. 22 % kleiner.
Bisher wird das .lep Format noch nicht von den gängigen Bildverarbeitungs- bzw. Bildbearbeitungsprogrammen besonders unterstützt.
Daher eignet sich das Format insbesondere zur Archivierung oder bei Übertragungen über langsame Leitungen wie Beispielsweise bei E-Mail usw.
Aus den Paketquellen installieren:
apt install lepton
Alternativ die Installation der aktuellsten Version aus dem Quellcode (source-code):
Die selbst kompilierte Version packt ggf. etwas besser, wenn diese neuer ist (Versionsabhängig).
Beachtet dabei aber, die selbst kompilierte Version wird nicht mit den normalen Updates mit aktualisiert.
notwendige Compilertools installieren (g++):
sudo apt-get install automake autoconf git g++
source-code lokal spiegeln:
git clone https://github.com/dropbox/lepton.git # Original
Dropbox Code.
ins Quellverzeichnis wechseln:
cd lepton
und das Programm kompilieren:
./autogen.sh
./configure
./configure CXXFLAGS=-mssse3 # Verhindert den Fehler: "target specific option mismatch" (bei neueren Ubuntu Versionen notwendig).
make liblocalzlib.a # Verhindert Linkfehler (bei neueren Ubuntu Versionen notwendig).
make # Hinweis: Dieser Schritt dauert etwas länger (erzeugt das startbare Programm).
make check # Im Anschluss kann man noch eine Prüfung durchführen, ob alles korrekt kompiliert wurde (optional).
Wenn alles geklappt hat, solltet ihr eine ähnliche Anzeige erhalten:
==================================
Testsuite summary for lepton 0.01
==================================
# TOTAL: 46
# PASS: 46
# SKIP: 0
# XFAIL: 0
# FAIL: 0
# XPASS: 0
# ERROR: 0
==================================
Das ausführbare Programm liegt nun direkt im Ordner 'lepton':
./lepton # Start des Programms direkt aus demselben Ordner.
/lepton/lepton # Start des Programms mit Pfadangabe.
Bilder/Fotos/Images packen:
./lepton -maxencodethreads=1 "IMG.jpg" # = packt die .jpg Bilddatei, der Dateiname der gepackten Datei lautet 'IMG.lep'.
./lepton -maxencodethreads=1 "IMG.jpg" "IMG.jpg.lep" # = packt die .jpg Bilddatei, die gepackte Datei wird im danach angegebenen Dateinamen gespeichert (in beliebiger Schreibweise).
Bilder/Fotos/Images entpacken:
./lepton "IMG.lep" # = entpackt die .lep Bilddatei, der Dateiname der entpackten Datei lautet 'IMG.jpg'.
./lepton "IMG.lep" "IMG.jpeg" # = die entpackte .lep Datei wird im danach angegebenen Dateinamen gespeichert (in beliebiger Schreibweise).
Parameterbeschreibung:
[-maxencodethreads=1] = bestimmt die Anzahl der zu verwendenden Threads. Eine größere Zahl beschleunigt das packen, allerdings wird die gepackte Datei größer.
Beachtet hier vor allem, ohne dem Parameter wird Standardmäßig mit mehreren Threads gepackt. Das bedeutet, ohne dem Parameter erhält man größere Dateien.
Daher sollte man den Parameter immer mit angeben und den Wert auf '1' setzen, wenn man möglichst kleine Archive haben möchte (empfohlen).
Befehlsübersicht/Parameter der Version v1.0-1.2.1-194-gf34c7f4:
lepton v1.0-1.2.1-194-gf34c7f4
Usage: lepton [switches] input_file [output_file]
[-version] File format version of lepton codec
[-revision] GIT Hash of lepton source that built this binary
[-zlib0] Instead of a jpg, return a zlib-compressed jpeg
[-startbyte=<n>] Encoded file will only contain data at and after <n>
[-trunc=<n>] Encoded file will be truncated at size <n> - startbyte
[-unjailed] Do not jail this process (use only with trusted data)
[-singlethread] Do not clone threads to operate on the input file
[-maxencodethreads=<n>] Can use <n> threads to decode: higher=bigger file
[-allowprogressive] Allow progressive jpegs through the compressor
[-rejectprogressive] Reject encoding of progressive jpegs
[-timebound=<>ms]For -socket, enforce a timeout since first byte received
[-lepcat] Concatenate lepton files together into a file that contains multiple substrings
[-memory=<>M] Upper bound on the amount of memory allocated by main
[-threadmemory=<>M] Bound on the amount of memory allocated by threads
[-recodememory=<>M] Check that a singlethreaded recode only uses <>M mem
[-hugepages] Allocate from the hugepages on the system
[-socket=<name>] Serve requests on a Unix Domain Socket at path <name>
[-listen=<port>] Serve requests on a TCP socket on <port> (default 2402)
[-listenbacklog=<n>] n clients queued for encoding if maxchildren reached
[-zliblisten=<port>] Serve requests on a TCP socket on <port> (def 2403)
[-maxchildren] Max codes to ever spawn at the same time in socket mode
[-benchmark] Run a benchmark on optional [<input_file>] (or included file)
[-verbose] Run the benchmark in verbose mode (more output to stderr)
[-benchreps=<n>] Number of trials to run the benchmark for each category
[-benchthreads=<n>] Max number of parallel codings to benchmark
[-validate] Round-trip this file when encoding [default:on]
[-skipvalidate] Avoid round-trip check when encoding (Warning: unsafe)
Hinweis: Mit der aktuellen Version (v1.0-1.2.1-172-g9c6182f) kann man nur Bilder bis etwa 20 MB Dateigröße komprimieren.
Ist die zu packende Datei zu groß, so erhält man den Fehler:
OOM
SHORT_READ
Update: Der Fehler wurde mit den neuen Versionen (aktuell z. B. v1.0-1.2.1-194-gf34c7f4) behoben. Man kann entspechend beliebig große Bilder komprimieren.
46. flif: png verlustfrei/verlustbehaftet im flif Format packen (fürs Web/APPs und zum archivieren):
FLIF (Free Lossless Image Format) ist ein neues modernes und freies (open-source) Bildformat/Animations-Format.
FLIF unterstützt lossless/verlustfreie und lossy/verlustbehaftete Kompression.
Ein direktes konvertieren von Animationen ist derzeit mit dem flif Programm noch nicht möglich.
Warum sollte man nun FLIF einsetzen?
Die mit FLIF lossless/verlustfrei komprimierten Bilder sind in der Regel immer kleiner als bei vergleichbaren Formaten. Im Durchschnitt 14 % kleiner als webp und 33-43 % kleiner als png.
FLIF sollte man daher bevorzugt im Web und in APPs verwenden.
Leider unterstützt derzeit keiner der größeren Webbrowser das '.flif' Format nativ. Daher muss man sich derzeit mit einem Javascript zum decodieren behelfen.
Auch bei einer Bildarchivierung kann flif natürlich sinnvoll sein (Platzersparnis).

Hier noch ein Größenvergleich für das hier gezeigte Beispielbild (180x180 Pixel):
| Bildformat | Dateigröße | Prozent | Bemerkungen |
| .heic | 4673 Bytes | 5563 % | heif-enc optimiert mit 'heic-enc -L', lossless |
| .jpg | 2647 Bytes | 3151 % | guetzli optimiert mit 'guetzli --quality 84', lossy |
| .heic | 2602 Bytes | 3098 % | heif-enc optimiert mit 'heic-enc -q84', lossy |
| .gif | 1333 Bytes | 1587 % | gifsicle optimiert mit 'gifsicle --optimize', lossless |
| .png | 262 Bytes | 312 % | zopfli optimiert mit 'zopflipng --iterations=100000', lossless |
| .webp | 114 Bytes | 136 % | webp optimiert mit 'cwebp -z 9', lossless |
| .flif | 84 Bytes | 100 % | flif optimiert mit dem brute-force Script, lossless |
Wie man sieht komprimiert FLIF (.flif) je nach Ausgangsbild deutlich besser als alle anderen bisherigen Formate.
Befehlsübersicht/Parameter der Version 0.4. (derzeit aktuelle stable Version von 2021):
FLIF (Free Lossless Image Format) 0.4 [21 Nov 2021]
ATTENTION: FLIF has been obsoleted by JPEG XL, see jpegxl.info for details.
Usage:
flif [-e] [encode options] <input image(s)> <output.flif>
flif [-d] [decode options] <input.flif> <output.pnm | output.pam | output.png>
flif [-t] [decode options] [encode options] <input.flif> <output.flif>
Supported input/output image formats: PNG, PNM (PPM,PGM,PBM), PAM
General Options:
-h, --help show help (use -hvv for advanced options)
-v, --verbose increase verbosity (multiple -v for more output)
-c, --no-crc don't verify the CRC (or don't add a CRC)
-m, --no-metadata strip Exif/XMP metadata (default is to keep it)
-p, --no-color-profile strip ICC color profile (default is to keep it)
-o, --overwrite overwrite existing files
-k, --keep-palette use input PNG palette / write palette PNG if possible
Encode options: (-e, --encode)
-E, --effort=N 0=fast/poor compression, 100=slowest/best? (default: -E60)
-I, --interlace interlacing (default, except for tiny images)
-N, --no-interlace force no interlacing
-Q, --lossy=N lossy compression; default: -Q100 (lossless)
-K, --keep-invisible-rgb store original RGB values behind A=0
-F, --frame-delay=N[,N,..] delay between animation frames in ms; default: -F100
Advanced encode options: (mostly useful for flifcrushing)
-P, --max-palette-size=N max size for Palette(_Alpha); default: -P512
-A, --force-color-buckets force Color_Buckets transform
-B, --no-color-buckets disable Color_Buckets transform
-C, --no-channel-compact disable Channel_Compact transform
-Y, --no-ycocg disable YCoCg transform; use G(R-G)(B-G)
-W, --no-subtract-green disable YCoCg and SubtractGreen transform; use GRB
-S, --no-frame-shape disable Frame_Shape transform
-L, --max-frame-lookback=N max nb of frames for Frame_Lookback; default: -L1
-R, --maniac-repeats=N MANIAC learning iterations; default: -R2
Decode options: (-d, --decode)
-i, --identify do not decode, just identify the input FLIF file
-q, --quality=N lossy decode quality percentage; default -q100
-s, --scale=N lossy downscaled image at scale 1:N (2,4,8,16,32); default -s1
-r, --resize=WxH lossy downscaled image to fit inside WxH (but typically smaller)
-f, --fit=WxH lossy downscaled image to exactly WxH
-b, --breakpoints report breakpoints (truncation offsets) for truncations at scales 1:8, 1:4, 1:2
wichtige Parameter:
[-V] = Versionsanzeige.
[-I] = (interlace) komprimiert das Bild progressiv, sodass auch schon ein Teildownload eine Vorschau ermöglicht. Standardmäßig immer ab Bildern über 10.000 Pixel (Länge x Breite).
[-N] = (no interlace) komprimiert das Bild scanline. Eine progressive Vorschau eines Teildownloads ist nicht möglich. Die Bilddatei wird dafür kleiner (empfohlen).
[-o] = (overwrite) eine bestehende Zieldatei überschreiben.
[-Q] = (quality) bestimmt die Qualität bei der verlustbehafteten/lossy (0-99) Komprimierung. Der Wert 100 (ist Standard) schaltet die verlustfreie/lossless Komprimierung ein.
[-E] = (effort/Anstrengung) bestimmt den Aufwand der für die Komprimierung aufgewendet wird (von 0-100).
Wichtig: Größere Werte erzeugen nicht zwingend eine kleinere Datei. Wer das Optimum herausholen will, muss ein brute-force/Durchlauf über alle Werte von 0-100 durchführen. Bisher bietet das flif Tool dazu keinen Parameter an.
Alle weiteren Parameter findet man in der manpage.
Aus den Paketquellen installieren:
apt install flif
Alternativ die Installation der aktuellsten Version aus dem Quellcode (source-code):
Die selbst kompilierte Version packt ggf. etwas besser, wenn diese neuer ist (Versionsabhängig).
Beachtet dabei aber, die selbst kompilierte Version wird nicht mit den normalen Updates mit aktualisiert.
notwendige Compilertools installieren (g++):
apt-get install build-essential libpng-dev make pkg-config libsdl2-dev git
source-code lokal spiegeln:
git clone https://github.com/FLIF-hub/FLIF
ins Quellverzeichnis wechseln:
cd FLIF/src
und das Programm kompilieren:
make
Das ausführbare Programm:
flif liegt nun direkt im Verzeichnis 'FLIF/src'.
Mehrere png Dateien verlustfrei/lossless in flif Dateien umwandeln:
find /Pfad -type f -iname "*.png" -exec ~/FLIF/src/flif -voN -E100 '{}' '{}'.flif \;
Die Parameter -v, -o, -N wurden hier zu -voN zusammengefasst, '~/FLIF/src/' ist der Pfad zum flif Programm.
Der Parameter -E ist optional bzw. bestimmt den Aufwandswert (0-100). Beachtet dabei 100 ist nicht immer der beste Wert.
Die kleinstmögliche verlustfreie/lossless FLIF Bilddatei ermitteln:
#!/bin/bash
# crush/optimize/brute-force flif-images:
# Ermittelt mittels brute-force (durch das Testen aller Möglichkeiten) die kleinstmögliche lossless .flif Datei.
# Das Script ist besonders für verlustfreie Komprimierung/flächige Logos geeignet.
# 1. image_convert = ist eine selbstdefinierte Funktion für die Konvertierung. Die Funktion muss am Anfang im Script stehen.
image_convert() {
img=$1; # $1 = ist der zuerst übergebene Parameter (enthält hier den Pfad und Dateiname der Originaldatei).
ext_org="${img##*.}"; # $ext_org = enthält die original Dateiendung. Enthält z. B. 'png', 'PNG', 'Png' (in beliebiger Schreibweise).
# Alle effort Versionen erzeugen und testen (0-100):
for i in {0..100}; do
echo -e "\n[-E\033[32m${i}\033[0m] ${img}"; # Die aktuelle effort Nummer (in grüner Farbe) und den aktuellen Dateinamen ausgeben (optional).
start=$(date +%s); # Startzeit der Konvertierung speichern (optional).
# Hier ggf. den Pfad zum flif Programm anpassen. Die neue Datei wird zuerst als *.tmp.flif erzeugt.
~/FLIF/src/flif -voN -Q100 -E${i} "${img}" "${img}.tmp.flif"; # v = verbose, o = overwrite, N = no-interlace
# Der Parameter -Q bestimmt die Qualität bei der verlustbehafteten/lossy (0-99) Komprimierung.
# Der Wert 100 (ist Standard) schaltet die verlustfreie/lossless Komprimierung ein.
echo "Dauer:" $(( $(date +%s) - ${start} )) "s"; # Ausführungszeit für das aktuelle Bild berechnen (optional).
echo "ca. Restzeit akt. Bild:" $(date -d@$(( $(( 100 - ${i} )) * $(( $(date +%s) - ${start} )) )) -u +%H:%M:%S);
# Circa Restlaufzeit für das aktuelle Bild berechnen (optional). Wichtig: Die Leerzeichen so mit übernehmen.
current_size=$(stat -c%s "${img}.tmp.flif"); # Die aktuelle Dateigröße ermitteln.
echo "optimierte Größe: ${current_size} Bytes"; # Die aktuelle Dateigröße ausgeben (optional)
array[i]=${current_size}; # und die aktuelle Dateigröße in einem array speichern (optional).
# Prüfen ob die neue Datei kleiner ist:
if [ ${i} = 0 ] || # Wenn es die erste erzeugte Datei ist (der Index hat den Startwert) oder '||',
[ ${current_size} -lt $small ]; # wenn die aktuell erzeugte Dateigröße kleiner ist (als der zuvor gespeicherte Wert),
then small=${current_size}; smallindex=$[i]; # dann die Dateigröße, den Index (optional) und
echo -en "\033[32m" # Die Textfarbe auf grün stellen.
mv -v "${img}.tmp.flif" "${img%${ext_org}}flif"; # die Datei sichern. Die original Dateiendung wird durch den Parameter '%' und die Variable '${ext_org}' entfernt.
# mv -v "${img}.tmp.flif" "${img}.flif"; # oder die Datei sichern. Die original Dateiendung bleibt erhalten. Der Dateiname wird um die Endung '.flif' ergänzt (alternativ).
tput sgr0 # Die Textfarbe wieder zurück stellen.
fi;
done; # Ende der for Schleife.
if [ -f "${img}.tmp.flif" ]; then rm -v "${img}.tmp.flif"; fi # Die *.tmp.flif Datei wird nur gelöscht wenn diese noch vorhanden ist.
# Wenn die letzte Datei die kleinste war wird keine Datei gelöscht, da die Datei dann zuvor schon verschoben wurde.
# optionale Ausgaben:
echo ${array[*]}; # Den Inhalt vom ganzen array Ausgeben.
echo "Die kleinste Zahl/Dateigröße innerhalb des array ist:" ${small};
echo "Die Index-Nummer der ersten kleinsten array Zahl ist:" ${smallindex};
} # Ende der Funktion.
# 2. Alle .png Dateien im Pfad suchen. Die Groß- und Kleinschreibung wird dabei nicht beachtet.
time find /Pfad -type f -iname "*.png" | # Den Pfad und ggf. den Dateityp entsprechend anpassen.
# Hinweis: Als Eingabeformat ist derzeit nur .png und die weniger gebräuchlichen PNM Formate .pbm (Portable Bitmap), .pgm (Portable Graymap) & .ppm (Portable Pixmap) möglich.
# Andere Formate wie z. B. .jpg, .gif, .bmp, .webp usw. sind derzeit nicht möglich. Andere Formate sollte man daher vorab bevorzugt in .png Dateien konvertieren.
while read img; do
# Prüfen ob schon eine konvertierte Datei vorhanden ist (mit oder ohne original Dateiendung). Diese Prüfung kann man ggf. weglassen.
if [ -f "${img}.flif" ] || [ -f "${img%${img##*.}}flif" ]; # Wichtig: Die Leerzeichen so mit übernehmen. '%${img##*.}' = entfernt die original Dateiendung.
then echo "Eine konvertierte Datei ist bereits vorhanden. Die Datei wird daher übersprungen.";
else echo "Starte Konvertierung:";
image_convert "${img}"; # Aufruf der oben definierten Funktion mit Parameterübergabe (Dateipfad und Dateiname).
# Hinweis: Prüft man die Existenz der Zieldatei nicht vorab, dann wird diese überschrieben.
fi; # Ende der if Schleife.
done
# Version: 2019-11-15 © ctaas.de
eine flif Animation aus einer Bilderfolge erzeugen:
flif -voN -F10000 -L10 Frame-*.png Animation.flif
Hinweis: Derzeigt gibt es leider wenig viewer die eine flif Animation wiedergeben können.
ergänzende Parameterbeschreibung:
[-F] = bestimmt die Pause in Millisekunden zwischen den einzelnen Frames.
[-L] = bestimmt die Länge wie weit bei der Komprimierung vorherige Frames berücksichtigt werden.
Sind die Unterschiede zwischen den vorherigen Frames immer gering, dann erhöht sich hier ggf. die Kompression.
Verwendet man den Wert -L0 dann werden vorherige Frames nicht berücksichtigt, die Dateigröße wird hier in der Regel ansteigen.
Welcher Wert hier der optimale ist kann man nicht pauschal festlegen. Für eine optimale Kompression hilft hier nur ein brute-force/Durchlauf über alle Werte von 0 bis zur maximalen Bildanzahl.
Der Höchstwert ist also immer die Anzahl aller einzelnen Bilder/aller einzelnen Frames der Animation. Ein noch größerer Wert macht also keinen Sinn.
flif Dateien im Internet/in Webseiten einbinden:
github.com/UprootLabs/poly-flif - Poly FLIF Projektseite.
uprootlabs.github.io/poly-flif/api.html - Beispiel zur Einbindung.
github.com/UprootLabs/poly-flif/releases, Version 0.8.2 - Download-Link für die notwendige java-script Datei.
Lief bei mir nicht im Internet Explorer. Animationen laufen derzeit (Version 0.8.2) noch zu schnell. Sonst ok.
Die Einbindung im Webcode/HTML-Quellcode erfolgt so:
<!-- im Header -->
<script src="flif.js"></script>
<!-- im HTML Code -->
<canvas data-polyflif-src="xyz.flif"></canvas>
47. Bildschirmauflösung einer Ubuntu/Debian Hyper-V VM ändern:
Eine Linux VM startet unter Hyper-V standardmäßig in der Auflösung 1152x864. Beachtet dabei, die Auflösung kann man über die grafischen Konfigurationstools nicht ändern.
Die Auflösung kann man derzeit nur durch das Hinzufügen von Boot-Parametern ändern. Man geht dabei wie folgt vor:
ggf. zuerst die Grafiktreiber für das X-Window-System, X.Org-Server/X11 für die VM installieren (nur notwendig wenn noch kein Grafischer Desktop möglich ist):
apt install xserver-xorg-video-fbdev = installiert nur den X.Org X Server Framebuffer-Anzeigetreiber (dieser reicht normalerweise).
apt install xserver-xorg-video-all = installiert alle gängigen Grafiktreiber. Ggf. auch notwendig bei Virtuellen Systemen z. B. unter Hyper-V, VMWare ... (empfohlen universell).
Man öffnet nun die grub Datei mit einem Text Editor:
nano /etc/default/grub
Hier fügt man folgenden Eintrag hinzu:
# If you change this file, run 'update-grub' afterwards to update
# /boot/grub/grub.cfg.
# For full documentation of the options in this file, see:
# info -f grub -n 'Simple configuration'
GRUB_DEFAULT=0
GRUB_TIMEOUT_STYLE=hidden
GRUB_TIMEOUT=0
GRUB_DISTRIBUTOR=`lsb_release -i -s 2> /dev/null || echo Debian`
GRUB_CMDLINE_LINUX_DEFAULT="debian-installer/language=de keyboard-configuration/layoutcode?=de video=hyperv_fb:1280x720"
GRUB_CMDLINE_LINUX=""
# Uncomment to enable BadRAM filtering, modify to suit your needs
# This works with Linux (no patch required) and with any kernel that obtains
# the memory map information from GRUB (GNU Mach, kernel of FreeBSD ...)
#GRUB_BADRAM="0x01234567,0xfefefefe,0x89abcdef,0xefefefef"
# Uncomment to disable graphical terminal (grub-pc only)
#GRUB_TERMINAL=console
# The resolution used on graphical terminal
# note that you can use only modes which your graphic card supports via VBE
# you can see them in real GRUB with the command `vbeinfo'
#GRUB_GFXMODE=640x480
# Uncomment if you don't want GRUB to pass "root=UUID=xxx" parameter to Linux
#GRUB_DISABLE_LINUX_UUID=true
# Uncomment to disable generation of recovery mode menu entries
#GRUB_DISABLE_RECOVERY="true"
# Uncomment to get a beep at grub start
#GRUB_INIT_TUNE="480 440 1"
ergänzende Hinweise:
Der Parameter 'video' legt fest welcher Grafiktreiber verwendet wird. 'hyperv_fb' steht dabei für den Framebuffer Video Treiber 'xserver-xorg-video-fbdev' (dieser muss also vorhanden sein).
Parameter die man hinter GRUB_CMDLINE_LINUX_DEFAULT="..." einfügt werden nur bei einem normalen Start an den Kernel übergeben bzw. berücksichtigt (empfohlen).
Parameter die man hinter GRUB_CMDLINE_LINUX="..." einfügt werden immer, also bei einem normalen Start und auch bei einem Wiederherstellungsmodus (recovery mode) an den Kernel übergeben bzw. berücksichtigt (man kann den Parameter auch hier angeben).
folgende Standard-Auflösungen sind möglich:
640x480 (kleinstmögliche Auflösung), 800x600, 1024x768, 1280x720, 1280x960, 1280x1024, 1440x900, 1600x900, 1600x1200, 1680x1050, 1920x1080 (größte Standardauflösung)
man kann auch beliebige krumme Auflösungen (vom Standard abweichende) verwenden, hier ein paar Beispiele:
920x920 = ideal um 2 VMs auf einem Full-HD Bildschirm nebeneinander anzuzeigen (empfohlen).
1920x1092 = eine größere maximal Auflösung (Full-HD ähnlich).
2300x910 = eine etwas breitere Variante (für WQHD, UHD 4K).
640x800 = beliebige gedrehte Auflösungen sind auch möglich (hochkantiges Format).
ergänzende Hintergrundinformationen:
Beachtet dabei, die Größe des Videospeichers vom Framebuffer Video Treiber (fbdev) ist derzeit auf nur 8 MB begrenzt. Daher wird derzeit als maximale Standard-Auflösung nur 1920x1080 Pixel unterstützt.
Grundlage ist dabei die folgende Berechnung:
1920 * 1080 * 4 (vier Byte bzw. 32 Bit pro Farbe) = 8.294.400 Bytes - somit knapp unter 8 MB.
Die maximale Auflösung muss also unter
8 MB also 8.388.606 Bytes (8 * 1024 * 1024) bleiben.
Weiterhin muss die Breite (horizontal) mindestens 640 Pixel und die Höhe (vertikal) mindestens 480 Pixel betragen.
Hat man die Auflösung zu groß oder zu klein eingestellt, dann startet das System mit der Standard-Auflösung von 1152x864 Pixeln.
Hält man diese Grundregeln ein, dann sind wie eben schon beschrieben praktisch alle dazwischen liegenden Auflösungen möglich.
Um die Änderungen zu übernehmen muss man den grub-Bootloader neu schreiben:
update-grub
Die geänderte Bildschirmauflösung wird erst nach einem Neustart übernommen:
reboot
48. UTC Zeitzone anpassen (pool.ntp.org):
Verwendet man zeitkritische Dienste, dann sollte man den Zeitserver Client entsprechend konfigurieren.
www.uhrzeit.org/atomuhr.php = Aktuelle Atom-Uhrzeit im Internet.
www.ntppool.org/de/use.html = Zeitserver im Internet howto.
Aktuelle Einstellungen anzeigen:
date = Das aktuelle Datum mit der Uhrzeit ausgeben.
cat /etc/timezone = Die aktuell gesetzte timezone (Zeitzone) ausgeben.
timedatectl = (Link) Ausgabe der lokalen und UTC Zeit (Coordinated Universal Time/koordinierte Weltzeit).
Alle im System verfügbaren Zeitzonen ausgeben:
timedatectl list-timezones = Zeigt alle Zeitzonen Weltweit an.
timedatectl list-timezones | grep Europe = Filtert die Ausgabe hier Beispielsweise für Europa. Beachtet dabei die englische Schreibweise für Europa -> Europe, also am Ende mit 'e' statt mit 'a'.
Zeitzone für Deutschland setzen:
timedatectl set-timezone Europe/Berlin = Setzt die UTC Zeitzone auf Berlin (+2 Stunden im Sommer, +1 Stunde im Winter).
Zeitserver festlegen (pool.ntp.org):
nano /etc/systemd/timesyncd.conf
Hier den Eintrag wie folgt anpassen:
...
[Time]
NTP=de.pool.ntp.org = Meine Empfehlung. Beachtet dabei das ihr das führende Kommentar '#' entfernt.
#FallbackNTP=ntp.ubuntu.com # Alternativer zweiter NTP-Server z. B.: pool.ntp.org
...
Beachtet weiterhin das die regelmäßige Zeitsynchronisierung aktiv sein muss:
timedatectl set-ntp 1 = (true) Die Zeitsynchronisation einschalten (normalerweise Standard).
timedatectl set-ntp 0 = (false) Datum-/Zeitsynchronisation ausschalten z. B. sinnvoll bei virtuellen Testsystemen.
Beachtet weiterhin, das ihr bei Virtualisierten Umgebungen die Zeitsynchronisierung mit dem Hostsystem ausschalten solltet.
Zeitsynchronisation unter VirtualBox abschalten (unter Windows):
Die Synchronisation der Uhrzeit mit dem Host ausschalten:
"c:\Program Files\Oracle\VirtualBox\
VBoxManage.exe" setextradata "VM_Name"
"VBoxInternal/Devices/VMMDev/
0/Config/GetHostTimeDisabled" "1"
Uhrzeitsynchronisation mit dem Host wieder einschalten mit:
"c:\Program Files\Oracle\VirtualBox\
VBoxManage.exe" setextradata "VM_Name"
"VBoxInternal/Devices/VMMDev/
0/Config/GetHostTimeDisabled" "0"
Zeitsynchronisation unter Hyper-V abschalten:
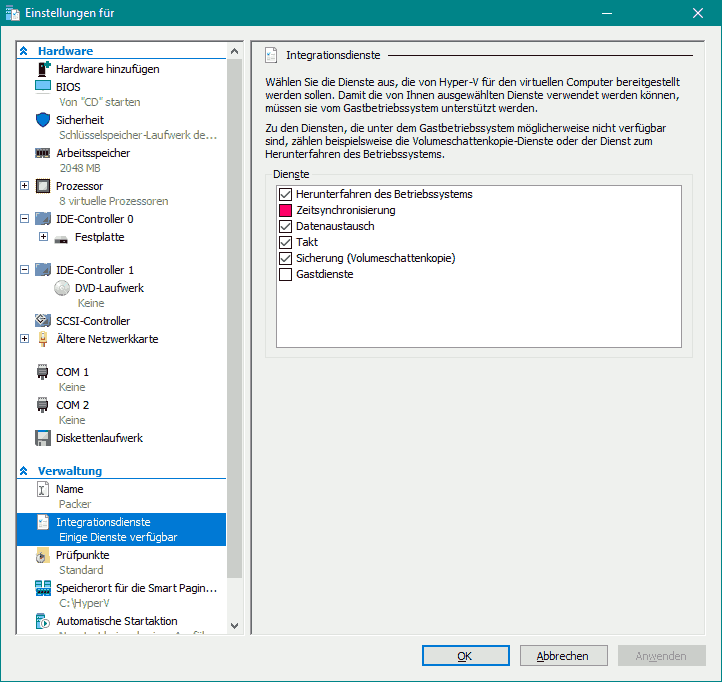
49. Remote-Desktop unter Ubuntu/Linux installieren/aktivieren:
Möchte man auf einen Linux Client oder Server grafisch über die Windows Remote-Desktop Funktion zugreifen, so geschieht das mittels xrdp.
Auf dem Client oder Server muss hierzu aber ein XServer bzw. genauer ein Desktop-Environment wie Xfce, KDE, GNOME o. ä. (also eine grafische Desktop-Umgebung) vorhanden sein.
Diese Umgebung muss dabei an einem Server nicht zwingend gestartet sein.
Wie ihr eine möglichst schlanke, ressourcensparende, abgespeckte, minimale Xfce4-Installation auf einem Server vornehmen könnt habe ich hier beschrieben.
xrdp installieren, aktivieren und die die notwendigen Ports in der Firewall freigeben:
apt install xrdp -y
systemctl enable --now xrdp
ufw allow 3389/tcp
Um nun von Windows aus auf das System zugreifen könnt ihr entweder wie gewohnt den Aufruf über die Windows 'Remotedesktopverbindung' verwenden
oder ihr legt euch eine Batch- bzw. CMD-Datei an, welche die Verbindung direkt startet (empfohlen).
Letzteres ist besonders Hilfreich, wenn man mehrere System betreuen muss.
Die entsprechende IP-Adresse bzw. der Hostname des Systems wird dann direkt mit übergeben.
Speichert unter Windows also folgendes z. B. als: 'RDP_Server_TEST.cmd' Batchdatei ab:
REM Aufruf bis Windows 10: Startet eine Remote-Desktop-Verbindung zur angegebenen IP-Adresse oder Hostname (diese anpassen).
REM Beim Verbindungsaufbau muss man entsprechend einen Benutzername und das Passwort eines Linux Users angeben.
REM Empfohlen wird die Variante mit der Nutzung der IP-Adresse:
start mstsc /v:192.168.0.37
REM Beachtet bei der Nutzung von Hostnamen ggf. die Namensauflösung bzw. vorhandene DNS-Einträge/hostname-Einträge.
REM Zugriffe über andere Netze/VPNs (unterwegs) lösen in der Regel Hostnamen nicht auf. Diese Variante wird daher weniger empfohlen.
start mstsc /v:hostname
REM Ab Windows 11 kann man den Usernamen (hier im Beispiel 'root') gleich mit übergeben.
REM Es ist dann nur noch eine Passworteingabe notwendig - dies ist Bedienerfreundlicher aber ggf. unsicherer.
REM Eine Angabe eines Usernamens kann die Sicherheit einer Umgebung deutlich herab setzen. Achtet hier auf eure Umgebung bzw. geltenden Richtlinien.
start mstsc /v:192.168.0.37 /u:root
Probleme/Lösungen/Hinweise:
Damit der Remote-Desktop zugriff klappt darf keine laufende Sitzung des Desktops bestehen/keine Anmeldung schon geschehen sein. Das war bei mir jedenfalls so.
Eine laufende grafische Linux Session (Desktop Umgebung) konnte ich so leider nicht wie von Windows aus gewohnt übernehmen.
Wenn bereits eine grafische Desktop Umgebung auf dem Linux Client/Server läuft erscheint möglicherweise kurz ein grafischer Bildschirm,
als wollte sich das System aufbauen, die Verbindung bricht dann aber gleich wieder ab - ein Verbindungsaufbau ist dann einfach nicht möglich.
Ich nutze xrdp wie eben beschrieben nur bei minimized Linux Servern wo normalerweise standardmäßig kein Xfce Desktop gestartet wird (installiert ist die Umgebung aber trotzdem).
Hier klappt dann diese Lösung wie oben beschrieben mit xrdp bei mir super.
Sollte dennoch mal jemand am Client/Server den grafischen Desktop gestartet haben, dann muss man diesen beenden.
Falls sich also die xrdp-Verbindung nicht aufbauen lässt, dann starte ich den betroffenen Linux Client/Server aus der Ferne einfach über eine SSH-Verbindung neu.
Danach war bei mir eine xrdp-Verbindung immer problemlos möglich.
Was ich schön finde das über xrdp über Remote-Desktop selbst zu Windows Systemen die üblichen Austauschmöglichkeiten bestehen.
Man kann so z. B. mittels Copy & Paste Inhalte und auch Dateien über die Zwischenablage austauschen.
Man kann übrigens nicht nur Text über die Zwischenablage sondern ganze Dateien so mit 'kopieren' und 'einfügen' übertragen.
Drag- n Drop zwischen den Systemen funktionierte bei mir übrigens dagegen nicht.
Abhängig vom Server und Datenumfang und der Netzwerkverbindung kann es manchmal etwas haken.
Größere Datenübertragungen zu einem Raspberry Pi funktionierten bei mir manchmal nur nach mehreren versuchen.
Grundsätzlich klappt es bei mir aber sehr gut. Hauptsächlich war dies der Leistung des langsamen Raspberry Pi zuzuschreiben.
Merkwürdigerweise ließen sich auch Texte mit Emojis im Text nicht über die Zwischenablage übertragen.
Dies liegt vermutlich daran dass bei einem minimized Setup Emojis und andere unwichtige Dinge fehlen.
Hier kann man sich dann aber behelfen in dem man die Texte als komplette Dateien (ggf. über Dateifreigaben o. ä.) überträgt.
Falls also mal Text sich nicht übernehmen lässt prüft diesen ggf. auf Sonderzeichen/Emojis ab.
Bzw. kopiert den Text dann einfach in einer gespeicherten Datei.
50. .pdf in .png Dateien umwandeln (z. B. Cover erstellen):
Um PDF in PNG Dateien umzuwandeln benötigt man das Programm 'pdftoppm'.
pdftoppm ist im Paket (package) poppler-utils enthalten.
Das Paket (package) poppler-utils enthält weiterhin neben 'pdftoppm' noch folgende nützliche Programme:
PDF-zu-Text-Konvertierung:
pdftotext - Extrahiert Text aus PDF-Dateien
pdftohtml - Konvertiert PDF zu HTML
PDF-zu-Bild-Konvertierung:
pdftoppm - Konvertiert PDF zu PPM/PNG/JPEG-Bildern
pdftops - Konvertiert PDF zu PostScript
PDF-Informationen und -Analyse:
pdfinfo - Zeigt Metadaten und Eigenschaften von PDF-Dateien
pdffonts - Listet alle in der PDF verwendeten Schriftarten auf
pdfimages - Extrahiert alle Bilder aus PDF-Dateien
pdfdetach - Extrahiert eingebettete Dateien aus PDFs
PDF-Manipulation:
pdfseparate - Trennt PDF in einzelne Seiten
pdfunite - Fügt mehrere PDFs zu einer Datei zusammen
Hier soll es nur darum gehen die erste Seite aus einem PDF-Dokument in ein Bild (.png) Datei umzuwandeln.
Ich nutzte dies Beispielsweise um Coverbilder einer Zeitung (hier jeweils nur die erste Seite) eines PDF-Dokuments,
zu extrahieren und als png-Datei zu speichern. Beliebige andere Anwendungen sind denkbar.
a) pdftoppm (aus poppler-utils) installieren sofern nicht schon installiert:
sudo apt update
sudo install poppler-utils
b) Es empfiehlt sich den Konvertierungsaufruf in einem Bash-Skript zu speichern 'pdf-to-image.sh':
nano pdf-to-image.sh
Hier dann folgendes einfügen:
#!/bin/bash
# Schleife über alle PDF-Dateien im Unterordner 'pdf-to-image' (der Ordner muss im Skript-Verzeichnis vorhanden sein)
for pdf in pdf-to-image/*.pdf; do
# Dateiname ohne .pdf-Endung
base=$(basename "$pdf" .pdf)
# Statusausgabe (verbose)
echo "Konvertiere: $pdf"
# pdftoppm:
# -f 1 = erste Seite (from page 1)
# -l 1 = bis Seite 1 (limit to page 1)
# -png = Ausgabeformat PNG
# Zielprefix: erzeugt Datei mit Suffix (... angehänger) -1.png
# Der automatisch angehängte Seitenanzahl-Suffix ist abhängig von der Seitenzahl des PDF-Quelldokumentes.
# Am Ende des Dateinamens, vor der Dateiendung .png, wird automatisch folgender Suffix angehängt:
# -1 = bei 1 - 9 Seiten
# -01 = bei 10 - 99 Seiten
# -001 = bei 100 - 999 Seiten usw.
# Beispiel: Bei einer 'Test.pdf' Datei mit 13 Seiten, erzeugt das Skript hier, folgende Zieldatei 'Test-Seite-01.png'.
pdftoppm -f 1 -l 1 -png "$pdf" "pdf-to-image/${base}-Seite"
done
c) Das Bash-Skript ausführbar machen:
chmod +x pdf-to-image.sh
d) Das Bash-Skript wird dann so gestartet:
./pdf-to-image.sh
Ergänzende Hinweise:
Im Ordner, bzw. genauer beliebig im Unterordner 'pdf-to-image' kann man nun beliebig viele PDF-Dokumente ablegen (es wird rekursiv gesucht).
Diese Dokumente werden dann vom Skrpt alle nacheinandere abgearbeitet.
Das Skript erzeugt nach dem Start zu jedem PDF-Dokument eine PNG-Datei im selben Ordner liegt und den Zusatz trägt "-Seite-1.png".
Der Zusatz, hier Beispeilsweise nur '-1' ist dabei abhängig wie viele Seiten das PDF-Dokument hat.
Bei Dokumenten von 10-99 Seiten würde "-Seite-01" angefügt.
Bei Dokumenten von 100-999 Seiten würde entsprechend "-Seite-001" angefügt usw.
Hintergrund ist der, man könnte ja alle Seiten extrahieren, daher wird der Suffix immer an die Seitenzahl des Dokumentes angepasst.
Beachtet auch, das Skript enthält keinerlei Fehlerbehandlungen um es möglichst schlicht/kurz zu halten.
Im produktiven automatisierten Betrieb sollten weitere Prüfungen je nach Sicherheitsanspruch vorab erfolgen.
51. .png, .jpeg Dateien in .jxl (JPEG XL) umwandeln:
cjxl unter Ubuntu kannst Du am einfachsten so installieren (es empfiehlt es sich die aktuelle Version zu nutzen):
Die offizielle Releases-Übersicht von
JPEG XL findest du unter:
https://github.com/libjxl/libjxl/releases
Hinweise:
Für die hier genutzten statischen Binaries sind in der Regel keine zusätzlichen Compiler-Tools oder Abhängigkeiten notwendig, da alle Bibliotheken bereits fest im Programm einkompiliert sind.
Das Entpacken erfordert lediglich die Standard-Werkzeuge
unzip und
tar.
Ein neues Verzeichnis für die aktuelle Version erzeugen und hineinwechseln:
mkdir cjxl_v0.11.2
cd cjxl_v0.11.2
Das offizielle, statisch vorbedachte Linux-Archiv herunterladen:
wget https://github.com/libjxl/libjxl/releases/download/v0.11.2/jxl-linux-x86_64-static.zip
Die verschachtelten Archive entpacken:
unzip jxl-linux-x86_64-static.zip
tar -xzf release_file.tar.gz # Entpackt die eigentlichen Binärdateien in den Unterordner
tools.
In den Tools-Ordner wechseln und den Encoder testen:
cd tools
./cjxl --version
Die fertig ausführbaren Programme liegen nun im
tools Verzeichnis. Um die Ausführung der Programme im System zu vereinfachen, sollte man am besten einen
Alias anlegen.
Öffnet dazu die 'Autostart-Datei' mit einem Editor:
nano ~/.bash_profile
Füge hier die gewünschten Aliase für die Werkzeuge ein (alle Tools als komfortable Oneliner):
alias cjxl=~/cjxl_v0.11.2/tools/cjxl # JPEG XL Encoder: Bilder ins hocheffiziente .jxl Format packen.
alias djxl=~/cjxl_v0.11.2/tools/djxl # JPEG XL Decoder: .jxl Dateien wieder zurück nach PNG oder JPEG wandelt.
alias cjpegli=~/cjxl_v0.11.2/tools/cjpegli # JPEGli Encoder: Erzeugt extrem optimierte, 100 % standardkonforme JPEGs.
alias djpegli=~/cjxl_v0.11.2/tools/djpegli # JPEGli Decoder: Dekodiert Bilder über die schnelle JPEGli-Bibliothek.
alias jxlinfo=~/cjxl_v0.11.2/tools/jxlinfo # JXL Info: Zeigt technische Metadaten und Eigenschaften einer .jxl Datei an.
alias benchmark_xl=~/cjxl_v0.11.2/tools/benchmark_xl # Benchmark: Testet die Encodierungs-Geschwindigkeit und Bitraten deiner CPU.
alias butteraugli_main=~/cjxl_v0.11.2/tools/butteraugli_main # Butteraugli: Psychovisuelle Metrik, misst sichtbare Bildfehler für das menschliche Auge.
alias ssimulacra2=~/cjxl_v0.11.2/tools/ssimulacra2 # SSIMULACRA 2: Moderner, präziser Qualitäts-Score für den automatisierten Bildvergleich.
Die Aliase sofort und ohne Terminal-Neustart aktivieren:
source ~/.bash_profile
Nach der Aktivierung sind der Konverter und alle Zusatzwerkzeuge direkt über ihre Befehlsnamen (z. B. [
cjxl] oder [
cjpegli]) von überall im System aufrufbar.
Version: 2026-05-21
Skript zur Optimierung von PNG/JPEG-Dateien nach JXL (Erklärung vorab):
Bilder werden standardmäßig in den Unterordner 'OPTIMAL' abgelegt – dort landet auch das zentrale Logfile.
Die Pfade lassen sich im Skript bei Bedarf entsprechend anpassen.
Es stehen 4 verschiedene Verarbeitungs-Modi zur Verfügung:
fast: Komprimiert zügig und testet nur die sinnvollsten und gängigsten Parameter-Kombinationen. Liefert schnell sehr gute, wenn auch nicht absolut maximale Ergebnisse.
deep: Sucht tiefgreifender nach dem optimalen Packalgorithmus. Dieser Modus ist für den produktiven Einsatz empfehlenswert, da oft noch kleinere Dateien erzeugt werden als im "fast"-Modus.
time: Hier wird ein festes Zeitbudget pro Bild vorgegeben (empfohlen).
Dies ist ideal für große Bildersammlungen, da das Ende der Verarbeitung verlässlich planbar ist.
In einer festgelegten Zeit werden erst die gängigsten, dann zunehmend feinere Algorithmen getestet.
Bei kleinen Bildern reicht die Zeit oft für sehr viele Iterationen, wodurch diese extrem hochoptimiert werden.
Größere Bilder haben zwar nur wenige Durchläufe bleiben trotzdem noch gut optimiert (optimale CPU/Rechenzeitnutzung).
Wichtig bitte beachten:
Durch die parallele Nutzung mehrerer CPU-Cores (ein Kern bleibt fürs System frei) werden mehrere Bilder gleichzeitig komprimiert!
Bei einem System mit z. B. 8 CPU-Kernen (das Skript nutzt hier 7 Kerne parallel);
werden z. B. bei 10 Bildern, mit einem Zeitlimit von 5 Minuten pro Bild, die ersten 7 Bilder gleichzeitig, danach die restlichen 3 komprimiert.
Die Gesamtdauer beträgt somit nicht 10 x 5 = 50 Minuten, sondern nur ca. 10 Minuten (2 Durchläufe × 5 Minuten).
Leichte zeitliche Schwankungen können entstehen, da eine bereits angefangene Kompressions-Iteration nicht hart abgebrochen wird.
ultra: Durchsucht im Brute-Force-Verfahren ausnahmslos alle erdenklichen Varianten (exakt 17216 Iterationen). Dies erzeugt also immer die kleinstmögliche jxl Datei.
Vorsicht: Dies dauert jedoch extrem lange. Ein kleines Testbild mit nur 7.975 Bytes benötigte auf einem Ryzen 7 5700G beispielsweise etwa 2 Tage für einen kompletten Durchlauf.
Diesen Modus sollte man also nur bei einzelnen, möglichst kleinen, extrem wichtigen statischen Logos starten, wenn es absolut zwingend notwendig ist.
Besonderheit bei JPEG-Dateien:
JPEG-Bilder werden über einen speziellen Prozess direkt transkodiert. Eine langwierige, tiefgehende Kompressionssuche macht bei bereits bestehenden JPEGs keinen Sinn. Diese Dateien sind daher in der Regel sehr schnell abgearbeitet.
Besonderheit bei PNG-Dateien:
PNG-Bilder und Logos, die sich gut verlustfrei packen lassen, werden hingegen intensiv und mehrfach durchsucht.
Je nach gewähltem Modus werden vorab definierte Parameter-Arrays getestet ("fast" oder "deep"), zeitgesteuert abgearbeitet ("time") oder komplett per Brute-Force berechnet ("ultra").
Wichtig: Es wird nach Abschluss aller Durchläufe egal in welchem Modus, immer nur die jeweils absolut kleinste Dateivariante behalten.
Zielsetzung und Dateivergleich:
Das Skript dient primär dazu, hochoptimierte Bilder, insbesondere für schnelle Webauftritte, zu generieren.
Da oftmals bereits Vorarbeiten geleistet wurden und Dateien im .webp- oder .avif-Format vorliegen, sollen am Ende nur die Datenmengen hochgeladen werden, die auch wirklich eine Speicherersparnis bringen.
Das Skript prüft daher am Ende automatisch, ob die Ursprungsdatei oder bereits bestehende .webp- oder .avif-Dateien kleiner sind.
Ist dies der Fall, wird die neu erzeugte .jxl-Datei direkt wieder verworfen und gar nicht erst gespeichert.
Beispielhafter Ablauf:
- Bild1.png (Das Ursprungsbild, meist vorab schon durch Tools wie zopfli, advpng oder optiPNG optimiert)
- Bild1.png.webp (Skript prüft, ob diese Datei bereits existiert und wie groß sie ist)
- Bild1.png.avif (Skript prüft ebenfalls, ob diese Datei existiert und wie groß sie ist)
- Bild1.png.jxl (Die optimierte .jxl-Datei wird nur dann final erzeugt und behalten, wenn sie am Ende nachweislich kleiner ist als alle anderen vorherigen Varianten)
Hier nun das Skript womit ihr mehrere Bilder Sinnvoll in .jxl Umwandeln könnt:
#!/bin/bash
# Script-Beschreibung: Konvertiert png, jpg & jpeg in hochoptimierte .jxl (JPEG XL).
# Ultimative Brute-Force Edition mit umschaltbarem FAST/DEEP/TIME/ULTRA Modus.
# Inklusive Live-ETA, paralleler Byte-Verfolgung und Abschluss-Statistik.
# Version: 2026-05-29 - Optimiert fuer Multi-Core, sauberes Logging, RAM-UI & Iterations-ETA (Fix).
# apt update
# apt install imagemagick libjxl-tools -y
# Hinweis: libjxl-tool scheint derzeit nur bei Ubuntu 24.04.x zur Verfügung zu stehen. Unter Unbuntu 26.04.x gibt es dieses Paket offenbar nicht.
# Es wird sowieso die Installation der aktuellen v0.11.2 oder höher siehe oben empfohlen wenn möglich.
# ImageMagick wird benötigt um zu prüfen, ob ein Bild (png) einen Alpha-Kanal hat (mittels 'identify -format'),
# um diese Transparenz bei der Kompression sofern vorhanden entsprechend zu berücksichtigen.
xset s off -dpms 2>/dev/null || true # Bildschirm-/Energiesparmodus ausschalten:
# ==========================================
# 1. KONFIGURATION (Hier anpassen)
# ==========================================
PFAD="." # '.' bedeutet: starte im aktuellen Verzeichnis
JXL_DISTANCE=5 # Qualitaet fuer die lossy Variante (kleiner oder gleich = 1, nahezu verlustfrei, um so größer um so kleiner werden die Dateien (verlustbehaftet)
# Achtung Werte über 20 produzierten bei mir Fehler. empfohlen werden Werte von 1-3 wenn man weiter damit arbeiten will.
# Fürs Web scheint mir 5 ein sinnvoller Wert zu sein. Ich würde Werte zwischen 1-9 empfehlen.
JXL_EFFORT=9 # Maximaler Effort fuer kleinste Dateien (1-9)
USE_CORES=$(nproc)
MAX_JOBS=$((USE_CORES - 1))
[[ $MAX_JOBS -lt 1 ]] && MAX_JOBS=1
COMP_MODE="time" # fast = Schneller Durchlauf, deep = Hardcore, time = Zeitbudget, ultra = 100 % Brute-Force ('time' meist empfohlen)
MAX_TIME_PER_IMAGE=5 # Minuten pro Bild (nur bei COMP_MODE="time")
WRITE_DETAIL_LOG=false # true = .jxl-stats.log fuer jede Datei erzeugen, false = keine Detail-Logs
SORT_MODE="asc" # asc = kleinste zuerst (aufsteigend), desc = groesste zuerst (absteigend), name = A-Z sortiert
# ==========================================
# LOOP SETUP (Arrays werden nun korrekt in Phase 1 genutzt!)
# ==========================================
if [ "$COMP_MODE" = "fast" ]; then
# Suchen nur nach den gaengigsten, erfolgreichsten Kombinationen (Spart massiv Zeit)
LOOP_C=(0 6) # Colorspace: 0=RGB, 6=YCoCg
LOOP_G=(0 2) # Group Size: 128 (0), 512 (2)
LOOP_P=(0 5 6 14 15) # Predictors: Nur die meist erfolgreichsten
LOOP_PATCH=(1) # Patches (Mustererkennung): Fest auf An
LOOP_PAL=(0 256) # Palette: Aus, max 256
echo -e "\n\033[36mStarte JXL-Crusher (FAST-MODE) mit $MAX_JOBS parallelen Jobs...\033[0m\n"
elif [ "$COMP_MODE" = "deep" ]; then
# Der Deep-Loop fuer das Wochenende (Testet Phase 1 komplett durch)
LOOP_C=(0 6) # Colorspace: 0=RGB, 6=YCoCg
LOOP_G=(0 1 2) # Group Size: 128, 256, 512
LOOP_P=({0..15}) # Predictors: Alle 16 Varianten
LOOP_PATCH=(0 1) # Patches (Mustererkennung): Aus, An
LOOP_PAL=(0 16 256 1024) # Palette: Aus, max 16, 256, 1024
echo -e "\n\033[36mStarte JXL-Crusher (DEEP-MODE) mit $MAX_JOBS parallelen Jobs...\033[0m\n"
elif [ "$COMP_MODE" = "ultra" ]; then
# Ultra-Modus: Ignoriert jegliches Zeitlimit und durchlaeuft Phase 1, 2 und 3 restlos.
LOOP_C=(0 6)
LOOP_G=(0 1 2)
LOOP_P=({0..15})
LOOP_PATCH=(0 1)
LOOP_PAL=(0 16 256 1024)
echo -e "\n\033[36mStarte JXL-Crusher (ULTRA-MODE, 100 % Brute-Force) mit $MAX_JOBS parallelen Jobs...\033[0m\n"
else
# TIME-MODE: Zeitbudget-gesteuert
LOOP_C=(0 6)
LOOP_G=(0 1 2)
LOOP_P=({0..15})
LOOP_PATCH=(0 1)
LOOP_PAL=(0 16 256 1024)
echo -e "\n\033[36mStarte JXL-Crusher (TIME-MODE, Budget: ${MAX_TIME_PER_IMAGE}min/Bild) mit $MAX_JOBS parallelen Jobs...\033[0m\n"
fi
# ==========================================
# LOGGING & TEMPORAERE VERWALTUNG
# ==========================================
SCRIPT_START=$(date +%s)
# Erstelle OPTIMAL Ordner, falls nicht vorhanden, um Fehler beim LOG_FILE zu vermeiden
mkdir -p "${PFAD}/OPTIMAL"
LOG_FILE="${PFAD}/OPTIMAL/__jxl_log_$(date -d "@$SCRIPT_START" "+%y%m%d_%H%M").txt"
echo "=== JXL Konvertierungs-Log | Start: $(date -d "@$SCRIPT_START" "+%H:%M:%S Uhr, %d.%m.%y") ===" > "$LOG_FILE"
export LOG_FILE
STATS_DIR=$(mktemp -d)
STATUS_DIR=$(mktemp -d)
# Stellt sicher, dass das Temp-Verzeichnis am Ende geloescht wird, auch bei STRG+C
trap 'rm -rf "$STATS_DIR" "$STATUS_DIR"' EXIT
# Hilfsfunktion zur Zeitformatierung in "d hh:mm:ss"
format_time() {
local T=$1
local D=$((T/60/60/24))
local H=$((T/60/60%24))
local M=$((T/60%60))
local S=$((T%60))
if [ $D -gt 0 ]; then
printf "%dd %02d:%02d:%02d" $D $H $M $S
else
printf "%02d:%02d:%02d" $H $M $S
fi
}
export -f format_time
# Hilfsfunktion zur Formatierung in "MM:SS" (fuer das Live-Log)
format_mm_ss() {
local total_sec=$1
local m=$((total_sec / 60))
local s=$((total_sec % 60))
printf "%02d:%02d" $m $s
}
export -f format_mm_ss
# ==========================================
# 2. DATEISUCHE UND GLOBALE ETA-BERECHNUNG
# ==========================================
# Sortierlogik fuer die Dateisuche
if [ "$SORT_MODE" = "asc" ]; then
mapfile -d $'\0' images < <(find "$PFAD" -type f \( -iname "*.png" -o -iname "*.jpg" -o -iname "*.jpeg" \) -printf "%s\t%p\0" | sort -z -n | cut -z -f2-)
elif [ "$SORT_MODE" = "desc" ]; then
mapfile -d $'\0' images < <(find "$PFAD" -type f \( -iname "*.png" -o -iname "*.jpg" -o -iname "*.jpeg" \) -printf "%s\t%p\0" | sort -z -n -r | cut -z -f2-)
else
mapfile -d $'\0' images < <(find "$PFAD" -type f \( -iname "*.png" -o -iname "*.jpg" -o -iname "*.jpeg" \) -print0 | sort -z)
fi
TOTAL=${#images[@]}
TOTAL_BYTES=0
TOTAL_ITERATIONS=0
echo "Analysiere Bilder und berechne Gesamt-Iterationen fuer praezises ETA..."
for img in "${images[@]}"; do
size=$(stat -c%s "$img")
TOTAL_BYTES=$((TOTAL_BYTES + size))
ext_org="${img##*.}"
smal_ext="${ext_org,,}"
if [[ "$smal_ext" == "png" ]]; then
has_alpha=0
if identify -format '%[channels]' "$img" 2>/dev/null | grep -qi 'alpha'; then
has_alpha=1
fi
img_iters=0
if [ "$COMP_MODE" = "fast" ]; then img_iters=40; fi
if [ "$COMP_MODE" = "deep" ]; then img_iters=768; fi
if [[ "$COMP_MODE" == "ultra" || "$COMP_MODE" == "time" ]]; then
k_opts=1
[ "$has_alpha" -eq 1 ] && k_opts=2
# Phase 1 (768) + Phase 2 (1088) + Phase 3 (15360 * alpha-faktor)
img_iters=$(( 768 + 1088 + (15360 * k_opts) ))
fi
TOTAL_ITERATIONS=$((TOTAL_ITERATIONS + img_iters))
else
TOTAL_ITERATIONS=$((TOTAL_ITERATIONS + 2)) # Standard-Wert für JPGs
fi
done
TOTAL_MB=$(awk "BEGIN {printf \"%.2f\", $TOTAL_BYTES/1048576}")
echo -e "Es wurden \033[33m${TOTAL}\033[0m Bilder gefunden (Gesamtgroesse: ${TOTAL_MB} MB). Beginne Verarbeitung...\n"
export TOTAL_ITERATIONS
# ==========================================
# 3. DIE KONVERTIERUNGS-FUNKTION
# ==========================================
process_image() {
local img_start_time=$(date +%s)
local img="$1"
local ext_org="${img##*.}"
local smal_ext="${ext_org,,}"
local file_path=$(dirname "${img}")
local file_name=$(basename "$img" ".${ext_org}")
local new_name="${file_path}/${file_name}.${smal_ext}.jxl"
local webp_name="${file_path}/${file_name}.${smal_ext}.webp"
local avif_name="${file_path}/${file_name}.${smal_ext}.avif"
local stat_log="${file_path}/${file_name}.jxl-stats.log"
local current_tmp="${img}.jxl_tmp"
local best_tmp="${img}.jxl_best.tmp"
# Sicherstellen, dass keine Reste von abgebrochenen Laeufen vorhanden sind
rm -f "${current_tmp}" "${best_tmp}"
local size_org=$(stat -c%s "${img}")
local final_used_size=$size_org
local last_log_time=0
# Zentralisierte Log-Funktion: Screen-Ausgabe UND sauberes Schreiben ins Logfile (120 Sekunden Bremse)
img_log() {
local msg="$1"
local force="${2:-0}"
local matrix_str="${3:-}"
local now=$(date +%s)
# Nur ausgeben, wenn forciert (z.B. neuer Bestwert, Verwerfen) oder 120 Sekunden seit letzter Ausgabe vergangen sind
if [ "$force" -eq 1 ] || [ $((now - last_log_time)) -ge 120 ]; then
last_log_time=$now
local elapsed_sec=$(( now - img_start_time ))
local el_str=$(format_mm_ss $elapsed_sec)
local prefix=""
[ -n "$matrix_str" ] && prefix="\033[35m${matrix_str}\033[0m "
# 1. Ausgabe ins Terminal (mit Farben)
echo -e "\033[2K\r[\033[33m${el_str}\033[0m] ${prefix}\033[1m${file_name}.${ext_org}\033[0m | ${msg}"
# 2. Reine Textausgabe in die Log-Datei (Alle ANSI-Farbcodes und Wagenruecklaeufe strikt herausfiltern)
local clean_msg=$(echo -e "$msg" | sed -r "s/\x1B\[[0-9;]*[a-zA-Z]//g" | tr -d '\r')
local clean_matrix=$(echo -e "$matrix_str" | sed -r "s/\x1B\[[0-9;]*[a-zA-Z]//g")
local ts=$(date "+%H:%M:%S")
local prefix_clean=""
[ -n "$clean_matrix" ] && prefix_clean="${clean_matrix} "
echo "[${ts}] [${el_str}] ${prefix_clean}${file_name}.${ext_org} | ${clean_msg}" >> "$LOG_FILE"
fi
}
# --- ITERATIONS-BERECHNUNG FUER DIE FORTSCHRITTS-MATRIX DIESES BILDES ---
local has_alpha=0
if identify -format '%[channels]' "${img}" 2>/dev/null | grep -qi 'alpha'; then
has_alpha=1
fi
local t_phase1=$(( ${#LOOP_C[@]} * ${#LOOP_G[@]} * ${#LOOP_P[@]} * ${#LOOP_PATCH[@]} * ${#LOOP_PAL[@]} ))
local t_phase2=0
local t_phase3=0
if [[ "$COMP_MODE" == "time" || "$COMP_MODE" == "ultra" ]]; then
# Phase 2: 17 Colorspaces * 2 Groups * 16 Predictors * 2 Patches * 1 Palette = 1088 Iterationen
t_phase2=1088
# Phase 3: 24 Colorspaces * 2 Groups * 16 Predictors * 2 Patches * 5 Paletten * 2 Lossy-Pals * (1 oder 2) Alpha-Optionen
local keep_inv_opts=1
[ "$has_alpha" -eq 1 ] && keep_inv_opts=2
t_phase3=$(( 15360 * keep_inv_opts ))
fi
local total_combos=$(( t_phase1 + t_phase2 + t_phase3 ))
[ "$total_combos" -eq 0 ] && total_combos=1 # Fallback
if [[ "$smal_ext" != "png" ]]; then
total_combos=2 # Manuelles Limit für JPG
fi
local combinations_processed=0
# Hilfsfunktion fuer den Ladebalken unten
update_progress() {
# Wir uebergeben jetzt exakt die Anzahl der geschafften vs. totalen Iterationen an das Hauptskript
echo "$combinations_processed $total_combos" > "$STATUS_DIR/$BASHPID.progress"
}
# Status 2 = Uebersprungen (bereits vorhanden) -> erhoeht Zaehler am Ende sofort
if [ -f "${new_name}" ]; then
local existing_size=$(stat -c%s "${new_name}")
img_log "JXL bereits vorhanden. Ueberspringe. (Groesse: ${existing_size} B)" 1
# Uebergabe in stat-Datei: Groesse, Finale Groesse, Status, Gesamt-Iterationen dieses Bildes
echo "$size_org $existing_size 2 $total_combos" > "$STATS_DIR/$BASHPID.stat"
return 0
fi
img_log "Starte Bearbeitung (Original: $size_org Bytes)" 1
echo "0 $total_combos" > "$STATUS_DIR/$BASHPID.progress"
# ==========================================
# INITIALER DATEIVERGLEICH (Ziel-Marke setzen)
# ==========================================
local size_webp=99999999999
local size_avif=99999999999
[ -f "${webp_name}" ] && size_webp=$(stat -c%s "${webp_name}")
[ -f "${avif_name}" ] && size_avif=$(stat -c%s "${avif_name}")
local current_best_size=$size_org
[ "$size_webp" -lt "$current_best_size" ] && current_best_size=$size_webp
[ "$size_avif" -lt "$current_best_size" ] && current_best_size=$size_avif
# ==========================================
# LOSSY DURCHLAUF (mit --lossless_jpeg=0 damit -d bei JPGs greift)
# ==========================================
img_log "Erzeuge lossy Variante (Qualitaet/Distanz ${JXL_DISTANCE})..." 1
# Die "assuming sRGB" Meldung wird hier per grep -v aussortiert, bevor sie ins Log geht!
cjxl "${img}" "${current_tmp}" -d "${JXL_DISTANCE}" -e "${JXL_EFFORT}" --lossless_jpeg=0 --brotli_effort=11 --keep_invisible=0 --quiet 2>&1 | grep -v "assuming sRGB" >> "$LOG_FILE"
if [ -f "${current_tmp}" ]; then
local lossy_size=$(stat -c%s "${current_tmp}")
if [ "$lossy_size" -lt "$current_best_size" ]; then
current_best_size=$lossy_size
mv -f "${current_tmp}" "${best_tmp}"
img_log "\033[32mNeuer Bestwert (Lossy):\033[0m ${current_best_size} B" 1
else
img_log "\033[33mLossy verworfen:\033[0m Dateigroesse groesser als Referenz (${lossy_size} B >= ${current_best_size} B)" 1
rm -f "${current_tmp}"
fi
fi
if [[ "$smal_ext" == "png" ]]; then
img_log "[PNG] Starte Brute-Force (Gesamt: ${total_combos} Iterationen)..." 1
local best_params=""
local bf_start=$(date +%s)
if [ "$WRITE_DETAIL_LOG" = true ]; then
echo "C | G | P | PATCH | PALETTE | SIZE (Bytes) | TIME (s)" > "$stat_log"
fi
# ==========================================
# PHASE 1: Haupt-Loop (768 Iterationen im Ultra/Deep-Modus)
# ==========================================
local phase1_start=$bf_start
local phase1_combos=0
local TIME_EXCEEDED=0
for c in "${LOOP_C[@]}"; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for g in "${LOOP_G[@]}"; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for p in "${LOOP_P[@]}"; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for patch in "${LOOP_PATCH[@]}"; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for pal in "${LOOP_PAL[@]}"; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
local run_start=$(date +%s)
cjxl "${img}" "${current_tmp}" -d 0 -e "${JXL_EFFORT}" -m 1 -C "$c" -g "$g" -P "$p" \
--patches="$patch" --modular_palette_colors="$pal" \
--brotli_effort=11 --keep_invisible=0 --quiet 2>&1 | grep -v "assuming sRGB" >> "$LOG_FILE"
local run_end=$(date +%s)
local run_time=$((run_end - run_start))
((combinations_processed++))
((phase1_combos++))
# Dynamischer Matrix-String zur Anzeige inkl. Gesamt-Fortschritt
local m_str="[${combinations_processed}/${total_combos}] [C:${c}|G:${g}|P:${p}|Pa:${patch}|Pal:${pal}]"
img_log "Phase 1 laeuft..." 0 "$m_str"
if [ $((combinations_processed % 10)) -eq 0 ]; then
update_progress
fi
if [ -f "${current_tmp}" ]; then
local current_size=$(stat -c%s "${current_tmp}")
if [ "$WRITE_DETAIL_LOG" = true ]; then
echo "$c | $g | $p | $patch | $pal | $current_size | $run_time" >> "$stat_log"
fi
if [ "$current_size" -lt "$current_best_size" ]; then
current_best_size=$current_size
best_params="-C $c -g $g -P $p --patches $patch --pal $pal"
mv -f "${current_tmp}" "${best_tmp}"
img_log "\033[32mNeuer Bestwert (Phase 1):\033[0m ${current_best_size} B" 1 "$m_str"
else
rm -f "${current_tmp}"
fi
fi
# Zeitbudget-Pruefung nur im TIME-MODE
if [ "$COMP_MODE" = "time" ]; then
local elapsed=$((run_end - bf_start))
local max_seconds=$((MAX_TIME_PER_IMAGE * 60))
if [ "$elapsed" -ge "$max_seconds" ]; then
img_log "\033[31mZeitbudget in Phase 1 erreicht! Abbruch.\033[0m" 1
TIME_EXCEEDED=1
fi
fi
done
done
done
done
done
local phase1_end=$(date +%s)
local phase1_duration=$((phase1_end - phase1_start))
img_log "Phase 1 beendet: ${phase1_combos} Kombinationen in ${phase1_duration}s." 1
# ==========================================
# PHASE 2: Engmaschiger Zusatz (1088 Iterationen)
# ==========================================
if [[ "$COMP_MODE" == "time" || "$COMP_MODE" == "ultra" ]] && [ "$TIME_EXCEEDED" -eq 0 ]; then
local elapsed_so_far=$((phase1_end - bf_start))
local max_seconds=$((MAX_TIME_PER_IMAGE * 60))
local remaining=$((max_seconds - elapsed_so_far))
# Im Ultra-Modus ignorieren wir remaining und zwingen es auf > 60
[ "$COMP_MODE" = "ultra" ] && remaining=9999
if [ "$remaining" -gt 60 ]; then
img_log "Phase 2 (Engmaschig) startet..." 1
local phase2_start=$(date +%s)
local phase2_combos=0
for c in -1 {1..5} {7..17}; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for g in -1 3; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for p in {0..15}; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for patch in 0 1; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for pal in -1; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
local run_start=$(date +%s)
cjxl "${img}" "${current_tmp}" -d 0 -e "${JXL_EFFORT}" -m 1 -C "$c" -g "$g" -P "$p" \
--patches="$patch" --modular_palette_colors="$pal" \
--brotli_effort=11 --keep_invisible=0 --quiet 2>&1 | grep -v "assuming sRGB" >> "$LOG_FILE"
local run_end=$(date +%s)
local run_time=$((run_end - run_start))
((combinations_processed++))
((phase2_combos++))
local m_str="[${combinations_processed}/${total_combos}] [C:${c}|G:${g}|P:${p}|Pa:${patch}|Pal:${pal}]"
img_log "Phase 2 laeuft..." 0 "$m_str"
if [ $((combinations_processed % 10)) -eq 0 ]; then
update_progress
fi
if [ -f "${current_tmp}" ]; then
local current_size=$(stat -c%s "${current_tmp}")
if [ "$WRITE_DETAIL_LOG" = true ]; then
echo "$c | $g | $p | $patch | $pal | $current_size | $run_time" >> "$stat_log"
fi
if [ "$current_size" -lt "$current_best_size" ]; then
current_best_size=$current_size
best_params="-C $c -g $g -P $p --patches $patch --pal $pal"
mv -f "${current_tmp}" "${best_tmp}"
img_log "\033[32mNeuer Bestwert (Phase 2):\033[0m ${current_best_size} B" 1 "$m_str"
else
rm -f "${current_tmp}"
fi
fi
if [ "$COMP_MODE" = "time" ]; then
local total_elapsed=$((run_end - bf_start))
if [ "$total_elapsed" -ge "$max_seconds" ]; then
img_log "\033[31mZeitbudget in Phase 2 erreicht! Abbruch.\033[0m" 1
TIME_EXCEEDED=1
fi
fi
done
done
done
done
done
local phase2_end=$(date +%s)
local phase2_duration=$((phase2_end - phase2_start))
img_log "Phase 2 beendet: ${phase2_combos} Kombinationen in ${phase2_duration}s." 1
# ==========================================
# PHASE 3: Feinste Suche (Laengste Phase)
# ==========================================
if [ "$TIME_EXCEEDED" -eq 0 ]; then
local elapsed_after_p2=$((phase2_end - bf_start))
local remaining_after_p2=$((max_seconds - elapsed_after_p2))
[ "$COMP_MODE" = "ultra" ] && remaining_after_p2=9999
if [ "$remaining_after_p2" -gt 60 ]; then
img_log "Phase 3 (Feinste Suche) startet..." 1
local phase3_start=$(date +%s)
local phase3_combos=0
for c in {18..41}; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for g in -1 3; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for p in {0..15}; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for patch in 0 1; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for pal in -1 0 16 256 1024; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
for lossy_pal in 0 1; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
local keep_inv_values=(0)
if [ "$has_alpha" -eq 1 ]; then
keep_inv_values=(0 1)
fi
for keep_inv in "${keep_inv_values[@]}"; do
[ "$TIME_EXCEEDED" -eq 1 ] && break
local run_start=$(date +%s)
local lossy_pal_flag=""
if [ "$lossy_pal" -eq 1 ]; then
lossy_pal_flag="--modular_lossy_palette"
fi
cjxl "${img}" "${current_tmp}" -d 0 -e "${JXL_EFFORT}" -m 1 -C "$c" -g "$g" -P "$p" \
--patches="$patch" --modular_palette_colors="$pal" \
--brotli_effort=11 --keep_invisible="$keep_inv" \
$lossy_pal_flag --quiet 2>&1 | grep -v "assuming sRGB" >> "$LOG_FILE"
local run_end=$(date +%s)
local run_time=$((run_end - run_start))
((combinations_processed++))
((phase3_combos++))
local m_str="[${combinations_processed}/${total_combos}] [C:${c}|G:${g}|P:${p}|Pa:${patch}|Pal:${pal}]"
img_log "Phase 3 laeuft..." 0 "$m_str"
if [ $((combinations_processed % 10)) -eq 0 ]; then
update_progress
fi
if [ -f "${current_tmp}" ]; then
local current_size=$(stat -c%s "${current_tmp}")
if [ "$WRITE_DETAIL_LOG" = true ]; then
echo "$c | $g | $p | $patch | $pal | $current_size | $run_time | keep=$keep_inv | lossy_pal=$lossy_pal" >> "$stat_log"
fi
if [ "$current_size" -lt "$current_best_size" ]; then
current_best_size=$current_size
best_params="-C $c -g $g -P $p --patches $patch --pal $pal --keep_inv $keep_inv"
if [ "$lossy_pal" -eq 1 ]; then
best_params="${best_params} --modular_lossy_palette"
fi
mv -f "${current_tmp}" "${best_tmp}"
img_log "\033[32mNeuer Bestwert (Phase 3):\033[0m ${current_best_size} B" 1 "$m_str"
else
rm -f "${current_tmp}"
fi
fi
if [ "$COMP_MODE" = "time" ]; then
local total_elapsed=$((run_end - bf_start))
if [ "$total_elapsed" -ge "$max_seconds" ]; then
img_log "\033[31mZeitbudget in Phase 3 erreicht! Abbruch.\033[0m" 1
TIME_EXCEEDED=1
fi
fi
done
done
done
done
done
done
done
local phase3_end=$(date +%s)
local phase3_duration=$((phase3_end - phase3_start))
img_log "Phase 3 beendet: ${phase3_combos} Kombinationen in ${phase3_duration}s." 1
else
img_log "Ueberspringe Phase 3 (nur noch ${remaining_after_p2}s uebrig)." 1
fi
fi
else
img_log "Ueberspringe Phase 2 & 3 (nur noch ${remaining}s uebrig)." 1
fi
local bf_end=$(date +%s)
local bf_total=$((bf_end - bf_start))
img_log "Gesamt-Bruteforce beendet in ${bf_total}s (${combinations_processed} Combos). Beste gefundene Groesse: ${current_best_size} B." 1
else
local bf_end=$(date +%s)
local bf_total=$((bf_end - bf_start))
img_log "Gesamt-Bruteforce beendet in ${bf_total}s. Beste gefundene Groesse: ${current_best_size} B." 1
fi
else
img_log "[JPG] Starte verlustfreie JPEG-Transkodierung..." 1
cjxl "${img}" "${current_tmp}" -d 0 -e "${JXL_EFFORT}" -j 1 --brotli_effort=11 --quiet 2>&1 | grep -v "assuming sRGB" >> "$LOG_FILE"
if [ -f "${current_tmp}" ]; then
local lossless_size=$(stat -c%s "${current_tmp}")
if [ "$lossless_size" -lt "$current_best_size" ]; then
current_best_size=$lossless_size
mv -f "${current_tmp}" "${best_tmp}"
img_log "\033[32mNeuer Bestwert (JPG Lossless):\033[0m ${current_best_size} B" 1
else
img_log "\033[33mJPG Lossless verworfen:\033[0m Zu gross (${lossless_size} B >= ${current_best_size} B)" 1
rm -f "${current_tmp}"
fi
fi
combinations_processed=$total_combos
update_progress
fi
# ==========================================
# FINALER ABSCHLUSS DES BILDES
# ==========================================
local generated_status=0
if [ -f "${best_tmp}" ]; then
img_log "\033[32mJXL ist die kleinste Variante ($current_best_size B)!\033[0m Wird gespeichert." 1
mv -f "${best_tmp}" "${new_name}"
final_used_size=$current_best_size
generated_status=1
else
img_log "\033[31mJXL verworfen:\033[0m Original oder WebP/AVIF Referenz ist kleiner (${current_best_size} B)." 1
final_used_size=$size_org
generated_status=0
fi
# Fortschritts-Datei VOR der Statistik-Datei loeschen (verhindert doppelte Zaehlung in update_ui)
rm -f "$STATUS_DIR/$BASHPID.progress" 2>/dev/null
# Statistik fuer ETA und Endreport in Temp-Verzeichnis (inkl. Iterationen fuer exaktes ETA)
echo "$size_org $final_used_size $generated_status $total_combos" > "$STATS_DIR/$BASHPID.stat"
}
export -f process_image
export JXL_DISTANCE JXL_EFFORT COMP_MODE MAX_TIME_PER_IMAGE
export STATS_DIR STATUS_DIR WRITE_DETAIL_LOG LOG_FILE
export LOOP_C LOOP_G LOOP_P LOOP_PATCH LOOP_PAL
export TOTAL_ITERATIONS
# ==========================================
# 4. MULTI-CORE VERARBEITUNG & LIVE-UI
# ==========================================
# Funktion fuer die Live-Statusanzeige mit Iterations-ETA
update_ui() {
current_done=0
created_count=0
completed_iters=0
# Sammle alle PIDs, die bereits eine .stat-Datei haben (fertige Bilder)
declare -A done_pids
for stat_file in "$STATS_DIR"/*.stat; do
[ -f "$stat_file" ] || continue
local pid=$(basename "$stat_file" .stat)
done_pids[$pid]=1
# Lese Org-Groesse, Ziel-Groesse, Erzeugungs-Status und Iterationen aus
read org fin status iters < "$stat_file"
((current_done++))
completed_iters=$((completed_iters + iters))
# Zaehle erfolgreich erzeugte JXL (Status 1)
if [ "$status" = "1" ]; then
((created_count++))
fi
done
# Zaehle Iterationen der noch laufenden Bilder
local active_iters=0
for prog_file in "$STATUS_DIR"/*.progress; do
[ -f "$prog_file" ] || continue
local pid=$(basename "$prog_file" .progress)
# Ueberspringe, wenn dieses Bild schon fertig ist
[ "${done_pids[$pid]}" = "1" ] && continue
read p_iters t_iters < "$prog_file"
active_iters=$((active_iters + p_iters))
done
local total_done_iters=$((completed_iters + active_iters))
local elapsed=$(( $(date +%s) - SCRIPT_START ))
[ "$elapsed" -eq 0 ] && elapsed=1
local formatted_eta="berechne..."
if [ "$COMP_MODE" = "time" ]; then
# Im Time-Modus laufen Bilder parallel.
# Die verbleibende Zeit = (verbleibende Bilder / parallele Jobs) * Zeit pro Bild
local remaining_images=$(( TOTAL - current_done ))
local batches=$(( (remaining_images + MAX_JOBS - 1) / MAX_JOBS ))
local eta_sec=$(( batches * MAX_TIME_PER_IMAGE * 60 ))
formatted_eta=$(format_time $eta_sec)
else
# In allen anderen Modi errechnen wir das ETA extrem praezise
if [ "$total_done_iters" -gt 0 ]; then
local remaining_iters=$(( TOTAL_ITERATIONS - total_done_iters ))
[ "$remaining_iters" -lt 0 ] && remaining_iters=0
# FIX: Wir multiplizieren zuerst und teilen dann.
# Das verhindert, dass Bash Nachkommastellen (wie 0,87 Iterationen/Sek) als 0 wertet und das ETA abbricht.
local eta_sec=$(( (remaining_iters * elapsed) / total_done_iters ))
formatted_eta=$(format_time $eta_sec)
fi
fi
# Sekuendlich: Ueberschreibt nur lautlos die aktuelle unterste Zeile
echo -ne "\033[2K\r[\033[32mAbgearbeitet: $current_done / $TOTAL\033[0m | \033[36mErzeugt: $created_count\033[0m] [ETA: \033[33m$formatted_eta\033[0m]"
}
# Hauptschleife
for img in "${images[@]}"; do
# Warten, falls alle CPU-Kerne belegt sind (mit Live-UI)
while (( $(jobs -r -p | wc -l) >= MAX_JOBS )); do
update_ui
sleep 1
done
process_image "$img" &
done
# Auf restliche Hintergrundprozesse warten (mit Live-UI)
while (( $(jobs -r -p | wc -l) > 0 )); do
update_ui
sleep 1
done
# Die letzte laufende Statuszeile loeschen, fuer sauberen Abschluss-Report
echo -ne "\033[2K\r"
# ==========================================
# 5. FINALER ABSCHLUSS-REPORT
# ==========================================
SCRIPT_END=$(date +%s)
TOTAL_DURATION=$((SCRIPT_END - SCRIPT_START))
FORMATTED_TOTAL=$(format_time $TOTAL_DURATION)
ORG_SUM=0
FIN_SUM=0
CREATED_SUM=0
DISCARDED_SUM=0
SKIPPED_SUM=0
# Summiere alle Ergebnisse aus dem Temp-Ordner
for stat_file in "$STATS_DIR"/*.stat; do
[ -f "$stat_file" ] || continue
read org fin status iters < "$stat_file"
ORG_SUM=$((ORG_SUM + org))
FIN_SUM=$((FIN_SUM + fin))
if [ "$status" = "1" ]; then
((CREATED_SUM++))
elif [ "$status" = "0" ]; then
((DISCARDED_SUM++))
elif [ "$status" = "2" ]; then
((SKIPPED_SUM++))
fi
done
ORG_MB=$(awk "BEGIN {printf \"%.2f\", $ORG_SUM/1048576}")
FIN_MB=$(awk "BEGIN {printf \"%.2f\", $FIN_SUM/1048576}")
if [ "$ORG_SUM" -gt 0 ]; then
SAVINGS_PCT=$(awk "BEGIN {printf \"%.2f\", (($ORG_SUM - $FIN_SUM) / $ORG_SUM) * 100}")
SAVED_MB=$(awk "BEGIN {printf \"%.2f\", ($ORG_SUM - $FIN_SUM) / 1048576}")
else
SAVINGS_PCT="0.00"
SAVED_MB="0.00"
fi
START_TIME_STR=$(date -d "@$SCRIPT_START" "+%H:%M:%S Uhr, %d.%m.%y")
END_TIME_STR=$(date -d "@$SCRIPT_END" "+%H:%M:%S Uhr, %d.%m.%y")
SAFE_DUR=$TOTAL_DURATION
[ "$SAFE_DUR" -eq 0 ] && SAFE_DUR=1
RATE_KB_MIN=$(awk "BEGIN {printf \"%.2f\", ($ORG_SUM / 1024) / ($SAFE_DUR / 60)}")
RATE_MB_MIN=$(awk "BEGIN {printf \"%.2f\", ($ORG_SUM / 1048576) / ($SAFE_DUR / 60)}")
RATE_MB_H=$(awk "BEGIN {printf \"%.2f\", ($ORG_SUM / 1048576) / ($SAFE_DUR / 3600)}")
# Der Ausgabe-Block wird sowohl auf dem Bildschirm angezeigt als auch in die Logdatei angehangen
{
echo -e "\n\033[32m=== Alle Bilder erfolgreich verarbeitet! ===\033[0m\n"
echo -e "---------- ABSCHLUSS-REPORT ----------"
echo -e "Startzeit : ${START_TIME_STR}"
echo -e "Endzeit : ${END_TIME_STR}"
echo -e "Gesamtdauer : \033[36m${FORMATTED_TOTAL}\033[0m"
echo -e "Verarbeitungsrate : ${RATE_KB_MIN} KB/min | ${RATE_MB_MIN} MB/min | ${RATE_MB_H} MB/h"
echo -e "Bilder gesamt : ${TOTAL} (Erzeugt: ${CREATED_SUM} | Verworfen: ${DISCARDED_SUM} | Uebersprungen: ${SKIPPED_SUM})"
echo -e "Original (vorher) : ${ORG_SUM} Bytes (${ORG_MB} MB)"
echo -e "Komprimiert (nachher): ${FIN_SUM} Bytes (${FIN_MB} MB)"
echo -e "Ersparnis : \033[32m${SAVINGS_PCT} % (${SAVED_MB} MB)\033[0m"
echo -e "--------------------------------------\n"
} | tee -a "$LOG_FILE"
52. PNG-Dateien mit OptiPNG optimieren:
Dieses Bash-Skript optimiert automatisch alle PNG-Grafiken in einem Verzeichnis und dessen Unterverzeichnissen.
Dabei nutzt es das Tool optipng mit maximaler Komprimierung (-o7) und entfernt alle unnötigen Metadaten (-strip all), um die Dateigröße ohne Qualitätsverlust zu minimieren.
Maximale Brute-Force-Optimierung:
Durch die Parameter -o7 und -zm1-9 wird optipng angewiesen, eine Brute-Force-Suche durchzuführen.
Das Tool probiert systematisch (bruteforce) alle verschiedenen internen Kompressions-Level, Speicherstufen (Memory Levels) und Strategien nacheinander durch, um die absolut kleinste Dateigröße für jedes Bild zu ermitteln.
Obwohl andere Packer wie zopflipng oder advpng oft noch höhere Kompressionsraten erzielen,
kann eine Komprimierung mit optipng sinnvoll sein, da ein Durchlauf oft deutlich schneller ist.
Intelligentes Multithreading:
Das Skript arbeitet extrem effizient, indem es die CPU-Kerne deines Systems abfragt und die Arbeit parallel aufteilt (xargs -P).
Damit der Server oder PC währenddessen ansprechbar bleibt, lässt es ab 4 Kernen automatisch 1 Kern als Systemreserve frei (ab 9 Kernen werden 2 Kerne freigehalten).
Der Parameter ${1:-.}:
Diese Schreibweise definiert den Startpunkt für die Suche. Sie bedeutet: Nimm das erste Argument ($1), das dem Skript beim Aufruf übergeben wird.
Falls kein Argument angegeben wurde (oder der Wert leer ist), verwende stattdessen standardmäßig den Punkt (.), welcher für das aktuelle Verzeichnis steht.
#!/usr/bin/env bash
set -o nounset
set -o pipefail
BASE_DIR="${1:-.}"
# CPU-Cores abfragen und Jobs festlegen:
TOTAL_CORES=$(nproc); JOBS=$TOTAL_CORES; ((TOTAL_CORES>3)) && JOBS=$((TOTAL_CORES>8 ? TOTAL_CORES-2 : TOTAL_CORES-1))
# Wenn nur 1 oder 2 Cores vorhanden: dann alle nutzen.
# ab 4 Cores eine Reserve fürs System (1 Kern bis 8 Kerne, sonst 2 Kerne) nicht nutzen.
echo "Gesamt-CPU-Kerne: $TOTAL_CORES"
echo "Verwende $JOBS Kern(e) für optipng."
echo "Basisverzeichnis: $BASE_DIR"
find "$BASE_DIR" -type f -iname '*.png' -print0 | \
xargs -0 -n1 -P "$JOBS" -I{} sh -c '
file="$1"
echo "Optimiere: $file"
optipng -o7 -zm1-9 -strip all "$file"
' _ {}
Optimierung im aktuellen Verzeichnis starten (Nutzt den Standardwert '.'):
./_optiPNG_core.sh
Gezielte Optimierung eines bestimmten Ordners (z. B. der Bilder-Ordner einer Webseite):
./_optiPNG_core.sh /var/www/html/assets/images
Kurzreferenz: Wichtige Linux Shell-Befehle und Programme von A-Z:
Hinweise vorab:
Linux unterscheidet bei Befehlen und Parametern die Groß- und Kleinschreibung.
Eine ausführliche Hilfe zu jedem Befehl erhält man durch den Aufruf:
man Befehl
addgroup:
Mit Hilfe von addgroup kann man neue Gruppen erstellen und Benutzer einer Gruppe hinzufügen.
addgroup neuer_Gruppenamen = Erzeugt eine neue Gruppe.
addgroup Benutzername Gruppenname = Fügt den bestehenden Benutzer der Gruppe als neues Mitglied hinzu.
adduser:
Mit Hilfe von adduser kann man neue User hinzufügen:
adduser neuer_Username = erstellt einen neuen Benutzer - dieser wird seiner eigenen Gruppe hinzugefügt.
adduser neuer_Username root = erstellt einen neuen Benutzer und fügt diesen der Gruppe root hinzu.
alias:
Hiermit kann man sich für häufig verwendete Befehle einen eigenen kürzeren 'alias' definieren.
Aliase sind flüchtig, werden also nach dem Verlassen der Shell automatisch gelöscht.
Möchte man diese dauerhaft festlegen, so speichert man diese einfach in der Datei [~/.bash_aliases] oder [~/.bash_profile] (empfohlen) oder [~/.bashrc] ab.
nano ~/.bash_profile = Einen Alias in der Autostartdatei vom User definieren (die ~ steht für das Home-Verzeichnis vom User). Ein hier hinterlegter Alias wird bei einem Neustart automatisch übernommen (es sind hier beliebige Shell-Befehle möglich).
source ~/.bash_profile = Die geänderte Konfigurationsdatei direkt neu einlesen, geänderte Aliase sind dann sofort wirksam.
alias = Alle definierten Aliase anzeigen.
alias ll='ls -laF' = Einen neuen Alias definieren. Hier z. B. 'll' für ein ausführliches 'ls'.
alias cls='clear' = Abkürzung zum Bildschirm löschen wie bei Microsoft.
\Befehl = Ein ggf. vorhandener Alias wird ignoriert und es wird der ursprüngliche Befehl direkt aufgerufen.
source ~/.bash_profile = Aliase sofort aktivieren (ohne Neustart).
source ~/.bash_aliases = Aliase sofort aktivieren (ohne Neustart).
unalias ll = Den selbstdefinierten Alias 'll' wieder löschen.
unalias -a = Alle definierten Aliase löschen.
Hinweis: Beachtet beim Löschen von Aliasen, dauerhaft (gespeicherte) Aliase stehen nach einem Systemneustart wieder zur Verfügung, sofern man diese nicht entsprechend aus den Dateien entfernt.
blkid (block device attributes):
Mit Hilfe von blkid kann man z. B. herausfinden welches Dateisystem (ext3, ext4, ntfs, ...) verwendet wird.
blkid versucht immer die aktuellen Daten abzufragen, die so ermittelten Daten werden in einem Cache abgespeichert.
blkid benötigt root-Rechte um aktuelle Daten anzuzeigen, ohne root-Reche erhält man nur alte Daten aus dem Cache sofern diese vorliegen.
blkid = Anzeige von verschiedenen Dateisystemattributen (wie z. B. UUID, Dateisystemtyp, Festplattenlabel).
blkid -g = (garbage) Einen vorhandenen UUID-Informations-Cache löschen (dies ist bei Laufwerkswechsel empfohlen).
blkid -c /dev/null = Aktuelle Zuordnung der Laufwerke & UUIDs (universally unique identifier) anzeigen, ein ggf. vorhandener Cache wird ignoriert.
blkid -o list = Anzeige der Attribute in Listenform.
cat (concatenate):
Mit dem Befehl kann man Dateien, u. ä. anzeigen und Inhalte umleiten und verketten:
cat Datei1 = Den Inhalt der Datei1 in der Standardausgabe ausgeben, d.h. in der Regel auf dem Bildschirm anzeigen.
cat Datei1 > Datei2 = Kopiert den Inhalt der Datei1 in die Datei2, die Datei2 wird ggf. erstellt falls sie nicht vorhanden war.
cat Datei1 >> Datei2 = Der Inhalt der Datei1 wird an die Datei2 angehängt, die Datei2 wird ggf. erstellt falls sie nicht vorhanden war.
weitere Beispiele (Systeminfos ausgeben):
cat /proc/meminfo = Speicherverbrauch anzeigen.
cat /proc/version = Die installierte Kernelversion anzeigen.
cat /proc/cpuinfo = Zeigt Informationen zum verwendeten Prozessor an.
cat /etc/os-release = Zeigt sehr ausführlich an welche Ubuntu/Debian Version installiert ist.
cat /sys/class/net/enp0s3/address = Ausgabe der MAC-Adresse der angegebenen Netzwerkverbindung.
cat /etc/issue = Zeigt an welche Linux Version installiert ist.
cat /etc/lsb-release = Zeigt unter Ubuntu genaue Versionsdaten an.
cat /etc/debian-version = Zeigt Release Nummer der installierten Debian Version an.
cat /dev/zero >Muelldatei = füllt den ganzen freien Plattenspeicher mit Nullen auf (für sicheres löschen).
cat /dev/urandom >Muelldatei = füllt den ganzen freien Plattenspeicher mit zufälligen Zeichen auf (sicheres löschen bei Flash-Medien wie z. B. SSD's).
cat /dev/urandom >/dev/sdb = Beschreibt ein komplettes Laufwerk (hier /dev/sdb) mit zufälligen Zeichen (sicheres löschen von Festplatten).
cd (change directory):
Dieser Befehl ermöglicht den Wechsel in über- und untergeordnete Verzeichnisse/Ordner.
cd XYZ = Wechselt in das übergeordnete Verzeichnis XYZ.
cd .. = Wechselt in das untergeordnete Verzeichnis.
cd / = Wechselt direkt in das root Verzeichnis.
cd ~ = Wechselt direkt ins eigene Home-Verzeichnis ('~/' ist der Pfad zum Homeverzeichnis).
cd = Ohne einen Parameter wechselt direkt ins eigene Home-Verzeichnis.
chattr (change file attributes):
Mit chattr kann man erweiterte Datei-Attribute für Dateien unter einem Linux-Dateisystem ändern.
Mit dem [+] Pluszeichen werden Attribute hinzugefügt.
Mit dem [-] Zeichen werden Attribute entfernt.
[-R] = (recursively), Alle Änderungen auch rekursiv durchführen.
[-V] = (verbose), Zeigt die Programmversion und die durchgeführten Änderungen direkt mit an (wird empfohlen zur besseren Kontrolle).
[-f] = (failure), die meisten Fehlermeldungen unterdrücken.
[-v Versionsnummer] = Die Version/Generation einer Datei festlegen.
[-p Projektnummer] = Die Projektnummer einer Datei festlegen.
Beispiele:
chattr -V +m Datei.txt = Die angegebene Datei wird nicht vom Dateisystem komprimiert.
chattr -V -m Datei.txt = Die angegebene Datei wird vom Dateisystem komprimiert.
chattr -V +i Datei.txt = Die angegebene Datei wird geschützt. Man kann die Datei nicht löschen, verändern oder umbenennen. Wichtig: Dies betrifft auch den Superuser root!
chattr -V -i Datei.txt = Die angegebene Datei wird nicht mehr geschützt. Man kann die Datei wie gewohnt löschen, verändern oder umbenennen.
Die folgenden Attribute sind möglich:
[a] = (append only), Dateien kann man nur im append-Modus zum Schreiben öffnen. Man kann Inhalt an eine bestehende Datei nur anhängen. Bestehenden Inhalt kann man nicht löschen oder überschreiben. Das Attribut kann nur der Superuser (root) oder ein Prozess mit den Rechten 'CAP_LINUX_IMMUTABLE' setzen oder löschen.
[A] = (no atime updates), das Datum des letzten Zugriffs wird nicht gespeichert. Dies kann Schreibzugriffe verringern. Dadurch kann sich ggf. die Systemleistung verbessern.
[c] = (compressed), Dateien werden automatisch vom Kernel beim Schreiben komprimiert und beim Lesen dekomprimiert. Aktuell wird dieses Attribut noch nicht vom ext2, ext3, ext4 Dateisystem unterstützt. Auch das aktuelle Ubuntu 20.04 unterstütz dies nicht (Stand: 31.03.2020).
[C] = (no copy on write), mit diesem Attribut kann man Copy-on-Write beeinflussen. Unter dem Btrfs Dateisystem sollte man dies nur für neue bzw. leere (0 Byte große) Dateien setzen.
Das Attribut lässt sich nur auf Dateisystemen nutzen die Snapshots (COW) unterstützen, also z. B. auf dem Btrfs oder ext3/ext4 Dateisystem. Bei ext-Dateisystemen jedoch nur bei der Verwendung eines LVM-Volume.
Verwendet man das Attribut auf ein Verzeichnis, so beeinflusst dies das Verzeichnis nicht. Allerdings erhalten alle Dateien die in dem Verzeichnis angelegt werden automatisch das Attribut 'No_COW'.
[d] = (no dump), eine Datei mit einem gesetzten Attribut wird nicht vom Programm 'dump' mit gesichert.
[D] = (synchronius directory updates), wenn ein Ordner dieses Attribut besitzt dann, werden Veränderungen direkt synchron auf die Festplatte geschrieben (ähnlich wie beim Parameter 'dirsync' beim 'mount' Befehl). Dieses Attribut ist erst ab der Kernel-Version 2.5.19 möglich.
[e] = (extent format), das Attribut zeigt an ob extents verwendet werden. Die Option 'extents' ermöglicht es dem Dateisystem, 'extents' anstelle von Bitmap-Mapping 'uninit_bg' für Dateien zu verwenden. Dies reduziert unter anderem die Zeiten für die Überprüfung des Dateisystems, indem man nur die benutzten Teile der Platte überprüft muss. Das Attribut wird ab dem ext4-Dateisystem standardmäßig gesetzt. Das Attribut sollte man meiner Meinung nach nicht verändern.
[F] = (case-insensitive directory lookups), auf ein Verzeichnis mit einem gesetzten Attribut wird ohne Berücksichtigung der Groß- und Kleinschreibung zugegriffen. Dies ist ab dem Kernel 5.2/Ubuntu 20.04 möglich, das Feature muss man jedoch zuvor für das Dateisystem erst aktivieren.
Beispielsweise durch formatieren des Dateisystems: 'mkfs.ext4 -O casefold /dev/sdX'
[i] = (immutable), Dateien mit diesem Attribut kann man nicht löschen, verändern oder umbenennen. Auch die meisten weiteren Metdaten kann man nicht ändern. Auch der Superuser (root) kann Dateien nicht löschen oder verändern, zum mindestens so lange das Attribut gesetzt ist.
Wichtig: Auf Dateien mit dem Attribut kann man keine Hardlinks erstellen, Softlinks sind jedoch möglich.
Das Attribut kann nur der Superuser (root) oder ein Prozess mit den Rechten 'CAP_LINUX_IMMUTABLE' setzen oder löschen.
Versucht man nun dennoch eine geschützte Datei zu löschen, zu verändern oder umzubenennen, dann kommt in der Regel der Fehler: [cannot remove/move|Error writing ... Operation not permitted] bzw. der Hinweis: [File ... is unwriteable].
[j] = (data journaling), Bei einer Datei mit dem j Attribut werden alle Daten in das ext3 oder ext4 Journal geschrieben, bevor sie in die Datei selbst geschrieben werden, wenn das Dateisystem mit der Option "data=ordered" oder "data=writeback" gemountet wird und das Dateisystem über ein Journal verfügt. Wenn das Dateisystem mit der Option "data=journal" gemountet wird, sind alle Dateidaten bereits im Journal gespeichert und dieses Attribut hat keine Auswirkung. Nur der Superuser (root) oder ein Prozess, der die 'CAP_SYS_RESOURCE' Fähigkeit besitzt, kann dieses Attribut setzen oder löschen.
[m] = Bei Dateien mit dem gesetzten Attribut m wird die Komprimierung auf Dateisystemebene nicht ausgeführt, wenn das Dateisystem eine Dateikomprimierung unterstützt. Diese Dateien landen dann unkomprimiert auf dem Dateisystem.
[P] = (project hierarchy), Ein Verzeichnis mit gesetztem p Attribut erzwingt eine hierarchische Struktur für Projekt-IDs. Das bedeutet, dass Dateien und Verzeichnisse, die in dem Verzeichnis erstellt werden, die Projekt-ID des Verzeichnisses erben. Umbenennungsvorgänge werden eingeschränkt, so dass die Projekt-IDs übereinstimmen müssen, wenn eine Datei oder ein Verzeichnis in ein anderes Verzeichnis verschoben wird. Außerdem kann ein Hardlink zu einer Datei nur erstellt werden, wenn die Projekt-ID der Datei und des Zielverzeichnisses übereinstimmen.
[s] = (secure deletion), Wenn man eine Datei mit dem Attribut s löscht, dann werden alle betroffenen Dateiblöcke im Dateisystem mit Nullen überschrieben (sicheres löschen).
Das Attribut s wird von den Dateisystemen ext2, ext3, ext4 in aktuell genutzten Mainline-Linux-Kerneln meist nicht implementiert (also nicht unterstützt).
Das Setzen der a und i Attribute hat keinen Einfluss auf die Fähigkeit, in bereits vorhandene Dateideskriptoren zu schreiben.
[S] = (synchronius updates), Wenn eine Datei mit dem Attribut S geändert wird, werden die Änderungen synchron auf die Festplatte geschrieben. Dies entspricht der sync mount Option.
[t] = (no tail-merging), Eine Datei mit dem gesetzten Attribut t wird den letzten Block der betroffenen Datei nicht mit einer anderen Datei teilen (tail-merging).
Dies wird z. B. für Anwendungen wie LILO verwendet, die tail-merging nicht unterstützen.
Aktuell unterstützen die Dateisysteme ext2, ext3 und ext4 kein tail-merging.
[T] = (top of directory hierarchy), Ein Verzeichnis mit dem T Attribut wird vom Orlov block allocator als oberste Verzeichnishierarchie angesehen.
Das ist ein Hinweis für den von ext3 und ext4 verwendeten block allocator, dass die Unterverzeichnisse unter diesem Verzeichnis nicht verwandt sind und daher für Zuordnungszwecke auseinander gezogen werden sollten.
Es ist z. B. eine gute Idee, das Attribut T auf das Verzeichnis /home zu setzen, sodass verschiedenste Userprofile in getrennten Blockgruppen platziert werden.
Hierdurch können ggf. Zugriffe auf Verzeichnisse beschleunigt werden (durch intelligentere Gruppierung/Zusammenfassung im Block/Dateisystem).
Für Verzeichnisse, in denen dieses Attribut nicht gesetzt ist, versucht der Orlov block allocator, Unterverzeichnisse nach Möglichkeit enger zusammenzufassen.
[u] = (undeletable), Löscht man eine Datei mit gesetztem Attribut u so wird der Inhalt gesichert (nicht endgültig gelöscht). Die Löschung kann rückgängig gemacht werden (die Originaldatei kann widerhergestellt werden).
Das Attribut u wird von den Dateisystemen ext2, ext3, ext4 in aktuell genutzten Mainline-Linux-Kerneln meist nicht implementiert (also nicht unterstützt).
Das Setzen der a und i Attribute hat keinen Einfluss auf die Fähigkeit, in bereits vorhandene Dateideskriptoren zu schreiben.
[x] = (existing), Das Attribut x kann man für Verzeichnisse und Dateien setzen.
Wird das Attribut x auf ein bestehendes Verzeichnis gesetzt, so erben alle zukünftig neu erstellte Dateien und Unterverzeichnisse die hier definierten Attribute.
Wenn ein bestehendes Verzeichnis bereits einige Dateien und Unterverzeichnisse enthält, ändert eine Änderung des übergeordneten Verzeichnisses nicht die Attribute dieser Dateien und Unterverzeichnisse.
Die folgenden Attribute werden ggf. von lsattr ausgegeben, diese kann chattr nicht setzen, ändern oder löschen:
[E] = (encrypted), Eine Datei, ein Verzeichnis oder ein Symlink mit dem Attribut E wird vom Dateisystem verschlüsselt.
[I] = (indexed directory), Dieses Attribut kann man nicht selbst setzen. Es gibt an, ob ein Ordner über gehashte trees (Bäume) indexiert wird.
[N] = (inline data), Eine Datei mit gesetztem N Attribut zeigt an, dass die Daten einer Datei inline, innerhalb des Inodes selbst, gespeichert sind.
[V] = (verify), Bei einer Datei mit gesetztem v Attribut ist fs-verify aktiviert. Es kann nicht darauf geschrieben werden, und das Dateisystem verifiziert automatisch alle daraus gelesenen Daten gegen einen kryptografischen Hash, der den gesamten Dateiinhalt abdeckt, z. B. über einen Hash-Baum (merkle tree). Dies macht es möglich, die Datei effizient zu authentifizieren.
Beachtet weiterhin:
Die Unterstützung der Attribute ist vom entsprechenden Dateisystem abhängig. Es sind also nicht immer alle Attribute möglich.
Schaut für weitere Informationen bitte in die jeweiligen Dateisystem Manpages:
man btrfs
man extr4
man xfs
chmod (change file mode bits):
Mit chmod ändert man Zugriffsrechte von Dateien und Verzeichnissen (nur auf Unix-Dateisystemen möglich).
chmod 777 Datei = Vollzugriff für alle also für [den Besitzer], für [Gruppen], sowie [alle
anderen User] (Verzeichnisse werden analog behandelt).
chmod -R 644 /home/Projekt = Setzt die folgenden Berechtigungen rekursiv - also auch für alle Dateien und Verzeichnisse im
angegebenen Unterordner - der Eigentümer darf [lesen & schreiben], alle anderen dürfen [nur lesen].
chmod +x Datei = Macht die Datei ausführbar (wird z. B. benötigt wenn man ein Shell-Script ausführbar zu machen möchte).
Die Berechtigungen werden unter anderem so dargestellt:
[-r--r--r--] = steht am Anfang nur ein [-] so kennzeichnet dies eine Datei.
[dr--r--r--] = (directory) ein kleines [d] an erster Stelle kennzeichnet ein Directory.
[lr--r--r--] = (directory) ein kleines [l] an erster Stelle kennzeichnet einen symbolischen Link (siehe Befehl ln).
Im anschließenden Block werden zuerst: Eigentümerrechte des Besitzers (user), dann die Gruppenberechtigungen (group)
und zuletzt die Berechtigungen für alle anderen (world) vergeben.
[-rwxrw-r--] = User
darf alles (4+2+1=7), Gruppe nur lesen & schreiben (4+2=6), alle anderen dürfen nur lesen (4).
chmod Berechnungen (die Werte jeweils addieren):
4 = lesen.
2 = schreiben
1 = ausführen.
chown (change owner):
Mit chown kann man [den Eigentümer also den Besitzer] sowie [den Eigentümer einer Gruppe] von Dateien und Verzeichnissen festlegen.
Die Berechtigungen kann man nur auf UNIX-Dateisystemen vergeben.
chown User1 Datei = Der User1 wird Besitzer der Datei
(Verzeichnisse werden analog behandelt). Der User1 kann danach auf die Datei zugreifen (chmod beachten).
chown :Gruppe1 Datei = Ändert die Gruppenberechtigungen für die Datei,
es können danach alle User die Mitglieder der Gruppe1 sind auf die Datei zugreifen (chmod beachten) (Verzeichnisse werden analog behandelt).
chown -R User1:Gruppe1 /home/User1/Projekt = Ändert die Besitzrechte wie folgt:
Besitzer aller Daten im angegeben Verzeichnis ist danach User1.
Die Gruppenberechtigung erhalten alle User die zu der Gruppe1 gehören.
Die Berechtigungen werden dabei rekursiv über alle Dateien und alle Verzeichnisse ab dem angegebenen Pfad [/home/User1/Projekt] vergeben.
chpasswd (change password):
chpasswd verwendet man um Passwörter automatisiert mit einem Shell/Batch-Script zu ändern.
Das Passwort muss man im Klartext übergeben, ein ggf. vorhandenes Passwortalter wird aktualisiert.
Die Passworte werden Standardmäßig mit PAM selbständig verschlüsselt im System abgelegt. In der manpage wird empfohlen die Verschlüsselungsvariante nicht zu verändern.
chpasswd verwendet man in der Regel in größeren/automatisierten Systemumgebungen. Die Änderungen sind immer sofort wirksam. Ein bereits angemeldeter User wird nicht automatisch abgemeldet/getrennt.
Für einzelne Passwortänderungen kann man auch passwd verwenden.
Das Passwort eines einzelnen Users ändern:
echo "root:Passwort" | chpasswd = Ändert das Passwort vom User 'root' auf 'Passwort' (empfohlen).
echo "root:Passwort" | chpasswd -s 10000000 -c SHA512 = Ändert das Passwort vom User 'root'. Dabei wird zur Verschlüsselung des Passworts der Verschlüsselungsstandard SHA512 mit 10000000 (10 Millionen) durchläufen verwendet.
Werte von 1000 (5000 = Standard) bis 999.999.999 sind möglich (erhöhte Sicherheit). Bitte beachten, die Anmeldedauer kann sich enorm verlängern.
Passworte für mehrere User ändern:
Zuerst speichert man die User und Passworte wie folgt in einer Datei ab:
root:GehHeim_2020
Mueller:Brotkasten-1982
Meier:Pass W0rt?
Beachtet dabei, Leerzeichen werden mit als Passwort übergeben, egal wo sie stehen auch am Zeilenende.
Die Übergabe an chpasswd erfolgt dann wie folgt:
chpasswd < Passwortdatei.txt
Die Passwortdatei sollte man mit entsprechenden Systemrechten sichern, um unerlaubten Zugang zu verhindern.
Optional: Änderung vom Passwort direkt in der Eingabeaufforderung (nicht empfohlen):
chpasswd
Username:Passwort
Die Änderungen werden durch betätigen der Tastenkombination STRG + d direkt übernommen.
Hinweis: Es erscheint hier keine Aufforderung zum ändern des Passworts. Alle Eingaben muss man direkt hintereinander (ohne Leerzeichen) eingeben.
cp (copy):
Kopiert Dateien und Verzeichnisse.
cp -v ABC.txt XYZ.txt = (verbose) kopiert den Inhalt der Datei ABC.txt in die Datei XYZ.txt und zeigt dies ausführlich an.
cp -u Quelle Ziel = (update) kopiert nur neuere Dateien und noch nicht vorhandene Daten aus der Quelle ins Ziel.
cp -r /Quellverzeichnis/. /Zielverzeichnis/ = (rekursiv) kopiert das Quell-Verzeichnis ins angegebene Ziel-Verzeichnis, dabei werden alle Dateien & Unterordner mit kopiert.
cp -a /Quelle/. /Ziel/ = (archive rekursiv) kopiert das Quell-Verzeichnis ins angegebene Ziel-Verzeichnis, dabei werden alle Dateien & Unterordner mit kopiert. Hierbei werden Zeitstempel, Besitzrechte, Links usw. mit übernommen. Wichtig: Auch den Punkt nach dem shlash so mit angeben (empfohlene Variante).
cut (ausschneiden):
cut extrahiert spaltenweise Ausschnitte aus Textzeilen. Die Ausgabe erfolgt über die Standardausgabe, eine Umleitung ist möglich.
cut -d# -f2 Datei.txt
[-d#] Beschreibt das Trennzeichen hier [#]. Die Zeilen werden am Trennzeichen in Spalten zerlegt.
[-f2] Bestimmt welcher Spaltenteil ausgegeben werden soll hier im Beispiel die [2]. Spalte.
date/hwclock/cal/ntpdate (Zeitangaben ausgeben und setzen):
date = Zeigt den Wochentag, das aktuelle Datum und die Uhrzeit (Systemzeit) an.
date +%Y-%m-%d = Gibt nur das aktuelle Datum aus.
date 042311302015 = Stellt das
Datum und die Uhrzeit (11:30 Uhr, 23.04.2015).
date --set 2019-12-24 = Setz das Datum, hier auf den 24.12.2019.
date --set 12:00:00 = Setzt die Uhrzeit, hier exakt auf 12:00 Uhr.
Wichtig: Wird die geänderte Zeit nicht übernommen, so muss man die Zeitsynchronisation über ntp deaktivieren (siehe timedatectl & VirtualBox).
cal = Gibt eine Kalenderanzeige aus - der aktuelle Tag wird hierbei hervorgehoben.
hwclock = Zum Anzeigen und stellen der Hardware Uhr.
ntpdate de.pool.ntp.org # Benötigt das Paket [ntpdate] - dient zum Stellen der Uhr über einen Zeitserver aus dem Internet.
Formatierungungsmöglichkeiten:
%M Minuten (00 bis 59)
%H Stunden im 24-Stunden-Format
%I Stunden im 12-Stunden-Format
%a Wochentag in Kurzform
%u Wochentag als Ziffer (1 bis 7, 1 = Montag)
%A Wochentag in Langform
%d Tag als zweistellige Ziffer
%e Tag als zweistellige Ziffer mit führendem Leerzeichen bei den Tagen 1-9.
%b Monatsnamen in Kurzform
%B Monatsnamen in Langform
%m Monat als zweistellige Ziffer
%y Jahr als zweistellige Ziffer
%Y Jahr als vierstellige Ziffer
%D Datum Ausgabe (mm/dd/yy)
%F Datum Ausgabe (yyyy-mm-dd) in Ziffern mit Trennstrichen (empfohlene Variante).
%T Zeit im 24-Stunden-Format aus (hh:mm:ss)
%r Zeit im 12-Stunden-Format aus (hh:mm:ss)
%V Kalenderwoche im Jahr als zweistellige Ziffer
%q Quartal im Jahr als Ziffer (1-4)
%t Tabulator
%n Zeilenumbruch
%% %-Zeichen
Beachtet dabei: Ausgaben die Namen enthalten wie z. B. 'Montag', 'Februar' usw. sind abhängig von der im System eingestellten Sprache.
Verwendungsmöglichkeiten:
tar -cvjf backup_$(date +%Y-%m-%d).tar.bz2 *
dd (disk dump):
dd dient zum bit-genauen Kopieren von Datenträgern wie z. B. Festplatten oder Partitionen. Die Datenträger werden dabei Bitweise (Byteweise) 1:1 ausgelesen und beschrieben.
Daher funktioniert dd grundsätzlich mit allen Dateisystemen auf die man zugreifen kann z. B. ext3, ext4, fat32, ntfs, raw usw.
Wichtige Hinweise:
dd wird ohne Rückfragen ausgeführt. Ein falscher Aufruf kann Daten unwiederbringlich löschen.
Um einen Datenträger fehlerfrei zu kopieren, sollte dieser nicht im System (gemountet) eingebunden sein.
Ein CD/DVD-Image erstellen (nur Daten-Medien):
dd if=/dev/cdrom of=/tmp/ImageName.iso bs=32M status=progress = ein CD/DVD-Image erstellen.
'bs=32M' = bestimmt die Blockgröße die gleichzeitig übertragen wird (hier 32 MB).
'status=progess' (optional) zeigt den aktuellen Status beim Kopieren an. Der Status ist nur in neueren Linux Varianten möglich.
Festplatten clonen:
dd if=/dev/sda of=/dev/sdb = kopiert den Inhalt der 1. Festplatte (sda) auf die 2. Festplatte (sdb).
Festplatten sicher löschen:
dd if=/dev/zero of=/dev/sda bs=65535 = Überschreibt die komplette 1. Festplatte mit '0' Nullen mit einem Schreibpuffer von 64 KiB (für SATA Festplatten/SSDs).
dd if=/dev/zero of=/dev/sda1 bs=65535 = Überschreibt die komplette 1. Partition der 1. Festplatte mit '0' Nullen mit einem Schreibpuffer von 64 KiB (für SATA Festplatten/SSDs).
dd if=/dev/zero of=/dev/nvme0n1 bs=128M = Überschreibt die komplette 1. Festplatte am ersten Controller (Controller 0) mit '0' Nullen mit einem Schreibpuffer von 128 MiB (für neue nvme Festplatten/SSDs).
dd if=/dev/zero of=/dev/nvme0n1p1 bs=128M = Überschreibt die komplette 1. Partition der 1. Festplatte am ersten Controller (Controller 0) mit '0' Nullen mit einem Schreibpuffer von 128 MiB (für neue nvme Festplatten/SSDs).
dd if=/dev/urandom of=/dev/sda bs=32M = Überschreibt die 1. Festplatte mit zufälligen Zahlen mit einem Schreibpuffer von 32 MiB (zum sicheren löschen von SSD's, alternative siehe Befehl cat).
Erklärung: urandom liefert Pseudozufallszahlen, random liefert echte Zufallszahlen, urandom ist schneller und für den Zweck ausreichend.
Linux sichern (Komplettsicherung):
swapoff -a = (swapping deaktivieren) es kann sonst passieren das, das Live-System die swap-Partition verwendet und so ein Sichern/Rücksichern verhindert.
dd if=/dev/sdb1 of=/temp/sdb1.img = Sichert die 1. Partition der 2. Festplatte in die Imagedatei sdb1.img im Temp Ordner (weniger empfohlen).
Die so erzeugte Image-Datei kann über mount eingebunden & durchsucht werden (siehe mount unten).
Hinweis: Die Sicherung wird 1:1 so groß wie die zu sichernde Festplatte.
Komprimierte Sicherung & Rücksicherung (empfohlen).
Hinweis: Beachten sollte man das gzip bzw. gunzip Berechtigungen auf die Sicherungspfade benötigt.
Hat man z. B. eine Netzwerk-Freigabe nur für den User root ermöglicht, so muss die Ausführung als root-User erfolgen.
Man sollte hier also kein sudo verwenden.
sudo passwd root = Das root-User-Passwort setzen (optional).
su = zum root-User wechseln.
Die 1. Partition der 1. Festplatte sichern und wiederherstellen:
Das Sicherungsimage kann man erst nach einem Entpackvorgang mounten & durchsuchen (falls man einzelne Dateien aus der Sicherung benötigt).
dd if=/dev/sda1 | gzip -9 > /Pfad/Sicherung_sda1.img.gz = Datensicherung der 1. Partition der 1. Festplatte.
gunzip -c /Pfad/Sicherung_sda1.img.gz | sudo dd of=/dev/sda1 = Rücksicherung der Sicherung auf die 1. Partition der 1. Festplatte.
Die komplette 1. Festplatte sichern und wiederherstellen:
Das Sicherungsimage kann man erst nach einem Entpackvorgang mounten & durchsuchen.
Um die Partitionen einzeln zu Mounten ist es notwendig ein Offset mit zu übergeben (falls man einzelne Dateien aus der Sicherung benötigt).
dd if=/dev/sda | gzip -9 > /Pfad/Sicherung_sda1.img.gz
= Datensicherung der ganzen ersten Festplatte.
gunzip -c /Pfad/Sicherung_sda1.img.gz | sudo dd of=/dev/sda = Rücksicherung der Sicherung auf die erste Festplatte.
Linux Live-DVD-Image auf USB-Stick kopieren (nur Hybrid-ISOs):
umount /dev/sdx = zuerst den UBS-Stick aushängen.
dd if=hybrid_iso_image.iso of=/dev/sdx bs=1M && sync = danach kann man das Kopieren wie folgt starten.
debconf-show:
Mittels debconf-show kann man von installierten Paketen (Programmen) die entsprechend aktuell gesetzten Einstellungen (aus der debconf Datenbank) ausgeben.
Aktuell gesetzte Einstellungen werden dabei meist mit einem Malzeichen (*) markiert.
Der Aufruf erfolgt hier in der Regel wie folgt:
debconf-show Paketname
debconf-show tzdata = Zeigt hier z. B. die aktuell eingestellte Zeitzone an.
Beachtet dabei, nicht jedes Paket enthält hier zwingend gesetzte Einstellungen.
Wenn bei dem Aufruf keine Ausgabe erfolgt, dann sind in der debconf Datenbank keine Einstellungen zu dem Paket gesetzt.
Möchte man Änderungen an den Einstellungen von bereits installierten Paketen vornehmen, dann verwendet man hierzu den Befehl dpkg-reconfigure.
delgroup:
Mit Hilfe von delgroup kann man eine Gruppe löschen und Benutzer aus einer Gruppe entfernen.
delgroup Gruppenname = Entfernt die angegebene Gruppe vom System. Hinweis: Die Primäre Gruppe eines Users kann nicht entfernt werden.
delgroup Benutzername Gruppenname = Entfernt den bestehenden Benutzer aus der angegeben Gruppe (er ist dann kein Mitglied mehr in dieser Gruppe).
deluser:
Einen Benutzer löschen.
deluser Benutzername = Löscht nur den Benutzer. Daten im Homeverzeichnis bleiben erhalten.
deluser --remove-home Benutzername = Löscht den Benutzer einschließlich der Daten im Homeverzeichnis.
df (disk free):
Zeigt dem belegten Speicherplatz von Speicherlaufwerken wie Festplatten, SSD, USB-Sticks usw. an.
df = Zeigt den belegten Speicherplatz in Bytes an.
df -h = (human readable) bedeutet das die Byteangaben in leichter lesbare Angaben wie in Kilobyte, Megabyte und ggf. Gigabyte umgerechnet werden.
diff (difference):
Dieser Befehl ermöglicht den Vergleich zweier Dateien. diff gibt dabei diejenigen Zeilen aus, die in beiden Dateien unterschiedlich sind.
diff Datei1 Datei2
dosfsck:
dosfsck [apt-get install dosfstools] prüft und repariert MS-DOS Dateisysteme. Keine gemounteten Laufwerke prüfen.
dosfsck -ar /dev/sdb1 = prüfen und reparieren mit Rückfragen.
dpkg-reconfigure:
Mittels dpkg-reconfigure kann man bereits installierte Pakete (Programme) neu konfigurieren.
Der Aufruf erfolgt hier in der Regel wie folgt:
dpkg-reconfigure Paketname
Beachtet dabei:
Alle aktuell gesetzten Paketeinstellungen kann man sich vorab mittels debconf-show anzeigen.
Hier ein paar Beispiele:
dpkg-reconfigure tzdata = Neue Standard Zeitzone festlegen.
dpkg-reconfigure locales && reboot = System-Sprache auf Deutsch umstellen.
Hier dann [*] de_DE.UTF-8 UTF-8 und de_DE.UTF-8 auswählen. Bachtet dabei hier ist zur endgültigen Übernahme noch ein Systemneustart notwendig.
apt install language-pack-gnome-de = Diese Sprach-Pakete müssen vorab auf dem System vorhanden sein.
dpkg-reconfigure console-setup = Die Darstellung der Consolen/Terminals (TTY) anpassen. Man kann hier z. B. die Schriftgröße auf 8x14 ändern.
du (disk usage):
Gibt den auf der Festplatte tatsächlich verwendeten Platzverbrauch von Dateien an. Ausgehend von Böcken zu je 512 Byte/Sektor.
Ausgegangen wird immer vom entsprechenden Verzeichnis. Angezeigt werden immer rekursiv alle Verzeichnisse.
du -s = nur die gesamte Summe anzeigen.
du -a = (all) Die Größenangabe für jede Datei einzeln ausgeben.
du -h = (human readable) bedeutet das die Byteangaben in leichter lesbare Angaben wie in Kilobyte, Megabyte und ggf. Gigabyte umgerechnet werden.
e2fsck (ext filesystem check, chkdsk):
e2fsck überprüft die Konsistenz von Linux Dateisystemen (ext2, ext3, ext4) und ggf. auftretende Fehler reparieren.
e2fsck /dev/sda1 = überprüft den Datenträger.
e2fsck /dev/sda1 -n = (no all answer) überprüft den Datenträger (nur lese Modus).
echo:
echo dient zum Ausgeben von Text auf der Standardausgabe. Echo ist Teil der coreutils [1].
echo "Hallo Welt!" = eine einfache Textausgabe. Die Maskierung kann sowohl mit Anführungszeichen, als auch mit Hochkomma geschehen.
echo i = Einfache Ausgabe der Variable i. Beachtet dabei, komplexe Ausgaben wie z. B.
[echo "Variable i enthält: i"] sind damit nicht möglich (daher weniger empfohlen).
echo "${Variable}" = Sichere Ausgabe einer Variable (empfohlen).
echo "Variable i enthält: ${i}" = Ausgabe der Variable i mit Beschreibung.
echo "Variable:" "${x}" = Ausgabe der Variable x mit Beschreibung. Die einzelne Trennung zwischen den Textbestandteilen und der Variable wird von mir empfohlen (weniger Fehler/bessere Übersicht).
echo "$(Befehl)" = Der angegebenen Befehl wird ausgeführt. Ausgaben auf die Standardausgabe werden entsprechend ausgegeben.
Beachtet dabei, eine Ausgabe ist nicht zwingend erforderlich.
Der Befehl [echo -n "$(mkdir Test)"] erzeugt z. B. keine Ausgabe, legt aber das Verzeichnis 'Test' an.
echo "aktuelles Datum: $(date)" = Gibt den Text und das aktuelle Datum mit der Uhrzeit aus.
echo -e "Hallo Welt\n----------" = (enable interpretation of backslash escapes) die Interpretation von Backslash Escape-Sequenzen wird aktiviert. Hier Beispielsweise mit einem Zeilenumbruch (\n = newline).
komplexere Varianten:
echo 'Ausgaben/Text umleiten' >> Datei.txt = Ausgaben lassen sich in Dateien umleiten.
Dabei gilt: '>' die Datei wird immer neu angelegt (eine bestehende wird überschrieben) oder
'>>' die Ausgabe wird an eine bestehende Datei angehängt.
echo 'Hallo Welt' | tee Datei.txt = Ausgaben werden auf der Standardausgabe ausgegeben und zusätzlich in einer Datei gespeichert (siehe tee).
echo -n "Hallo "; echo -n "Du" = (disable newline) gibt am Ende keinen Zeilenumbruch aus.
Hier wird der Text 'Hallo Du' in einer Zeile ausgegeben (z. B. sinnvoll bei Parameter- und Passwortübergaben).
string="Hallo Du"; echo "${string#Hallo }; = das Rautezeichen '#' schneidet von der Variable $string am Anfang den Text 'Hallo ' ab. Es wird hier nur 'Du' ausgegeben (z. B. sinnvoll um Pfade zu kürzen).
string="Datei.png"; echo "${string%.png}"; = das Prozentzeichen '%' schneidet von der Variable $string am Ende den Text '.png' ab. Es wird hier nur 'Datei ausgegeben (z. B. sinnvoll um Dateiendungen zu entfernen).
string='Das ist ein Test.'; echo ${string:12:4} = gibt nach dem 12. Zeichen exakt 4 Zeichen aus. Es wird hier also nur 'Test' ausgegeben.
echo -e "\a"; sleep 0.3; echo -e "\a" = (alert bell) gibt einen Klingelton (bing) aus (Systemabhängig, nicht immer hörbar). Hier 2-mal hintereinander mit kurzer Pause.
echo * = Gibt alle Dateinamen aus dem aktuellen Verzeichnis aus (versteckte Dateien werden nicht angezeigt). Beliebige Joker *, ? und RegEx Ausdrücke [0-9], [a-z], [A-Z] usw. kann man ergänzen.
Script-/Programmlaufzeiten messen:
#!/bin/bash
start=$(date +%s); Startzeit speichern (in Sekunden).
sleep 3; Hier fügt man alle Befehle/Funktionen ein wo man die Laufzeit/Ausführungszeit messen möchte.
echo $(($(date +%s)-${start}))"s"; Ausgabe der Laufzeit in Sekunden, oder
echo $(date -d@$(($(date +%s)-${start})) -u +%Hh:%Mm:%Ss); Ausgabe der Laufzeit in Stunden, Minuten und Sekunden.
Textausgaben mit Farben und Formatierungen hervorheben:
Allgemeine Codes:
\033[0m = Alle Formatierungen zurücksetzen.
\033[1m = Fettschrift.
\033[4m = Unterstreichen.
\033[5m = Blinken.
\033[7m = Inverse Darstellung.
normale & helle Schriftfarben
\033[30m | \033[90m = schwarz | hellgrau
\033[31m | \033[91m = rot | hellrot
\033[32m | \033[92m = grün | hellgrün
\033[33m | \033[93m = gelb | hellgelb
\033[34m | \033[94m = blau | hellblau
\033[35m | \033[95m = magenta | pink
\033[36m | \033[96m = türkis | helltürkis
\033[37m | \033[97m = weiß | weiß
normale & helle Hintergrundfarben
\033[40m | \033[100m = schwarz | hellgrau
\033[41m | \033[101m = rot | hellrot
\033[42m | \033[102m = grün | hellgrün
\033[43m | \033[103m = gelb | hellgelb
\033[44m | \033[104m = blau | hellblau/lila
\033[45m | \033[105m = magenta | pink
\033[46m | \033[106m = türkis | helltürkis
\033[47m | \033[107m = grau | weiß-grau
mehrere Formatierungen fasst man wie folgt zusammen:
\033[Formatierung1;Formatierung2;...m
Beispiele:
echo -e "Dieser Text ist: \033[95m pink, \033[1m pink+fett, \033[7m pink+fett+invers, \033[0m und wieder normal."
echo -e "\033[31;103m Roter Text auf hellgelben Hintergrund. \033[0m"
echo -e "\033[1;4;34;107m Dieser Text ist fett, unterstrichen, mit blauer Farbe, auf weiß-grauen Hintergrund. \033[0m"
Benötigt man Farben häufiger im Script, dann sollte man diese am besten in Variablen speichern:
#!/bin/bash
reset="\033[0m"; # Formatierungen zurücksetzen.
green="\033[32m"; # Farbdefinition in der Variable speichern.
echo -e "Test: [${green} OK ${reset}]"
Die Ausgabe des Scriptes ist hier Beispielsweise:
Test: [ OK ]
Text kann man auch über 'tput' verändern:
echo -e "$(tput bold) bold_text $(tput rev) reverse_text $(tput smul) underline_text $(tput sgr0) normal_text" = Ausgabe des Textes: hervorgehoben/fett (bold), invertiert (rev), unterstrichen (smul) und als Standardtext (sgr0 = Standard wiederherstellen).
Weitere Varianten findet man hier: ANSI escape sequences
Vorsicht bei codierten und kombinierten Befehlen:
(echo ZGF0ZQo= | base64 -d | sh) = hier ist nur der Befehl 'date' encodiert. Es könnte aber auch leicht ein Schadcode sein.
env (environment):
Dieser Befehl gibt die Umgebungsvariablen aus. Also zum Beispiel die Zeitzone, die gerade aktive Shell, den Loginnamen, Spracheinstellungen oder das verwendete Betriebssystem. Diese Infos benötigt man zum Teil für CGI-Scripte.
env
$? (errorlevel/return code):
Der Errorlevel ist der Rückgabewertes eines Programmes.
Diesen kann man z. B. auswerten, um zu prüfen ob ein Programm ohne Fehler beendet wurde.
echo -e "Errorlevel:" $?
Beispiel im Terminal:
cp # Der Aufruf von cp ohne Parameter verursacht natürlich einen Fehler.
cp: missing file operand ...
echo $? # Gibt dann den ERRORLEVEL aus.
1 # Die 1 ist hier der ERRORLEVEL.
Hier noch ein Beispiel zur Auswertung in Bash Scripten:
Wenn der Errorlevel '$?', '-eq' = equal/gleich '0' ist, dann Ausgabe 'kein Fehler' sonst Ausgabe 'ERROR'.
#!/bin/bash
if [ $? -eq 0 ]
then
echo "kein Fehler"
else
echo "ERROR"
fi
exit & logout:
Der Befehl dient zum Abmelden von Usern und zum Beenden von verschiedensten Diensten.
Die Befehle sind historisch gewachsen und erledigen in der Regel dasselbe.
exit
logout
Meist kann man hier auch die Tastenkombination Strg + D verwenden.
fdisk:
fdisk -l = listet alle Datenträger (wie z. B. Festplatten) und Partitionen auf.
file:
file ermittelt den den Dateityp zu einer Datei (wenn dieser bekannt ist).
Bei Archiven wird ermittelt womit sie gepackt wurden.
Bei ausführbaren .exe Dateien wird angezeigt womit diese ggf. komprimiert bzw. erstellt wurden (z. B. UPX compressed, Nullsoft Installer).
Bei Text-Dateien wird das genaue Format bestimmt (z. B. ASCII, UTF-16 Unicode).
Bei Images wird der exakte Typ, die Auflösung, Farbtiefe usw. ausgegeben.
file erkennt noch mehr Dateitypen und Eigenschaften, die hier vorgestellten sind nur Beispielhaft.
file unbekannte_Datei = Den Dateityp der übergebenen Datei abfragen und ausgeben.
file * = alle Dateien in einem Ordner abfragen.
find:
find sucht standardmäßig rekursiv in einer Verzeichnishierarchie nach Dateien (also auch in allen Unterordnern).
Wichtig: Die Angabe der Anführungszeichen ist notwendig um alle Dateien zu erhalten (Namen mit Leerzeichen und rekursive Einträge werden sonst ggf. nicht mit erfasst).
find / -name "Datei"
= Sucht ab dem Wurzelverzeichnis / alle Dateien mit dem Namen Datei.
find . -name "*.jpg" = Sucht ab dem aktuellen Verzeichnis markiert durch den . alle Bild Dateien mit der Endung Namen *.jpg.
find . -name "*.jpg" -exec file '{}' \;
= Sucht im aktuellen Pfad alle .jpg Bild Dateien. Alle gefundenen Bilder werden hier nacheinander dem Programm file (ersetzbar durch beliebigen Befehl) übergeben.
find /var/ -name "*.log"
= Sucht ab dem angegebenen Pfad nach Logfiles (.log Dateien). Man kann also die gewöhnlichen Joker verwenden.
find $HOME -type d "Verzeichnis"
= Sucht ab dem Home-Verzeichnis des Users nur nach Verzeichnissen mit dem Namen Verzeichnis.
find ~/ -size +20M
= Sucht alle Dateien ab dem Home-Verzeichnis die mindestens 20 MB groß sind.
find /Pfad -type f -empty -print = Sucht alle leeren Dateien (mit der Dateigröße 0) ab dem angegebenen Pfad und gibt diese auf der Standardausgabe aus (file/print).
find /Pfad -type f -empty -delete = Sucht und löscht alle leeren Dateien (mit der Dateigröße 0) ab dem angegebenen Pfad (file/delete).
Alternative Varianten: [find /Pfad -type f -size 0 -delete] oder [find /Pfad -type f -size 0 -print0 | xargs -0r rm].
find /Pfad -type d -empty -print = Sucht alle leeren Verzeichnisse ab dem angegebenen Pfad und gibt diese auf der Standardausgabe aus (directory/print).
find /Pfad -type d -empty -delete = Sucht und löscht alle leeren Verzeichnisse ab dem angegebenen Pfad (directory/delete).
find /Pfad -type f -executable = Gibt alle Dateien aus die Ausführbar sind (Programme & Scripte).
komplexe find Varianten Beispiele:
- Alle Hardlinks anzeigen oder löschen.
- Mehrere .bmp Dateien in .png Dateien konvertieren.
- find /Pfad -type f -name "*.txt" | while read file; do echo "${file}"; done # Leicht lesbare Variante (empfohlen).
- find /Pfad -type f -name "*.txt" -exec sh -c 'file="{}"; echo "${file}"' \; # Mit separater 'sh' Shell, auch 'bash' usw. wäre möglich.
Die Anführungszeichen und Hockommas um die Befehle ('-c' = command) muss man hier entsprechend alle mit übernehmen.
- find -exec echo "{}" \; -exec file "{}" \; # Das zweite -exec Kommando wird nur ausgeführt wenn das erste Erfolgreich war.
- find /Pfad -type f -iname "*.png" -newer /Pfad/last_run -print0 | xargs -0 advpng -4 -z -i 1000 | touch /Pfad/last_run # Optimiert nur neue Bilder.
- find . -type f | wc -l = Alle Dateien rekursiv ab dem angegebenen Ordner zählen.
for do done (for Schleife):
for ermöglicht das Ausführen von Befehlen innerhalb eines Schleifendurchlaufs.
In der Regel wird die Schleife so lange wiederholt bis alle Elemente/Objekte durchlaufen sind.
Mit dem Befehl break beendet man man eine Schleifenausführung.
Mit dem Befehl continue bricht man den aktuellen Durchlauf ab, die Schleifenausführung startet nochmal neu von Anfang an.
for Variable in Parameterliste; do Befehl; done = Beispielhafter Grundaufbau.
for img in *.png; do file "$img"; done
= Alle .png Dateien im aktuellen Ordner suchen und in der Variable img speichern, do file (ein beliebiger Befehl) gibt hier Beispielsweise Details zur den gefundenen Bilddateien aus.
Wichtig: Die Anführungszeichen sind notwendig um Dateinamen mit Leerzeichen mit zu erfassen.
for Schleife mit Variable:
for ((i=0; i<100; i++)); do # Zählt hier 100 Schritte (von 0-99).
echo ${i}; # Ausgabe der Variable $i.
# Beliebige weitere Befehle ...
# if [ ${i} -eq 33 ]; then break; fi # z. B.: Wenn $i den Wert 33 enthält (-eq = equal) die Schleife vorzeitig beenden.
done; # Ende der for Schleife.
free:
free -h = (human readable) Zeigt den Arbeitsspeicher/Ram-Verbrauch in einer leicht lesbaren Variante an.
Komplexe Variante:
free -m -w | sed -n 2p | awk '{print $3}' = gibt nur den freien Speicher in Mebibytes aus. Der Swap und Puffer/Cache Speicher wird dabei nicht berücksichtigt.
-m = (--mebi) die Ausgabe des freien Arbeitsspeichers erfolgt in Mebibytes.
-w = (--wide) die Ausgabe erfolgt im breiten Tabellenformat.
sed -n 2p = liest nur die 2. Zeile ein.
awk '{print $3}' = gibt nur die 3. Spalte mit dem freien Speicher aus.
alternative Speichergrößen:
-b (--bytes) = Bytes
--kilo = Kilobytes
--mega = Megabytes
--giga = Gigabytes
--tera = Terabytes
--peta = Petabytes
-k (--kibi) = Kibibytes
-m (--mebi) = Mebibytes
-g (--gibi) = Gibibytes
--tebi = Tebibytes
--pebi = Pebibytes
fsarchiver kann den Inhalt eines Dateisystems (also alle Programme, Daten, usw...) in einem Archiv sichern.
Ein solches Archiv kann man auch auf kleineren Festplatten und alternativen Dateisystemen wieder herstellen.
fsarchiver kann im Gegensatz zu tar/dar beim Restore auch das Dateisystem auf der Partition erstellen.
In dem Archiv sind alle Daten durch Checksummen geschützt. Sollte ein Archiv beschädigt sein, so gehen nur die Dateien verloren die beschädigt wurden (es geht also nicht das komplette Archiv verloren).
fsarchiver unterstützt derzeit nur Linux Dateisysteme unter anderem ext2, ext3, ext4, xfs, btrfs.
Optional kann man Multivolume-Archive erstellen, diese lassen sich dann einfach auf DVD sichern.
Tipp: Wer häufiger Linux Systeme sichern muss, sollte sich mein Sicherungscript [1] ansehen.
fsarchiver installieren:
apt-get install fsarchiver
Daten sichern:
fsarchiver savefs /mnt/backup/sda1_archiv.fsa /dev/sda1 = ein Dateisystem in ein Archiv sichern.
fsarchiver savefs /mnt/backup/sda-archiv.fsa /dev/sda1 /dev/sda2 = mehrere Dateisysteme in ein Archiv sichern.
fsarchiver savefs -j2 -s 4300 -v -z7 /mnt/backup/sda1_archiv.fsa /dev/sda1 =
Empfehlung ♥ für DVD-Backup (die Parameter sind alles Kleinbuchstaben).
Daten wiederherstellen:
fsarchiver restfs -v /mnt/backup/sda-archiv.fsa id=0,dest=/dev/sda1 =
erstes Dateisystem (id=0) vom Archiv auf /dev/sda1 wieder herstellen.
id = bestimmt die Nummer vom Dateisystem falls man mehrere Dateisysteme in einem Archiv gesichert hat (begonnen wird bei 0).
Daten wiederherstellen und das Dateisystem konvertieren:
fsarchiver restfs -v /mnt/backup/sda-archive.fsa id=0,dest=/dev/sda1,mkfs=ext3 = Das Dateisystem
ins ext3-Format konvertieren und das Archiv wieder herstellen ♥.
Daten temporär entpacken:
fsarchiver restdir /mnt/backup/archive.fsa /tmp/extract = entpackt die Daten ins angegebene Verzeichnis.
Archiv-Infos anzeigen:
fsarchiver archinfo /mnt/backup/archive.fsa = Zeigt verschiedene Infos zum Archiv an, unter anderem: Erstellungsdatum, Dateisystemformat, Label, UUID, Speichergrößen...
Verfügbare Dateisysteme anzeigen:
fsarchiver probe simple = Alle Speichermedien (wie z. B. Festplatten) und die darauf enthaltenen Partitionen anzeigen.
Optionale Parameter:
fsarchiver unterstützt multi-thread-Prozessoren.
-j2 = (jobs count) Anzahl der Threads festlegen (Dual-Core = 2, Quad-Core = 4,...).
Gibt man einen Core weniger an als man zur Verfügung hat, so wird das System nicht zu 100% ausgelastet.
-o = (overwrite) ein bereits bestehendes Archiv wird überschrieben.
-s 4300 = (split) Teilt das Archiv in mehrere Teile (Multivolume-Archive)
beginnend mit .fsa danach fortlaufend .f01, f.02, f03, ... die Größe wird in MB angegeben (4300 MB sind perfekt für DVD-Sicherungen).
Beim Restore eines Multivolume-Archivs werden die fortlaufenden Archive automatisch verwendet, wenn sie im selben Verzeichnis liegen. Sollte dies nicht möglich sein, so wird an der Eingabeaufforderung nach dem Speicherort für das nächste Archiv gefragt.
-c P@s5wörd = (crypt) Verschlüsselt das Archiv mit dem angegebenen Passwort
(verwendet man -c - so wird das Passwort an der Eingabeaufforderung abgefragt).
-v = (verbose) ausführliche Infos ausgeben.
-z7 = Kompression festlegen (1 = schnell bis 9 = sehr gut, Standard = 3).
-e 'temp' = (exclude) Dateien & Verzeichnisse die dem Muster entsprechen auslassen (auch absolute Pfadangaben und Joker sind möglich).
-h = (help) Zeigt eine kurze Hilfe mit Beispielen an.
Alternative Weblinks:
qt4-fsarchiver (deb-Pakete & Live-DVD) = Backup über eine GUI-Oberfläche.
sysresccd.org/SystemRescueCd_Homepage - SystemRescueCD mit verschiedenen Tools unter anderem mit fsarchiver.
fsck (file system check):
fsck prüft und repariert Linux Dateisysteme.
fsck darf man nicht auf gemountete Datenträger anwenden.
fsck /dev/sda1 = Prüft den angegebenen Datenträger.
grep:
grep ist ein Programm, das zur Suche und zur Filterung von definierter Zeichenketten in Dateien dient.
Die so gefilterten Dateien kann man zum einen über die Standardausgabe (auf den Bildschirm) ausgeben,
des Weiteren kann man diese gefilterten Daten in eine neue Dateien umleiten (also speichern als eine neue Datei).
grep -v "^#" Datei.conf > Datei.conf.ohne_Kommentare = Löscht alle Kommentarzeilen in der Ausgabedatei.
grep -vE "(^#|^$)" Datei.conf > Datei.conf.Kompakt = Löscht alle Kommentare & Leerzeilen in der Ausgabedatei.
ifconfig eth0 | grep inet = Filtert in der Ausgabe von ifconfig alle Zeilen die 'inet' enthalten heraus.
groups (Gruppen):
groups Benutzername = Zeigt an in welchen Gruppen der Benutzer Mitglied ist.
htop:
htop ist ein sehr mächtiger und erweiterter Prozessmanager (Taskmanager) der in der Regel nicht automatisch mit installiert wird.
Beachtet bitte folgendes:
In grafischen Umgebungen (mit Desktop) kann htop auch teilweise mit der Maus bedient werden. Kommt diese Erkenntnis unerwartet kann dies ggf. zu unerwünschten Aktionen führen.
htop kann man wie folgt nachinstallieren:
apt install htop
Wichtige Parameter (beachtet die unterschiedlichen Groß- und Kleinbuchstaben!):
Leertaste = Prozesse markieren/demarkieren.
c = (tag process and its children) markiert den Prozess und ggf. alle dazugehörigen Kindprozesse ebenso.
U = (untag all) alle Markierungen rückgänig machen.
F5 / t = (tree) ein-/ausschalten. Mit + und - kann man den Baum auf und zuklappen (Numlock ggf. an-/ausschalten).
l = (list of file) offene Dateien zum Prozess anzeigen (benötigt ggf. das Paket 'lsof': apt install lsof).
F3 = (search) die Eingabe: "search: Prozessname" springt zum Suchbegriff. Wiederholtes F3 springt zu allen Instanzen.
F4 = (filter) die Eingabe: "search: Prozessname" zeigt nur die gefilterten Prozesse an, alle anderen werden ausgeblendet (empfohlen).
F7 = (nice -) die Prozesspriorität senken (gilt für alle markierte Prozesse oder für den aktuell mit dem Balken markierten Prozess).
F8 = (nice +) die Prozesspriorität erhöhen.
F9 / k = (kill) Task beenden, Prozesse auswählen und mit Enter den links ausgewählten kill Befehl bestätigen.
F10 / q = (quit) htop beenden.
I = (invert) die aktuell ausgewählte Anzeige (die aktuell hervorgehobene) invertieren. Sortiert z. B. die verbrauchte CPU-Zeit (TIME) eben auf- oder absteigend.
a = hiermit kann man auf Mehrkernprozessorsystemen den zu verwendenden Core frei/selbst festlegen (manuelle Lastverteilung einzelner Prozesse auf einzelne CPU-Cores).
M = (Memory) sortiert nach dem Speicherverbrauch. Standardmäßig wird absteigend der Anteil des RAM Verbrauches in Prozent '%' angegeben.
P = (Prozessor usage) sortiert absteigend nach der anteiligen CPU-Last.
T = (Time) sortiert absteigend nach der insgesamt verbrauchten CPU-Zeit.
K = (hide kernel) Kernel Prozesse/Threads ausblenden.
H = (hide user) User Prozesse/Threads ausblenden.
p = (full path) zeigt zu Prozessen den kompletten Pfad an.
w = (wrap) zeigt den Pfad zu Prozessen ggf. auch in mehreren Zeilen in einem neuen Fenster an. Dies ist Hilfreich wenn der Pfad in der normalen Übersicht Aufgrund der Länge abgeschnitten wird.
? = (help) zeigt eine Hilfe an.
Hinweis: Diese Befehlsliste ist nicht abschließend, dies sind aber so die gängigsten/wichtigsten Funktionen die man für den Start kennen sollte.
States (s) = Spalte 'S' Erklärungen:
R = running
S = sleep/idle/sleeping
T = traced/stopped or suspended
Z = zombi, der Prozess wartet auf ein exit status eines anderen Prozesses.
D = deep sleep, disk sleep (uninteruptible)
W = paging
gzip:
gzip dient zur Komprimierung und Dekomprimierung von einzelnen Dateien.
Möchte man mehrere Dateien in ein Archiv packen, dann sollte tar oder einen neueren Packer wie Beispielsweise xz verwenden.
gzip verwendet einen open-source Deflate-Algorithmus (basierend auf LZ77 und der Huffman-Kodierung).
Die Kompression ist veraltet, aber sehr schnell und über die zlib nahezu überall verfügbar. Insbesondere in kompakten embeded Systemen kann daher die Nutzung durchaus Sinn machen.
gzip -k9f Datei = die Datei in ein Archiv Datei.gz packen (keep - Originaldatei behalten, 9 - beste Komprimierung, force - eventuell vorhandene Zieldatei überschreiben).
gzip -l = (list) zeigt den Inhalt eines Archives an. Außer dem Namen wird noch die komprimierte und unkomprimierte Dateigröße sowie der Kompressionsfaktor (ratio) ausgegeben.
gzip -tv Datei.gz = (test/verbose) Testet das Archiv. Das Ergebnis wird auf Ausgabe auf der Standardausgabe ausgegeben.
gzip -c = Alle Ausgaben werden auf die Standardausgabe umgeleitet. Sinnvoll wenn man den Datenstrom an weitere Befehle weitergeben will gzip -c Eingabe/Ausgabe/Datei/Archiv | Befehl.
gzip -d Datei.gz = (deflate/decompress) Datei entpacken.
gzip -h = (help) die Hilfe anzeigen.
hdparm:
Mittels hdparm kann man verschiedenste Festplattenparameter abfragen und setzen.
hdparm -W /dev/sdX = gesetzte Parameter nur anzeigen (ohne Wertangabe).
hdparm -W1 /dev/sdX = '1' Festplatten Schreibcache auf dem entsprechenden Laufwerk einschalten (Standard), abschalten mit '0'.
hdparm -a512 /dev/sdX = read-ahead auf 512 vergrößern, dies kann bei großen Dateien die Geschwindigkeit erhöhen (Standard = 256).
hdparm -H /dev/sdX = Laufwerkstemperatur ausgeben, sofern unterstützt.
hdparm -tT /dev/sdX = bufferd und cached Disk Benchmark.
hdparm -Bxxx /dev/sdX = Advanced Power Management anpassen,
sofern das Laufwerk dies unterstützt (0-254, 127 meist Standard, 255 total abschalten, kleinere Werte = bessere Energieersparnis, höhere Werte = höhere Geschwindigkeit).
hdparm -R /dev/sdX = write-read-verify festlegen, die Laufwerksfirmware stellt hiermit durch nochmaliges einlesen der geschriebenen Daten sicher, dass alle Daten korrekt geschrieben wurden.
Nur möglich wenn dies das Laufwerk unterstützt. Ein aktiviertes verify kann die Schreibgeschwindigkeit deutlich verlangsamen ('-R1' einschalten, '-R0' ausschalten).
hdparm -fF /dev/sdX = System Cache (softwareseitig) und Laufwerks Cache (hardwareseitig) leeren. Sinnvoll wenn man sichergehen will das alle Daten zu einem Zeitpunkt korrekt geschrieben werden.
head:
head gibt den ersten Teil (den Kopf/Anfang) einer Datei auf der Standardausgabe aus.
Wird keine Datei oder nur ein Minuszeichen (-) angegeben, dann werden die Daten von der Standardeingabe gelesen.
head Datei1 Datei2 = Von Datei1 und Datei2 werden nur die ersten 10 Zeilen (Standard) angezeigt (mit Header bei mehreren Dateien).
head -n 5 Datei = (number/lines) gibt nur die ersten 5 Zeilen der Datei aus (ohne Header).
head -n -5 Datei = (number/lines mit negativer Zahl), gibt alle Zeilen bis auf die letzten 5 Zeilen aus (ohne Header).
head -c 100 Datei = (count/bytes) gibt nur die ersten 100 Bytes (Zeichen) aus (ohne Header).
head -c -100 Datei = (count/bytes mit negativer Zahl) gibt alle Bytes (Zeichen) bis auf die letzten 100 Bytes (Zeichen) aus (ohne Header).
head - = liest von der Standardeingabe.
head -q Datei1 Datei2 = (quiet) vor der eigentlichen Daten-Ausgabe wird kein zusätzlich Header (kein Dateiname) mit ausgegeben (ohne Header).
head -v Datei = (verbose) vor der eigentlichen Daten-Ausgabe wird zusätzlich der der Dateiname wie folgt formatiert '==> Datei <==' ausgegeben (mit Header).
head -z Datei = (zero-terminated) Zeilentrenner ist nicht der Zeilenumbruch (newline) sondern die Null (NUL/zero). Verwendet man also hauptsächlich beim trennen von Binärdaten.
hostname:
hostname = Gibt nur den aktuellen Hostnamen aus.
hostnamectl:
hostnamectl = Zeigt unter anderem den Hostnamen an, kann eine eventuelle Virtualisierung erkennen, listet das Operating System und den verwendeten Kernel auf uvm.
hostnamectl set-hostname neuer-Hostname = Setzt einen neuen Hostnamen. Achtung der Eintrag zur Rückwärtsauflösung in der '/etc/hosts' Datei bleibt hier unverändert.
Computer Hostnamen (PC Namen) ändern - empfohlene vorgehensweise:
nano /etc/hosts = Man sollte vor dem ändern des Hostnamens die '/etc/hosts' Datei anpassen, damit eine Rückwärtsauflösung gewährleistet bleibt.
nano /etc/hostname = Danach kann man hier den Hostnamen ändern.
Wichtiges um Fehler zu vermeiden:
Die Länge des Hostnamens kann zwischen 2 und 63 Zeichen liegen. Einzelzeichennamen (nur ein Zeichen - wie z. B. nur ein 'A') sind nicht erlaubt.
Um die alte MS DOS/Windowskompatiblität sicherzustellen, sollte man die Hostnamen möglichst auf maximal 15 Zeichen (NETBIOS Abhängigkeit) beschränken.
Maximal 11 Zeichen (8+3) werden von mir empfohlen (ihr könnt hier natürlich abweichen).
Weiterhin darf der Hostname nur aus Buchstaben (A-Z, a-z), Ziffern (0-9) und dem Bindestrich '-' bestehen.
Bachtet hierbei, der Bindestrich darf nicht am Anfang oder Ende stehen. Und es wird nicht zwischen Groß- und Kleinschreibung unterschieden.
Alle anderen Sonderzeichen wie Punkte '.' (diese dienen der Domänenkennung), Unterstriche '_' usw. sind gemäß RFC952 bei einem Hostnamen nicht zulässig (auch wenn man sie hin und wieder sieht).
id (identification):
id = Die Identifikationsnummer (ID) des Benutzers und der Gruppe anzeigen.
id -u = Ausgabe der EUID (effective user id).
id -u -r = Ausgabe der UID (real user id).
Der root User hat immer die UID/EUID mit der Nummer 0.
Benötigt man mehr Infos zu den Usern dann kann man auch folgendes versuchen:
cat /etc/passwd = listet alle angelegten User auf.
cat /etc/group = zeigt alle bereits angelegten Gruppen.
if:
Wichtig: Zwischen den eckigen Klammern [ Bedingung ] muss zwingend ein Leerzeichen stehen.
if [ -f '/Pfad/Datei' ];
then echo 'Datei existiert.';
else echo 'Fehler: Datei nicht gefunden.'; exit 13; fi;
Wenn die Datei (file) existiert, dann Ausgabe des Textes,
wenn die Datei nicht existiert, dann Ausgabe des Fehler Textes und den Aufruf mit dem Fehlercode 13 beenden.
Hinweis: exit, sollte man nur im Script verwenden, da ein Aufruf im Terminal, dieses direkt wieder schließt.
if [ -d '/Verzeichnis' ];
then echo 'Verzeichnis/Pfad/Ordner existiert.'; fi;
Nur wenn das Verzeichnis (directory) existiert, wird der Text ausgegeben.
if [ $EUID -ne 0 ];
then echo 'keine root Rechte'; exit 13;
else echo 'root: OK'; fi;
Prüfen ob root Rechte vorhanden sind. Wenn nein, dann die weitere Ausführung beenden und exit mit Errorlevel 13.
Wichtig: Die Variable $EUID (effective user id) muss man groß schreiben.
if [ -f 'Datei1' ];
then echo 'Datei1 existiert.';
elif [ -f 'Datei2' ];
then echo 'Datei2 existiert.';
else echo 'keine passende Datei gefunden'; fi;
Prüft ob Datei1 oder Datei2 existiert, elif ist also eine 'ODER' Abfrage.
Man kann beliebig viele weitere elif Anweisungen ergänzen.
Wichtig: Es wird nur die erste zutreffende Bedingung abgearbeitet, alle weiteren nachfolgenden Bedingungen werden nicht mehr berücksichtigt.
if [ -f 'Datei1' ] || [ -f 'Datei2' ];
then echo 'Datei1 oder Datei2 existiert.';
else echo 'Fehler: Datei nicht gefunden.'; exit 13; fi;
Prüfen ob Datei1 oder Datei2 existiert.
Mit Negation (wahr ist, wenn die entsprechende Bedingung nicht zutrifft):
if ! [ -d '/Pfad/Backup' ];
then echo 'Backup Ordner existiert nicht. Erstelle neues Verzeichnis'; mkdir /Pfad/Backup;
else echo 'Backup Ordner bereits vorhanden: OK'; fi;
Nur wenn kein Backup Verzeichnis existiert (beachtet das Negations-Ausrufzeichen '!'), wird ein neues Verzeichnis angelegt.
weitere Varianten:
if [ $Variable = 'Vergleichtext' ]; then ...; fi;
= ist wahr, wenn die Variable den gleichen String-Text enthält.
if [ $Variable != 'Vergleichtext' ]; then ...; fi;
= ist wahr, wenn die Variable nicht den gleichen String-Text enthält.
if [[ -f 'Datei1' && -f 'Datei2' ]]; then ...; fi;
= ist wahr, wenn die Datei1 und die Datei2 existiert.
if [ -r "Datei" ]; then ...; fi;
= ist wahr, wenn die Datei existiert und lesbar ist (readable).
if [ -s "Datei" ]; then ...; fi;
= ist wahr, wenn die Datei existiert und diese nicht leer ist (die Datei muss größer 0 sein).
if [ -w "Datei" ]; then ...; fi;
= ist wahr, wenn die Datei existiert und beschreibbar ist (writeable).
weitere Varianten - Dateigrößen vergleichen:
Prüfen ob die Datei1 kleiner oder gleich groß ist wie die Datei2:
if [ $(stat -c%s "$Datei1") -le $(stat -c%s "$Datei2") ]; then ...; fi; = ist wahr, wenn die Datei1 kleiner oder gleich groß (less or equal) als die Datei2 ist.
Prüfen ob die Datei1 kleiner ist als die Datei2:
Zuerst die 2 Dateigrößen ermitteln. Die Variablen $Datei1 und $Datei2 enthalten hier den kompletten Pfad- und Dateinamen.
size1=$(stat -c%s "$Datei1");
size2=$(stat -c%s "$Datei2");
if [ "${size1}" -lt "${size2}" ]; then ...; fi; = ist wahr, wenn die Datei1 kleiner als (less than) die Datei2 ist.
iotop:
iotop zeigt Lesezugriffe- und Schreibzugriffe für das ganze System, zu einzelne Prozessen und Threads an (benötigt root Rechte).
iotop installieren:
apt install iotop
iotop = alles Anzeigen.
iotop -o = (only) nur Prozesse und Threads anzeigen die gerade lesen oder schreiben. Auch jederzeit umschaltbar mit der Taste o.
iotop -a = (accumulated) ab dem Start von iotop werden alle Lese- und Schreibzugriffe angesammelt/aufsummiert. Auch jederzeit umschaltbar mit der Taste a.
ip:
Dient zum Anzeigen und ändern von Netzwerk-, Routing- und Tunneleinstellungen.
ip addr = zeigt IP-Adressen an.
ip -c a = zeigt IP-Adressen farbig hervorgehoben an.
ip route show default = Ermittelt die Standard-Netzwerkverbindung.
ip route show default|awk '/default/ {print $5}' = Ermittelt über den 5-ten String den Namen der Standard-Netzwerkverbindung, also z. B. 'eth0', 'enp0s3' usw.
journalctl:
Mithilfe von journalctl kann man das zentrale Logfile (Journal) welches unter anderem von systemd erzeugt wird gezielt abfragen.
journalctl = zeigt das komplette Logfile/Journal an.
journalctl -b = zeigt alle Logfile/Journal Einträge seit dem letzten Bootvorgang an.
journalctl -e = (page-end) zeigt das komplette Logfile/Journal an und springt bei der Anzeige gleich ans Ende.
journalctl -f = (follow) zeigt das komplette Logfile/Journal an. Das Logfile/Jornal springt dabei ans Ende. Änderungen am Logfile/Journal werden fortlaufend (live) sofort angezeigt. Der Abbruch erflogt über die Tasten Strg + c.
Nur Entsprechende Units (Dienste/Programme abfragen):
journalctl -u Unit-Name* = (unit) zeigt nur Logfile/Journal Einträge der angegebenen Unit an. Joker (*) kann man zur Abkürzung verwenden.
journalctl -fu evcc* = (follow/unit) zeig hier zum Beispiel fortlaufend alle Einträge der Unit evcc (ein Dienst/Programm zum optimierten Überschussladen mit einer Wallbox) an.
Abgekürzt könnte man hier auch z. B. 'journalctl -u evc*' oder 'journalctl -u ev*' oder einfach 'journalctl -u e*' eingeben.
Bei einer zu kurzen Abkürzung können Meldungen von weiteren Units entsprechend mit erscheinen.
journalctl -eu openvpn* = (page-end/unit) zeigt hier zum Beispiel die Einträge von einem OpenVPN Server an. Die Anzeige springt zum Ende diese wird hier aber nicht fortlaufend aktualisiert, da kein follow (-f) angegeben wurde.
journalctl -fu apache = (follow/unit) zeig hier zum Beispiel fortlaufend alle Einträge von einem Apache Webserver.
Kernel Einträge:
journalctl -k = (kernel) zeigt nur Einträge von Kernel-Meldungen an (meist weniger interessant).
Ältere Logfiles analysieren:
journalctl --list-boots = listet alle gespeicherten Logfiles/Journale auf. Standardmäßig wird das Journal unter Ubuntu dauerhaft gespeichert.
Die Boot-Nummer stehen dabei immer am Anfang gefolgt vom Datum. Die aktuellste Bootnummer hat dabei immer die 0 (Null), die vorherigen Absteigend immer -1 usw.
Um ältere Logfiles/Journale anzuzeigen gibt man hier entsprechend die Bootnummer mit an.
Die Bootnummer wird mit jedem Systemstart/Neustart entsprechend negativ hochgezählt.
journalctl -b -10 -eu apache = dies zeigt hier zum Beispiel die Einträge vom Logfile/Journal von einem Apache Webserver vor 10 Systemstarts an.
Error/Fehler anzeigen:
journalctl -p err = zeigt Alle Einträge mit der Kennzeichnung error (err "3"), critical (crit "2"), alert (alert "1") oder emergency (emerg "0") auch für ältere Bootvorgänge (also rückwirkend) an.
Weitere Prioritäten sind: warning "4", notice "5", info "6" und debug "7".
journalctl -p 4 = (priority) alle Einträge bis zu den Warnungen anzeigen. Man kann hier den Namen für die Priorität oder die Nummer hier entsprechend angeben.
journalctl -p err -b = zeigt Alle Einträge mit der Kennzeichnung error, critical, alert oder emergency nur seit dem letzten Bootvorgang an (dabei entspricht '-b' hier mehr oder weniger '-b 0').
journalctl -p err -b -10 = zeigt zum Beispiel alle Einträge mit der Kennzeichnung error, critical, alert oder emergency von einem älteren Bootvorgang vor 10 Systemstarts (anpassbar) an.
Logdaten bereinigen:
Wichtig: Da standardmäßig die Logfiles/Journale bei Ubuntu nicht gelöscht werden können diese das System irgendwann negativ beeinflussen.
Daher sollte man deren Größe im Auge behalten und bei Bedarf alte Logfiles/Journale löschen oder hier eine maximale Größe festlegen.
journalctl --disk-usage = Gibt aus wieviel Speicherplatz das Journal aktuell belegt.
journalctl --vaccuum-time 365d = dies löscht alle Logfiles/Journale die älter als 365 Tage sind (älter als 1 Jahr/anpassbar).
journalctl --vaccuum-size 1000M = Löscht entsprechend viele ältere Logfiles/Einträge bis die Logfiles nur die hier angegeben Menge an Speicherplatz belegen (hier 1 GB/anpassbar).
Man erhält beim Bereinigen im Anschluss eine Auflistung der gelöschten Journale und wieviel Speicherplatz freigegeben wurde.
Man kann hier auch andere typische vom System verwendete Maßeinheiten verwenden.
Die Logfile-/Journalgröße automatisch dauerhaft begrenzen (Speicherplatz sparen):
Die Größenbegrenzungen/Parameter sind Standardmäßig in der Datei '/etc/systemd/journald.conf' festgelegt.
Wichtig: Die Werte sind hier aber alle Standardmäßig auskommentiert und somit nicht aktiv.
Die vom System bereitgestellte originale Konfigurationsdatei sollte man nicht verändern,
damit die Änderungen auch nach Systemupdates/Systemupgrades erhalten bleiben.
Man erzeugt man daher wie folgt eine eigene/neue Konfigurationsdatei.
mkdir /etc/systemd/journald.conf.d/ # Ein neues Verzeichnis anlegen.
cp /etc/systemd/journald.conf /etc/systemd/journald.conf.d/my_journald.conf # Die vorhanden Konfigurationsdatei in den eben angelegten Ordner kopieren.
nano /etc/systemd/journald.conf.d/my_journald.conf = Die Datei mit einem Editor öffnen.
# Hier dann den Wert '#SystemMaxUse=' wie folgt abändern 'SystemMaxUse=100M'. Wichtig: Entfernt auch das führende auskommentierende Rautezeichen.
reboot # Spätestens nach einem Systemneustart wird das Logfile/Journal auf die hier angegeben maximale Größe verkleinert. Hier im Beispiel auf 100 MB.
kill:
Beendet einzelne Tasks.
kill -9 PID # PID = ist hierbei die Prozess-ID (Prozessnummer) die beendet werden soll. Die entsprechende PID kann man z. B. über den Befehl [top] ermitteln.
killall:
Beendet mehrere Prozesse mit demselben Namen.
killall -e MeinLangerProzessname = (exact) ist notwendig bei Prozessen wo der Prozessname länger als 15 Zeichen ist. Ohne der Angabe werden sonst alle Prozesse beendet wo die ersten 15 Zeichen übereinstimmen (ggf. wichtig).
killall -I prozessNAME = (ignore-case) die Groß- und Kleinschreibung wird nicht unterschieden.
killall -g Prozessname = (process-group) beendet die Prozessgruppe zu der der Prozess gehört. Das Signal zum Beenden wird nur einmal an die Gruppe gesendet, auch wenn mehrere Prozesse derselben Gruppe gefunden werden.
killall -o 1d Prozessname = (older-than) beendet nur Prozesse die älter als 1 Tag sind (entsprechend: s = secounds, m = minutes, h = hours, d = days, w = weeks, M = months, y = year).
killall -q Prozessname = (quite) es erfolgt keine Ausgabe über beendete Prozesse.
killall -r RegExAusdruck = (regexp) die Prozess-Namensübergabe erfolgt als regulärer Ausdruck.
killall -u Benutzername Prozessname = (username) es werden nur die Prozesse des Benutzers ... beendet.
killall -y 10m Prozessname = (younger-than) beendet nur Prozesse die jünger als 10 Minuten sind (entsprechend: s = secounds, m = minutes, h = hours, d = days, w = weeks, M = months, y = year).
Noch einige weitere Parameter findet man in der passenden manpage.
ln (link):
ln erstellt Verlinkungen (Verknüpfungen) zu einer Datei oder zu einem Verzeichnis.
Man kann auf verlinkte Dateien/Verzeichnisse, sowohl über ihren physischen Speicherplatz, als auch über die Verlinkung zugreifen.
Ein [Symbolischer Link] (Softlink) ähnelt der Verlinkung von Webseiten.
Für die Verlinkung auf die Originaldatei wird eine neue kleine Datei im derzeit verwendeten Directory angelegt. Diese kleine Datei enthält dann nur den Pfad zur Originaldatei.
Symbolische Verknüpfungen (symbolische links) sind daher über beliebige Dateisystemgrenzen hinweg möglich.
Löscht man einen Symbolischen Link, so wird nur dieser einzelne Link gelöscht, die Originaldatei bleibt bestehen.
Löscht man die Originaldatei, so laufen alle Symbolischen Links ins leere (tote Links).
Symbolische Links sind auch auf Verzeichnisse möglich.
Ein [Hardlink] ist ein weiterer direkter Verweis auf einen inode Verzeichniseintrag im Directory.
Hardlinks sind daher nicht über Dateisystemgrenzen möglich, da der physische Zugriff auf das Directory/Dateisystem benötigt wird.
Eine Hardlink verlinkte Datei wird erst endgültig gelöscht, wenn man alle weiteren Verlinkungen (inklusive des Originals) gelöscht hat.
Löscht man also nur einen einzelne HardLink, dann bleibt die Originaldatei bestehen.
Beachtet dabei noch folgendes: Alle verlinkten Dateien sind gleichwertig - es gibt also keine eindeutige Originaldatei.
Man selbst betrachtet meist die zuerst existierende Datei als Originaldatei, das System selbst unterscheidet dies jedoch nicht.
Wichtig: Hardlinks kann man nicht auf Verzeichnisse anlegen.
Parametererklärungen:
[-s] = erstellt einen symbolischen Link, ohne den Parameter wird ein harter Link erstellt.
Beispiele:
ln -s /Pfad_zur/Originaldatei /Pfad_zur/Verlinkung = Legt eine Symbolische Verknüpfung (Symbolischen Link) an, Verzeichnisse werden analog behandelt.
ln /Pfad_zur/Originaldatei /Pfad_zur/Verlinkung = Erzeugt einen Hardlink auf die entsprechende Datei, Verzeichnisse werden analog behandelt.
Gelöscht werden die Verknüpfungen/Links einfach mit (rm siehe unten) oder einem beliebigen Dateimanager.
alle Dateien mit Hardlinks anzeigen:
find . -type f -links +1 -print0 | xargs -0r ls -i | sort -n = Alle Dateien mit Hardlinks sortiert ausgeben (auch rekursiv).
find . -maxdepth 1 -type f -links +1 -print0 | xargs -0r ls -i | sort -n = Alle Dateien mit Hardlinks sortiert ausgeben nur im aktuellen Verzeichnis).
Parametererklärungen:
[.] = ist der aktuelle Pfad, hier kann man auch einen beliebigen anderen Pfad angeben.
[-type f] = nur nach Dateien suchen. Man könnte hier auch [! -type d] (Negation) keine Verzeichnisse suchen einsetzen.
[-links +1] = sucht nach Dateien mit mehr als einem Hardlink (inode).
[-print0] = hängt an jeden gefundenen Eintrag ein Nullbyte, zur sauberen Trennung von Dateinamen mit Sonderzeichen ist dies wichtig.
[xargs -0r] = Trennt den Datenstrom von der Standardeingabe am Nullbyte (-0) und übergibt diese Einträge dem nachfolgenden Befehl. Sollten keine Hardlinks gefunden werden (-r = --no-run-on-empty), dann die nachfolgenden Befehle nicht ausführen.
[ls -i] = Zeitgt die eindeutige inode Nummer zu der jeweiligen Datei an.
[sort -n] = Sortiert den Datenstrom nach den inode Zahlen (am Anfang) aufsteigend.
Alle Dateien die auf denselben inode Verweisen sind identisch.
alle Dateien mit Hardlinks löschen:
find . -type f -links +1 -exec rm -rfv '{}' \; = Löscht alle Hardlinks im aktuellen Verzeichnis und in allen Unterverzeichnissen. Eine Datei bleibt bestehen.
find . -maxdepth 1 -type f -links +1 -exec rm -rfv '{}' \; = Löscht alle Hardlinks nur im aktuellen Verzeichnis. Eine Datei bleibt bestehen.
Beachtet hierbei aber, die bestehende Datei kann sich in einem beliebigen Pfad auf Partition befinden.
Es wird hier so lange gelöscht, solange noch ein weiterer Hardlink auf die entsprechende Datei vorhanden ist.
ls (list):
Der Befehl listet den Inhalt eines Verzeichnisses auf.
ls -a = (all) zeigt alle Dateien, d. h. auch die versteckten Dateien an. Versteckte Dateien/Verzeichnisse haben immer einen Punkt [.] am Anfang im Namen.
ls -i = (inode), gibt am Anfang die inode-Nummer zu jeder Datei aus. Die inode-Nummer ist dabei ein Verweis auf einen eindeutigen Eintrag in der Verzeichnisstruktur.
Haben zwei Dateien die gleiche inode-Nummer so sind diese mit einem Hardlink verbunden.
ls -l = (long format), listet den Inhalt eines Verzeichnisses in ausführlicher Form auf.
ls -F = kennzeichnet Verzeichnisse mit [/] und ausführbare Dateien mit [*].
ls -liaF = Zeigt alles - im langen Format - mit Kennzeichnungen an (empfohlen).
lsattr (list file attributes):
lsattr zeigt die erweiterten Dateiattribute einer Datei an.
lsattr Datei1 Datei2 ... = Gibt die gesetzten Attribute nur für diese Datei(en) aus (mehrere Dateiangaben und Pfade sind möglich).
lsattr -a = Gibt die gesetzten Attribute für alle Dateien (auch versteckte) im aktuellen Verzeichnis aus.
lsattr -aR = Gibt die gesetzten Attribute für alle Dateien auch rekursiv aus.
lsattr /var/log = Gibt die gesetzten Attribute für alle Dateien im Verzeichnis '/var/log' aus.
lsattr -d /var/log = Gibt die gesetzten Attribute nur direkt für das Verzeichnis '/var/log' aus.
Beachtet, es wird hier also nur das Verzeichnis an sich selbst berücksichtig und nicht die darunter liegenden Dateien.
Optionale Parameter:
[-R] = (recursivly), Die Attribute rekursiv ausgeben.
[-V] = (version), Die Programmversion ausgeben.
[-a] = (all files); Alle Dateien berücksichtigen auch die mit führendem Punkt '.' (versteckte Dateien).
[-d] = (directories); Behandelt die angegebenen Verzeichnisse wie eine "normale Datei".
Ohne der Parameter Angabe '-d' wird stattdessen der Inhalt von allen angegeben Verzeichnissen durchsucht und ausgegeben.
[-l] = (long); Gibt statt den einzelnen Attribut-Zeichen, zu jedem gesetztem Attribut einen langen Namen aus.
Beispielsweise wird hier statt "-----i---------e-------" hier z. B. "Immutable, Extents" ausgegeben).
[-p] = (project); Listet die Projektnummer auf.
[-v] = (version); Listet die Dateiversions-/Generationsnummer auf.
Die Datei Attribute kann man mit dem Befehl chattr ändern.
lsb_release (Linux Standard Base Specification):
Gibt distributionsspezifische Informationen (wie z. B. die Anzeige der installierten Version, Codenamen usw.) aus.
lsb_release -a = Zeigt alle Infos über die derzeit aktive/installierte Version an.
lsb_release -sc = Gibt nur den Release-Namen aus (z. B. 'bionic' bei Ubuntu 18.04).
lsblk (list block devices):
lsblk listet Informationen von Blockbasierten Geräten wie Festplatten, SSDs usw. auf.
lsblk
lsblk -d = (nodeps) zeigt nur die Hauptgeräte an. Zeigt also keine Partitionen o. ä. an.
lsblk -f = (filesystem) zeigt zusätzliche Informationen zum verwendeten Dateisystem an.
lsblk -l = (list) zeigt die Informationen als Liste an.
lshw (list hardware):
Zeigt eine Übersicht der verwendeten Hardware an. Beachtet dabei, nur als root User/Administrator erhält man alle Informationen.
lshw -short = Gibt eine kurze Hardwareübersicht aus.
lshw | more = Gibt die komplette Hardwareübersicht seitenweise aus.
lshw -numeric -html > hw.htm && firefox hw.htm = Erzeugt eine komplette Hardwareübersicht als html Webseite, diese wird dann im Anschluss an den Firefox Webbrowser übergeben.
mail:
mail dient zum senden und empfangen von E-Mails.
E-Mails kann man problemlos über die Komandozeile/aus einem Shell-Script versenden.
mail = E-Mails lesen.
mail -s "Betreff" email@ctaas.com < Mailtext.txt = versendet den Inhalt der Datei 'Mailtext.txt' an die angegebene E-Mailadresse.
Wie man einen MTA (mail transfer agent) einrichtet und E-Mails aus einem System versendet habe ich hier beschrieben (Punkte: A-I/Postfix konfigurieren).
more:
Der Befehl zeigt eine Datei oder einen Datenstrom seitenweise am Bildschirm an.
more Datei
Zur nächsten Seite blättern = Leertaste.
Zeilenweise Blättern = Eingabetaste.
Seitenweise zurückgehen = b (back).
Anzeige beenden = q (quit).
mount:
mount dient zum Einhängen von verschiedenen fremdartigen Dateisystemen.
Hinweis:
Windows Partitionen werden standardmäßig so eingebunden, das alle Dateien als ausführbar erscheinen (selbst wenn es diese nicht sind).
Hat man wine (den Windows Emulator) installiert so lassen sich .exe Dateien sofort ausführen.
Zuerst sollte man ein Verzeichnis anlegen, wo das zu mountende Dateisystem eingebunden werden soll:
mkdir /mnt/mountpunkt
vorhandene Netzwerkfreigaben in Linux mounten:
mount benötigt ggf. das cifs-utils Paket [apt-get install cifs-utils].
mount -t cifs //IP-Adresse/Freigabe /mnt/mountpunkt/ -orw,user=Benutzername,password=Passwort,domain=Domäne_oder_Hostname,vers=2.1
wichtige Parametererklärungen:
Die angegebenen Parameter dürfen nicht durch Leerzeichen getrennt werden, sonst werden diese nicht geparst.
mount führt keine Namensauflösung durch, daher muss man zwingend
IP-Adressen verwenden.
rw - (read-write) schreibender Zugriff auf die Netzwerkfreigabe.
ro - (read-only) nur lesender Zugriff auf die Netzwerkfreigabe.
user=
Benutzername - ist der Benutzername der für die Freigabe benötigt wird.
password=
Passwort - ist das Passwort welches für die Freigabe benötigt wird. Hier also kein Linuxpasswort verwenden.
Lässt man den Parameter weg, so wird das Passwort in der Kommandozeile über die Frage '
Password:' abgefragt.
domain=
Domainname - ist der Domainname falls eine Domäne verwendet wird, bzw. falls keine Domain verwendet wird gibt man hier den Hostnamen (Computernamen) an.
# Mit [
vers=...] legt man die zu verwendende SMB-Protokoll Version für den Netzwerk Server fest (
1,
2,
3).
vers=1.0 = für Windows XP, Windows Server 2003 (R2), FritzBox.
vers=2.0 = für Windows Vista ab SP1, Windows Server 2008 (bzw. vers=2.0.2).
vers=2.1 = für Windows 7, Windows Server 2008 R2.
vers=3.0 = für Windows 8, Windows Server 2012.
vers=3.02 = für Windows 8.1, Windows Server 2012 R2.
vers=3.1.1 = für Windows 10, Windows Server 2016.
Hat man eine falsche Version angegeben, so erhält man ggf. den Fehler: [
mount error(112): Host is down] und das mounten der Netzwerkfreigabe schlägt fehl.
Tipp: Unter Windows kann man in einer [
Administrator: Windows PowerShell] mit dem Befehl: [
Get-SmbConnection] die derzeit genutzten Standards auflisten.
optionale Parameter (diese kann man in der Regel meist weglassen):
iocharset=
utf8 - bestimmt die Zeichensatzeinstellungen (Standard=utf8).
uid=
999 - ist die UserID und bestimmt welcher User der Zugriff auf die Freigabe haben soll.
dir_mode=
0777 - Setzt die Schreibrechte für Ordner (0777 = Zugriff für alle User - Standardwert ist 0755, sodass nur root Zugriff hat).
dir_mode=
0777 - Setzt die Schreibrechte für Dateien (0777 = Zugriff für alle User - Standardwert ist 0644, sodass nur root Zugriff hat).
Die festgelegten System-Rechte (Besitz & Zugriff) werden nur lokal simuliert und nicht auf die Freigabe übertragen.
Für ältere Versionen wird ggf. das Paket smbfs benötigt [apt-get install smbfs].
mount -t smbfs -o username=Benutzer/Domäne,password=Passwort,uid=1000,gid=1000 //IP-Adresse/Freigabe /mnt/mountpunkt
Festplatten Partitionen von einer Live-DVD aus mounten:
Der Dateisystemtyp (-t) wird bei neueren Linux Versionen in der Regel automatisch erkannt.
So das folgende vereinfachte mount-Varianten meist ausreichen sollten:
mount /dev/sda2 /mnt/mountpunkt -o utf8 = (read write) Festplatte mit Schreibzugriff (Standard=rw) mounten.
mount /dev/sda2 /mnt/mountpunkt -o ro,utf8 = (read only) Festplatte nur lesbar mounten.
Hinweis:
Standardmäßig werden Schreibzugriffe gepuffert (Parameter: async) - man sollte daher Wechseldatenträger vor dem entfernen abmelden (umount).
alternative Parameter:
iso8859-1 = alternativer Zeichensatz falls utf8 nicht passt (VFAT nur alte Systeme).
umask=0222 = alternative Zugriffsberechtigungen.
exec/noexec = Ausführrechte für Binärdateien festlegen.
sync = Schreibzugriffe werden immer sofort ausgeführt (evtl. langsamer) - sinnvoll bei Wechseldatenträgern wie UBS-Sticks.
CD/DVD-Images und dd-Images in Linux mounten:
mount -o loop /Pfad/Imagedatei.iso /mnt/mountpunkt
Permanentes mounten beim Systemstart:
blkid = zeigt unter anderem die UUID und den Typen von Partitionen an.
Die mount-Einträge werden in folgender Datei festgelegt:
nano /etc/fstab = mount Einträge festlegen.
Der typische Aufbau für eine Festplatte ist wie folgt:
# <UUID> <mount-Punkt> <Dateisystem-Typ> <Optionen> <dump> <pass>
UUID=666a555b-4c33-... /mnt/hd ext4 errors=remount-ro 0 1
Optionale Parameter:
,ro (unter Optionen) = bewirkt das die Freigabe nur lesend eingebunden wird (Parametertrennzeichen=,).
0 (unter pass) = regelmäßige Dateisystemprüfung beim Systemstart abschalten.
Freigaben abmelden/aushängen:
umount /mnt/mountpunkt
mount -l = Anzeige aller gemounteten Datenträger.
mkdir (make dir):
Mit dem Befehl können sie neue Verzeichnisse anlegen.
mkdir neuer_Ordner
mkdir -pv Ordner1/Ordner2/Ordner3 = (parents/verbose) legt die ganze Ordnerstruktur auf einmal an (mit allen Unterordnern).
mkfs (make filesystem):
Mit dem Befehl kann man Datenträger/Partitionen mit einem Dateisystem versehen (entsprechend Formatieren).
Vorsicht: Beim Formatieren werden alle Daten auf dem angegebenen Datenträger/auf der Partition gelöscht.
mkfs -t exfat -n "exfat" -s 2048 /dev/sda1 = Formatiert den angegebenen Datenträger mit dem exFAT-Dateisystem. Benötigt ggf. folgendes apt-get install exfat-utils.
mkfs.xfs /dev/sda1 = Formatiert den angegebenen Datenträger mit dem XFS-Dateisystem.
mkfs.ext4 -E lazy_itable_init=0,lazy_journal_init=0 -L "Label-Name" /dev/sda1 = Formatiert den angegebenen Datenträger mit dem ext4-Dateisystem.
Die Inode-Tabellen (lazyinit) werden dabei sofort vollständig initialisiert (empfohlen insbesondere bei größeren Datenträgern)
Beachtet dabei, der optionale Datenträgername (volume label) darf maximal 16 Zeichen lang sein. Gibt man keinen Datenträgernamen an so bleibt dieser leer ("").
mkfs.vfat -F 32 /dev/sda1 = Formatiert die angegebene Partition mit dem FAT32-Dateisystem. Hinweis: Es muss bereits eine Partition existieren (für Laufwerke über 32 MB).
mkfs.vfat -F 16 /dev/sda1 = Formatiert die angegebene Partition mit dem FAT16-Dateisystem. Hinweis: Es muss bereits eine Partition existieren (auch für kleine Laufwerke unter 32 MB).
mkfs.vfat -F 12 /dev/sda1 = Formatiert die angegebene Partition mit dem FAT12-Dateisystem. Hinweis: Es muss bereits eine Partition existieren (auch für kleine Laufwerke unter 32 MB).
mkfs -t vfat /dev/sda1 = Formatiert die angegebene Partition mit dem FAT16-Dateisystem. Hinweis: Es muss bereits eine Partition existieren (auch für kleine Laufwerke unter 32 MB).
mkfs.btrfs -L "ein_Name" /dev/sda1 = Formatiert den angegebenen Datenträger mit dem Btrfs-Dateisystem. Der Datenträger erhält die Bezeichnung "ein_Name".
mv (move):
Mit dem Befehl kann man eine Datei bzw. einen Ordner - verschieben und/oder umbenennen - auch über Verzeichnisebenen hinweg.
mv alter_Dateiname neuer_Dateiname = Nennt die Datei um - Verzeichnisse behandelt man analog.
mv /home/User1/Datei /home/User2/ = Verschiebt die Datei vom User1-Verzeichnis in das User2-Verzeichnis ohne den Namen zu ändern.
mv Datei /home/User2/neuer_Dateiname = Verschiebt die Datei in das User2-Verzeichnis mit einem neuen Dateinamen.
nmap:
nmap ist ein Netzwerk-Analysewerkzeug und Sicherheits-/Portscanner.
nmap -sP 192.168.1.0/24 = lokaler Ping-Scan - gibt alle verfügbaren Hosts aus.
nmap 192.168.1.100 = Portscan auf der angegebenen IP-Adresse. Welche Ports sind offen?
nohup (no hangup):
Mit nohup kann man Programme/Befehle/Scripte usw. im Hintergrund zu starten. Das SIGHUP-Signal (hangup) beim Schließen eines Terminals wird entsprechend ignoriert.
Ausgaben auf die Standardausgabe und Standardfehlerausgabe werden standardmäßig in die Datei 'nohup.out' im aktuellen Verzeichnis umgeleitet. Eine bereits bestehende Datei wird entsprechend fortgesetzt. Hat man im aktuellen Verzeichnis keine Schreibrechte, dann wird die Datei im Homeverzeichnis '~/nohup.out' abgelegt.
nohup ist vor allem sinnvoll wenn man Programme aus einem Terminal heraus starten möchte.
Zum einen kann man das Terminal für weitere Programme verwenden. Zum anderen läuft das Programm auch nach dem beenden des Terminals im Hintergrund weiter.
Sinnvoll ist nohup auch wenn man ein länger andauerndes Programm über eine SSH-Verbindung starten möchte.
Denn das Programm läuft dann auch nach einer Trennung der SSH-Verbindung im Hintergrund auf dem Zielsystem weiter.
nohup Programm & = Startet das Programm im Hintergrund.
nohup notepad >/dev/null & = Startet den Texteditor 'notepad' im Hintergrund. Ausgaben auf der Standardausgabe werden nicht gespeichert. Auch nach dem beenden des Terminals bleibt der Editor offen.
nohup Befehl >Ausgabe.txt & = Ausgaben der Standardausgabe/Standardfehlerausgabe kann man auch gezielt in eine andere Datei umleiten. Die nohup.out Datei wird dann nicht erzeugt.
nohup bash -c "sleep 7; touch Test.txt" & = Will man mehrere Befehle hintereinander ausführen, so muss man diese wie folgt an die bash übergeben.
nohup mein_script.sh & = Als Alternative, startet man einfach ein eigenes Bash/Shell-Script. In dem Script kann man dann ebenso beliebige Befehle übergeben.
nohup Programm >Ausgabe.txt 2>Error.txt </dev/null & = falls das Programm Eingaben erwartet ist ggf. eine Umleitung der Standardeingabe nötig. Hier wird die Standardausgabe, die Standardfehlerausgabe und die Standardeingabe jeweils getrennt umgeleitet.
Beispielausgabe - beachtet dabei, nach dem Start wird eine fortlaufende Nummer und die Prozess-ID ausgegeben:
root@hostname:~# nohup mousepad >/dev/null &
[1] 12345
root@hostname:~# nohup: ignoring input and redirecting stderr to stdout
den Prozess im Hintergrund beenden (nur falls er hängt):
ps | grep Befehl = ggf. nochmals die Prozess-ID zum Befehl ermitteln (den Befehl entsprechend anpassen).
kill -9 12345 = den Prozess mit der Prozess-ID 12345 beenden (die ID entsprechend anpassen).
NVMe (NVM Express):
Verwendet man einen neueren PC bei dem die SSD nicht mehr über SATA sondern mittels NVM Express/PCI Express direkt angeschlossen ist, dann ändert sich der Interfacename.
Beispielsweise wird:
'/dev/sda1' zu '/dev/nvme0n1p1' bzw.
'/dev/sda' zu '/dev/nvme0n1'.
Der Namensaufbau ist dabei wie folgt:
[/dev/nvme] = device NVM Express +
[0] = Controllernummer +
[n1] = Namespace +
[p1] = Partitionsnummer.
apt install nvme-cli = die NVMe Tools installieren.
nvme list = alle NVMe SSDs tabellarisch auflisten.
nvme id-ctrl /dev/nvme0n1 | egrep "sn|mn" = Seriennummer anzeigen.
nvme smart-log /dev/nvme0n1 = Smart-Werte anzeigen.
nvme error-log /dev/nvme0n1 = Error-Log Anzeigen
partclone:
partclone dient zum Sichern von Partitionen.
Partclone kann verschiedene Formate sichern wie z. B. ext3, ext4, hfs+, btrfs, xfs, ntfs, fat(12/16/32).
Partclone verwendet je nach Dateisystem verschiedene Unterprogramme.
Der Aufruf ist also für jedes Dateisystem etwas unterschiedlich [partclone.Dateisystem-Typ Parameter].
Hier ein Beispiel für die meist verwendeten ext4-Dateisysteme:
partclone installieren:
apt-get install partclone
ext4-Partitionen sichern (als root starten):
partclone.ext4 -c -R -s /dev/sda1 -o /Pfad/bkup_sda1_partclone.ext4.img = sichern der Partition ohne Komprimierung.
partclone.ext4 -c -R -s /dev/sda1 | gzip -c9 > /Pfad/bckup_sda1_partclone.ext4.img.gz = Sicherung der Partition mit gzip-Komprimierung.
partclone.ext4 -cRs /dev/sda1 | bzi2 -cz9 > /Pfad/bkup_sda1_partclone.ext4.img.bz2 = Sicherung der Partition mit bzip2 Komprimierung (beste Komprimierung/empfohlen).
ext4-Partitionen zurücksichern (als root starten):
partclone.ext4 -r -s bkup_sda1_partclone.ext4.img -o /dev/sda1 = Rücksicherung der Partition ohne Komprimierung.
zcat /Pfad/bkup_sda1_partclone.ext4.img.gz | partclone.ext4 -r -o /dev/sda1 = Rücksicherung der Partition mit gzip-Komprimierung.
bzip2 -cd /Pfad/bkup_sda1_partclone.ext4.img.bz2 | partclone.ext4 -ro /dev/sda1 = Rücksicherung der Partition mit bzip2 Komprimierung (empfohlen).
Alternative Weblinks:
clonezilla.org (de.wikipedia.org/wiki/Clonezilla) - enthält unter anderem partclone.
passwd (password):
Dient zum Setzen von Passwörtern für Benutzer.
Der Standarduser kann nur sein eigenes Passwort ändern.
Der Superuser (root) kann Passwörter aller User ändern.
passwd Benutzername = setzt für den Benutzer ein neues Passwort. Das neue Passwort wird dabei auf der Kommandozeile abgefragt.
Standarduser müssen zuvor ihr altes Passwort eingeben um das Passwort ändern zu können.
sudo passwd root = setzt das root Passwort.
Wenn die Passwortkomplexität aktiviert ist, so muss das Passwort aus Buchstaben, Zahlen und Sonderzeichen bestehen und mindestens 6-8 Zeichen lang sein. Passt die Komplexität nicht, so wird das neue Passwort nicht angenommen.
Hinweis bei Live-Systemen:
Startet man von einer Live-DVD, so wird man in der Regel automatisch angemeldet.
Unter Ubuntu-basierenden-Systemen heißt der Benutzername meist wie die gestartete Umgebung (also ubuntu,
xubuntu, lubuntu, ubuntu-mate) usw.
Bei Ubuntu-basierenden-Systemen wird dabei für den Benutzer in der Regel kein Passwort vergeben.
passwd xubuntu = Setzt unter einem Xubuntu-Live-System das xubuntu-Passwort.
Bei debian-basierenden-Systemen heißt der Benutzername meist user und das Passwort live.
sudo passwd user = Ändert das user-Passwort bei Verwendung einer Debian-Live-DVD.
Man kann auch bei Live-Systemen das Passwort wie oben angegeben ändern und so das Live-System vor Zugriffen sperren.
Beachten muss man hier ggf. die TTY Consolen Strg + Alt und F1 - F7 diese sind ggf. nicht gesperrt.
ps (processes):
Zeigt eine Momentaufnahme von laufenden Prozessen an.
ps aux = Alle Prozesse in einer ausführlichen Ansicht anzeigen (BSD-Syntax).
ps -eF = Alle Prozesse in einer ausführlichen Ansicht anzeigen.
ps aux | grep XYZ = Die Ausgabe filtern z. B. zum Prüfen ob Programm XYZ läuft.
echo $(ps -C Prozess|wc -l) -1|bc = Ermittelt die Anzahl der laufenden Prozesse (zuerst mittells 'ps' die Anzahl der laufenden Prozesse zählen; die Zeilen zusammenzählen mittels 'wc'; die überflüssige Kopfzeile '-1' mittels 'bc' abziehen).
pv (monitor the progress of a data throuh a pipe):
Zeigt bei Streams unter anderem die Laufzeit, den Datendurchsatz, den erreichten Prozentsatz mit Balken und die verbleibende Restzeit an.
apt-get install pv = pv installieren.
Festplattenbackup mit Statusanzeige:
vor dem Sichern/Rücksichern swapping deaktivieren:
swapoff -a = (swapping deaktivieren) es kann sonst passieren das, das Live-System die swap-Partition verwendet und so ein Rücksichern verhindert.
Sicherung komplette Festplatte:
pv -EE /dev/sda > /mnt/Pfad/sda_pv.img = Sicherung (bei evtl. auftretenden Lesefehlern weitermachen).
pv -EE /dev/sda | bzip2 -cz9 > /mnt/Pfad/sda_pv.img.bz2 = Sicherung (bei Lesefehlern weiter machen & Komprimierung).
Restore komplette Festplatte:
pv /mnt/Pfad/sda_pv.img > /dev/sda = Rücksicherung.
bzip2 -cd sda_pv.img.bz2 | pv > /dev/sda = Rücksicherung eines komprimierten Images.
pwd (print working directory):
Dieser Befehl gibt das Verzeichnis aus, in dem man sich gerade befindet.
pwd
qrencode:
Mit qrencode kann man Weblinks/URLs/Texte/Zeichenketten usw. in einen QR-Code umwandeln.
Das Programm zum Erstellen der QR-Codes installieren:
apt install qrencode
QR-Codes kann man dann wie folgt erstellen:
qrencode -l H -s 80 -o QR-Code.png https://ctaas.de = Erzeugt ein 'QR-Code.png' Bild das hier den codierten Link auf die URL: 'https://ctaas.de' enthält.
qrencode -l H -t SVG -o QR-Code.svg https://ctaas.de = Erzeugt eine 'QR-Code.svg' Datei die hier den codierten Link auf die URL: 'https://ctaas.de' enthält.
qrencode -m 1 -l L -t UTF8 -o QR-Code-UTF8.txt https://ctaas.de = Erzeugt den QR-Code als sehr kompakten Text im UTF8-Format der nur aus Blockzeichensymbolen besteht (Ränder nach außen können daher teilweise unterschiedlich sein).
Man kann für einen individuellen anderen Rand den '-m' Wert verändern (0 = kleinster code/ohne Rand, 1 = empfohlen dezenter Rand oder beliebig größer).
Achtung: Mobile Webbrowser verändern oft die Anzeige des Codes, wenn kein eigen gehosteter Font genutzt wird - selbst wenn man eigentlich: 'font-family:monospace;' verwendet. Hostet daher bei dieser Variante immer einen eigenen monospace Font.
qrencode -m 0 -l H -t ASCII -o QR-Code-ASCII.txt https://ctaas.de = Erzeugt hier eine 'QR-Code-ASCII.txt' Datei die den QR-Code entsprechend als Text mit Rautezeichen '#' enthält.
Wenn man nun noch das Rautezeichen '#' durch das Block Zeichen '█' auswechselt, dann kann man den Code gut auf Webseiten einbinden. Beachtet hier dabei das ihr einen monospace Font verwendet.
Parametererklärung:
[-l H] = Beeinflusst die Fehlerkorrektur, der Code wird robuster bei teilweiser Beschädigung aber auch größer. Folgende Werte sind für die Fehlerkorrektur möglich:
L (low) ~ 7 %, M (medium ist Standard) ~ 15 %,
Q (quartile) ~ 25 %, H (high) ~ 30 %
[-s 80] = (size) Bestimmt dabei die Pixelbreite eines Quaders innerhalb des QR-Codes (Standard = 3). Dies ist nur relevant bei Bildformaten wie PNG.
[-t] = (type) Bestimmt den Ausgabetyp vom QR-Code sinnvoll/empfehlenswert sind u. a. folgende Typen: PNG, SVG, ASCII, ASCIIi (inverted ASCII), UTF8 (es gibt noch mehr).
[-m 3] = (margin) Bestimmt dabei den weißen Abstand zum Rand. Der Standardwert ist je nach Version 2-4, 0 bedeutet dabei das der QR-Code ohne Rand erzeugt wird.
[-r Datei.txt] = (read) Liest die in den QR-Code einzubindenden Daten aus der angegebenen Datei.
[-o] = (output) Bestimmt dabei den Dateinamen des QR-Codes.
Danach wird der im Bild einzubindende Text einfach angehängt (sofern man keinen Parameter -r verwendet).
Einbindung im Web bevorzugt so (empfohlen):
<img style="width:200px;max-width:100%;border:3px solid #222;border-radius:23px;image-rendering:pixelated" loading="lazy" src="QR-Code.png" alt="QR-Code"><br>
Insbesondere folgendes wäre hier wichtig:
image-rendering:pixelated; = als Style sorgt dafür das kein Antialiasing erfolgt.
So bleibt hier immer eine scharfe und unverfälschte Darstellung erhalten. Die Kanten bleiben klar und es entstehen keine grauen Ränder bei der Skalierung im Browser.
Beachtet weiterhin:
Durch den großen Border-Radius border-radius:23px; wird unten rechts zum Teil ein kleiner Bereich abgeschnitten/verdeckt.
Dieser Fehler wird normalerweise durch die Fehlerkorrektur automatisch korrigiert. Nutzt diesen vergrößerten Radius daher nur, wenn ihr eine ausreichende Fehlerkorrektur verwendet ('-l H' Beispielsweise).
reboot:
Startet das System neu.
reboot
rm (remove):
Mit diesem Befehl kann man Dateien löschen und Verzeichnisse löschen.
rm "zu_löschende_Datei" = Löscht die angegebene Datei.
rm -rf "Verzeichnis" = Löscht auch nicht leere Verzeichnisse (rekursiv), nicht vorhandene werden ignoriert (force).
rm -rf "~/.local/share/Trash/"* = Leert den Papierkorb (Mülleimer) vom angemeldeten User.
Wichtig: Pfade und Dateinamen sollte man immer in Anführungszeichen setzen (double quoted) um Namen mit Sonderzeichen/Leerzeichen zu berücksichtigen.
Eventuelle Joker wie das Malzeichen (*) oder das Fragezeichen (?) werden außerhalb der Anführungszeichen gesetzt. Siehe folgendes Beispiel:
rm -rf "1"???".txt" = entfernt z. B. 1001.txt, 1002.txt, 1abc.txt, 1???.txt, 1***.txt, 1\*?.txt usw.
rmdir (remove directory):
Mit dem Befehl kann man ein Verzeichnis nur löschen wenn es leer ist.
rmdir "zu_löschender_Ordner" = Löscht das angegebene Verzeichnis.
Volle Verzeichnisse löscht man mit rm.
Mehrere leere Verzeichnisse löscht man am besten mit find.
sed (stream editor):
Dieser Befehl ruft den Stream Editor auf. Der Stream Editor erlaubt es, Dateien durch Mustervergleich (pattern matching) und Ersetzungen zu verändern.
Die Ausgabe erfolgt über die Standardausgabe, eine Umleitung ist möglich.
Standardmäßig unterstützt sed auch regular expression (Regex),
(Beispiele/englische Wikipedia).
Dadurch sind sehr komplexe Bearbeitungsmöglichkeiten möglich.
Zum besseren Verständnis hier ein paar gängige Beispiele:
sed -i -e '/^#/d' /d' 'Datei.txt' # Entfernt alle Zeilen die mit einem Rautezeichen (#), meist ein Kommentar beginnen.
sed -i -e '/^#/d' -e '/^ /d' 'Datei.txt' # Entfernt alle Zeilen die mit einem führende Leerzeichen [ ] beginnen und alle Kommentarzeilen die mit einem [#] (Kommentar) beginnen.
sed '4d' 'input.txt' > 'output.txt' = Löscht die 4. Zeile aus dem input.txt Textdokument und gibt das Ergebnis als output.txt aus.
sed -i -e "s/Suchstring/Ersetzung/g" 'Datei.txt' = Ersetzt in der angegebenen Datei alle Übereinstimmungen zu dem angegebenen 'Suchstring' hier mit der entsprechenden 'Ersetzung'.
sed -i '0,/Suchstring/s//Ersetzung/' 'Datei.txt' = Es wird nur die erste Übereinstimmung in der angegebenen Datei ersetzt. Alle anderen nachfolgenden Fundstellen bleiben unverändert.
sed -i -e "s/\"/#/g" 'Datei.txt' = Ersetzt in der angegebenen Datei alle Anführungszeichen (") mit dem Rautezeichen (#).
Beachtet dabei das hier das Anführungszeichen innerhalb des Suchstrings mit einem führenden Backslash (\) maskiert wurde, damit der Befehl ordentlich abgearbeitet werden kann.
sed -i.bak "/Name/s/\bAnton\b/Berta/g" Datei.txt = Ersetzt nur in Zeilen in denen das Wort 'Name' vorkommt 'Anton' mit 'Berta' (egal an welcher Stelle dies in dieser Zeile steht).
Alle anderen Stellen wo 'Anton' vorkommen würde werden nicht ersetzt. Beachtet hier die etwas veränderte Syntax.
sed -i "s/memory_limit = .*M/memory_limit = 4096 M/" 'Datei.txt' = Ersetzt in der Datei.txt alle Werte von 'memory_limit = ... M', durch den Wert 'memory_limit = 4096 M'.
Beachtet das hier '.*' als Regex Ausdruck interpretiert wird.
Der Punkt (.) bedeutet hier das jedes beliebiges Zeichen vorkommen kann.
Und der Stern (*) bedeutet, dass das Zeichen davor beliebig oft (oder gar nicht) vorkommen kann.
Daraus folgt das durch die Zeichenkette '.*' jede beliebige Zeichenfolge akzeptiert wird, einschließlich einer leeren Zeichenfolge, so lange diese innerhalb einer Zeile (also ohne Zeilenumbruch) stehen.
Beachtet hier auch die etwas veränderte Syntax, das [/g] (global) darf hier nicht angehängt werden und es werden auch so alle Fundstellen in der angegebenen Datei ersetzt.
sed -i "s/Variable = .*/Variable = 64/" 'Datei.txt' = Ersetzt in der Datei.txt alle Werte der 'Variable = ...', durch den Wert 'Variable = 64'.
Beachtet hier dabei, da hier nach dem Regex Ausdruck '.*' (Joker) hier im Suchstring nichts mehr folgt, wird hier beim Ersetzen jeglicher Text nach der Variable innerhalb derselben Zeile mit gelöscht/ersetzt.
sed -i '3iNeuer Inhalt in dieser Zeile' 'Datei.txt' = Fügt vor (insert) der 3. Zeile eine Leerzeile ein.
sed -i '4aNeuer Inhalt in dieser Zeile' 'Datei.txt' = Fügt nach (after) der 4. Zeile eine Leerzeile ein.
sed -i '$aNeuer Inhalt am Ende' 'Datei.txt' = Fügt am Ende (appand) eine neue Leerzeile ein. Bitte hier jeweils die Hochkomma (') so, wie hier angegeben verwenden.
sed -i 's!/home/anton/!/home/berta/!' 'Datei.txt' = Normalerweise verwendet man den Slash (/) als Trennzeichen, dieses Zeichen kann man beliebig ersetzen.
Hier wurde nun beispielsweise statt dem Slash (/) eben ein Ausrufezeichen (!) verwendet.
Dies kann insbesondere bei Pfadangaben zu Dateien nützlich sein, da man dann das Slashzeichen nicht ständig maskieren muss.
Komplexere Varianten:
sed -i ':a;N;$!ba;s/\n\r\n\r/\n\r/g" 'Datei.txt' = Fasst immer zwei Zeilenumbrüche von einer Windows Textdatei mit Carriage Return [CR] (\n) und Line Feed [LF] (\r) zu einem Zeilenumbruch zusammen.
sed -i 's/[ ]\+/ /g' 'Datei.txt' = Ersetzt mehrfach auftretende Leerzeichen ([ ]) nur durch ein einzelnes Leerzeichen (/ /).
sed -i 's/^[ \t]*//' 'Datei.txt' = Entfernt alle führenden Leerzeichen ' ' und Tabulatoren '\t' innerhalb einer Zeile.
sed -i 's/[ \r\n]*$/\r/' 'Datei.txt' = Entfernt von Dateien im Windows [CR] (\r) [LF] (\n) UTF-8 Format am Ende einer Zeile (*$) alle Leerzeichen (Tabulatoren bleiben bestehen).
sed -i 's/[\t \r\n]*$/\r/' 'Datei.txt' = Entfernt von Dateien im Windows [CR] (\r) [LF] (\n) UTF-8 Format am Ende einer Zeile (*$) alle Tabulatoren (\t) und Leerzeichen ( ).
sed -i -e 's/\t/ /g' 'Datei.txt' = Ersetzt alle Tabulatoren in der angegebenen Datei durch 4 Leerzeichen.
Wichtige ergänzende/optionale Parametererklärungen:
Das führende [^] Zeichen bestimmt das nur das erste Zeichen in einer Zeile gesucht/ersetzt wird.
Das führende [s/] bedeutet (search), dies gibt also den Suchstring an.
Das am Ende angehängte [/g] bedeutet (global), dies bedeutet das alle Fundstellen ersetzt werden. Ohne der Angabe /g wird nur die erste Fundstelle ersetzt. Achtung: Dies funktioniert nicht immer. Auch ohne den Parameter '/g' kann es daher sein, dass alle Fundstellen ersetzt werden. Dies ist wohl Syntax abhängig.
Der Parameter [-i] (in-place) bedeutet, die original Datei wird direkt bearbeitet und somit ggf. verändert.
Der Parameter [-i.bak] (in-place) bedeutet, bevor die original Datei wird verändert wird, wird von der Original-Datei ein Backup mit der Endung '.bak' (beliebig änderbar) erzeugt.
Regulare Ausdrücke (Regex) sollte man bevorzugt in eckige Klammern '[ ]' setzen dies erleichtert die Lesbarkeit von Konstrukten z. B. [\t\r\n]. Alternativ kann man auch ein [-e] verwenden.
sed Definitionen in eine extra Datei auslagern:
sed -i -f 'sedfile_definitionen.txt' 'zu_bearbeitende_Datei.txt' = Die Veränderungen/Ersetzungsdefinitionen stehen alle zeilenweise in einer separaten Datei.
In der Datei 'sedfile_definitionen.txt' könnte z. B. so etwas in der Art drin stehen:
s!ZEILE-SUCHEN.*!UND-ERSETZEN-MIT!
Beachtet weiterhin die Maskierung von Sonderzeichen (für sed):
Maskiert werden müssen unter anderem der Backslash (\) und die Anführungszeichen (") durch einen weiteren führenden Backslash.
Die Maskierung erfolgt dabei wie folgt:
\ wird zu \\
" wird zu \"
Achtung: Führt die Ersetzung in dieser Reihenfolge aus (nicht anders herum)!
Achtung: Beachtet bei Ersetzungen mittels Notepad++ (unter Windows) das ihr dabei in der Suchmaske den 'Suchmodus' auf 'Normal' umstellt.
Für Windows empfehle ich die folgende sed Version:
github.com/mbuilov/sed-windows
Tipps für sed unter Windows:
Unter Windows muss man statt den Hochkommas (') muss man hier Anführungszeichen (") verwenden also z. B. so:
sed -i -e "s/suchen/ersetzen/g" "Datei.txt"
setterm:
setterm passt Terminal Einstellungen an.
setterm -blank 0 -powerdown 0 = verhindert das Abschalten des Terminals/Consolen-Bildschirms (Bildschirmschoner/Energiesparmodus ausschalten).
echo setterm -blank 0 -powerdown 0 >> ~/.bash_profile = Immer nach dem Systemneustart das power management abschalten (Eintrag im Autostart).
Bei älteren Versionen muss man [-powersave off] verwenden.
Für Systeme mit X-Window verwendet man:
xset s off -dpms
Der Start ist nur im grafischen Terminal möglich.
Um den xscreensaver (Bildschirmschoner) zu deaktivieren verwendet man:
xscreensaver-command -exit
shred:
shred dient zum "sicheren" löschen von einzelnen Dateien und ganzen Festplatten.
Hinweise:
Will man ganze Speichermedien wie z. B. Festplatten Shreddern, so sollte man diese vom System abmelden (umount), denn nur so wird sichergestellt das alle Daten gelöscht werden.
Bei einigen Journalbasierenden Dateisystemen sowie bei Flash-Speichermedien wie z. B. SSD's, USB-Sticks, Kamera-Chips usw. können Datenreste erhalten bleiben.
Da der Controller im Speichermedium, bzw. der Treiber vom Dateisystem - Schreibzugriffe möglicherweise auf andere Bereiche umlenkt. Die zu löschenden Daten können daher trotz Shreddern noch vorhanden sein.
Will man also Speichermedien sicher löschen, so sollte man diese komplett mit anderen Daten beschreiben bis die Speichermedien vollgeschrieben sind (siehe cat oben).
Denn dann sind definitiv alle vorhandenen Daten überschrieben und nicht wieder herstellbar (sicheres SSD löschen).
Beachten sollte man dabei aber, das einige Flash-Medien wie z. B. SSD's eine Hardware-Komprimierung im Controller vornehmen, daher sollte man insbesondere SSD's nicht nur mit Nullen '0' überschreiben.
shred -v -n 2 /Pfad/Dateiname = Überschreibt den Inhalt der angegebene Datei 2 mal mit zufälligen Zeichen (die Datei wird nicht gelöscht).
shred -v -u -n 2 /Pfad/Dateiname = Überschreibt den Inhalt der angegebene Datei 2 mal mit zufälligen Zeichen und löscht diese danach.
shred -v -n 2 /dev/sdx = Die angegebene Festplatte wird 2 mal komplett mit zufälligen Daten gefüllt (gelöscht).
Will man ganze Ordner sicher löschen, so sollte man wipe verwenden.
Tipp: Will man ein Smartphone/Tablet (Android/Apple) sicher löschen, so sollte man dieses erst zurücksetzen und anschließend so lange ein Video aufnehmen, bis der interne Speicher komplett überschrieben ist.
Alle alten Dateien werden damit überschrieben und sind somit nicht mehr wieder herstellbar.
shutdown:
shutdown -hP now = den PC ausschalten.
Parameterbeschreibung:
[-h] = (halt) den PC anhalten oder ausschalten.
[-P] = (power off) also komplett ausschalten.
[now] = (nun) also sofort, und ohne Verzögerung.
sleep:
Hält das gerade laufende Programm/Script für die angegebene Zeit in Sekunden an.
sleep 10 = Wartet 10 Sekunden.
sleep 3.5s = Wartet 3,5 Sekunden (die Einheitenübergabe muss ohne Leerzeichen erfolgen, statt dem Komma wird ein Punkt verwendet).
sleep 10m = Wartet 10 Minuten (s = Sekunden/seconds, m = Minuten/minutes, h = Stunden/hours, d = Tage/days).
Programm && sleep 7 && Programm = Macht zwischen den zwei Befehlen eine 7 Sekunden Pause.
sleep 30m && killall Programm = Beendet nach 30 Minuten Wartezeit alle Instanzen des Programms mit dem entsprechenden Namen.
sort:
Mit sort kann man Dateien (bzw. Datenströme) Zeilenweise sortieren. Mehrere unsortierte Dateien kann sort zu einer sortierten Datei zusammenfassen.
Mit sort kann man weiterhin überprüfen ob die Daten schon sortiert sind.
Numerische Sortierungen werden ggf. von der Variable LC_NUMERIC beeinflusst. Alphabetische Sortierung werden ggf. von Internationalisierungs-Einstellungen, den Variablen LANG, LC_ALL, LC_COLLATE usw. beeinflusst.
Alle Ausgaben werden Standardmäßig auf der Standardausgabe ausgegeben. Systemtypische Umleitungen über die Pipe '|' bzw. in eine Datei mittels dem Größerzeichen '>' sind möglich.
sort Datei.txt = Aufsteigend sortieren von 0-9, a-z ... A-Z usw.
sort -r Datei.txt = (reverse) Absteigend sortieren von 9-0, Z-A ... z-a usw.
sort Datei1.txt Datei2.txt -o Sortiert.txt = Sortiert den Inhalt der Datei1.txt und der Datei2.txt. Die Ausgabe wird in der Datei Sortiert.txt abgespeichert.
sort -n Datei.txt = (numeric-sort) Sortiert mit einem String-Vergleich, ist somit praktisch nur für ganze Zahlen geeignet. Führende Nullen (0), Vorzeichen (+/-) usw. werden nicht unterstützt (diese verfälschen das Sortierergebnis).
sort -g Datei.txt = (general-numeric-sort) konvertiert die gegebenen Zahlen vor der Sortierung zuerst in eine Gleitkommazahl mit doppelter Genauigkeit.
Es werden dabei Wissenschaftliche Notationen, Vorzeichen, Tausender-Punkte, Komma usw. mit berücksichtigt z. B.: 1.0e-34, 10e100, +5, -100, 0.0025, 65.536, 3,50 usw.
Die Sortierung erfolgt ggf. etwas langsamer, dafür aber exakt, nach dem allgemeinen numerischen Wert.
sort -h Datei.txt = (human-readable) Sortiert Zahlen im menschenlesbarem Format wie z. B.: 64K (Kilobyte), M (Megabyte), G (Gigabyte), T (Terabyte), P (Petabyte), E (Exabyte), Z (Zettabyte), Y (Yottabyte).
Komplexere Varianten:
sort -k3 -n Datei.txt = (key) Legt fest nach welcher Spalte sortiert werden soll. Hier wird Beispielsweise die Spalte 3, mit mumeric-sort sortiert. Man kann die Parameter wie im nächsten Beispiel gezeigt zusammenfassen.
sort -k2n -k1r Datei.txt = Mehrere Spalten kann man wie folgt sortieren. Hier wird Beispielsweise zuerst nach Spalte 2 (numeric-sort) aufsteigend sortiert und dann nach Spalte 1 (reverse) absteigend sortiert.
Diese Sortierung verwendet man dann wenn einzelne Spaltenwerte identisch sind, diese sich aber in den nachfolgenden Spalten verändern. Hier ein Beispiel.
Gegeben ist eine Datei mit folgendem Inhalt:
Pascal 2000 €
Neo 2000 €
Muster 1000 €
Das Ergebnis von 'sort -k2n -k1r Datei.txt' lautet dann Beispielsweise:
Muster 1000 €
Pascal 2000 €
Neo 2000 €
Wie man sieht wurden zuerst die Beträge aufsteigend sortiert (zuerst 1000, dann 2000), danach wurden die Namen bei gleichen Werten in Spalte 2 absteigend sortiert (daher kommt hier Pascal vor Neo).
Als Trennzeichen zwischen den Spalten wird standardmäßig das Leerzeichen verwendet. Mit dem Parameter -t kann man ein anderes Trennzeichen festlegen. Hier mal ein Beispiel.
Gegeben ist eine Datei mit folgenden Datumseinträgen:
21-03-2007 Z
20-03-2007 X
20-03-2006 Y
sort -t- -k3.1,3.4n Datei.txt = Als Spaltentrennzeichen -t wird hier das Minuszeichen '-' festgelegt. '3.1,3.4' bedeutet die Werte in der 3. Spalte werden vom 1. Zeichen bis zum 4. Zeichen sortiert, n = numeric-sort.
Ergebnis:
20-03-2006 Y
20-03-2007 X
21-03-2007 Z
Beachtet dabei, trotz fester Spaltenangabe wurden alle übrigen Spalten auch mit sortiert. Dieses Verhalten kann man durch den Parameter -s (stable) verhindern. Der einfachheitshalber sortieren wir hier nur nach Spalte 3 (-k3n).
sort -s -t- -k3n Datei.txt
Ergebnis:
20-03-2006 Y
21-03-2007 Z
20-03-2007 X
Hier erkennt man, dass durch den Parameter -s nur noch nach der 3. Spalte (der Jahreszahl) sortiert wurde. Die Tage am Anfang und die Buchstaben am Ende wurden nicht mit sortiert (Unterbrechung der Suchfolge).
sort -z ... = (zero-terminated) Die zu sortierenden Einträge werden nicht durch einen Zeilenumbruch, sondern durch ein Nullbyte (0) getrennt. Sinnvoll ist dies z. B. bei der Verarbeitung von Dateinamen, da diese beliebige Steuerzeichen enthalten können.
sort -u Datei.txt = (unique) Doppelt vorhandene Einträge werden nur einmal ausgegeben.
sort -R Datei.txt = (random-sort) Sortiert nicht, sondern vermischt die Reihenfolge zufällig.
sort -c Datei.txt|echo $? = (check) prüft, ob die Datei bereits sortiert ist. Errorlevel 1, bedeutet nicht sortiert. Hinweis: Der Errorlevel passte bei mir meist nicht (bug?). Besser ist es daher die Ausgaben nach 'disorder' zu filtern.
ls -s|sort -n = Alle Dateien im aktuellen Verzeichnis auflisten, die Größe (size) wird dabei an den Anfang gesetzt. Das ganze wird dann noch numerisch sortiert. Sodass die Anzeige der Dateien nach der Größe erfolgt.
ls -laF|sort -k5n = Alle Dateien im aktuellen Verzeichnis der Größe nach auflisten. Die Sortierung erfolgt dabei nach der 5. Spalte also der Größe (Leerzeichen sind Spaltentrenner).
stat (display file system status):
stat Datei_oder_Verzeichnis = Zeigt ausführliche Details zu einer Datei oder zu einem Verzeichnis an.
Neben den normalen Zugriffsrechten wird auch der Zeitstempel der letzten Zugriffszeit, der Zeitstempel letzten Modifizierung und der Zeitstempel der letzten Zugriffsrechteänderung angezeigt.
Hiermit kann man also erkennen wann zuletzt auf eine Datei zugegriffen wurde, bzw. wann diese zuletzt verändert wurde.
Zugriff: gibt an, wann die Datei das letzte Mal gelesen wurde.
Modifiziert: gibt an, wann die Datei das letzte Mal geändert wurde (wenn sich der Inhalt geändert hat).
Geändert: gibt an, wann das letzte Mal die Zugriffsrechte geändert wurden.
Ändern kann man die Zugriffszeiten/Zeitstempel mit touch.
su (superuser):
su verwendet man, wenn man in einer Sitzung/im Terminal zu einer anderen Benutzeridentität (ID) wechseln möchte.
su kann man daher auch verwenden um zum root User zu wechseln ohne vorher sudo einzurichten.
Zum Wechseln der Identität benötigt man das Passwort des Users auf dessen Identität man wechseln möchte, ausgenommen man ist selbst root.
su = Gibt man keinen Benutzernamen an wechselt su standardmäßig zu root. Der aktuelle Pfad wird dabei nicht gewechselt. Es werden auch keine automatischen Startskripte verarbeitet.
su - = Anmelden als Superuser (root), dabei wird die Standardumgebung von root bereitgestellt, dabei wird automatisch in das Home-Verzeichnis [/root]
von root gewechselt und es werden eventuell hinterlegte Startskripte des Users root [/root/.bash_profile] ausgeführt.
su root = Anmelden als Superuser (root), dabei wird der aktuelle Pfad nicht gewechselt. Es werden auch keine automatischen Startskripte verarbeitet.
su Benutzer = Anmelden als User Benutzer. Der aktuelle Pfad wird dabei nicht gewechselt. Es werden auch keine automatischen Startskripte verarbeitet.
su root -c Befehl = Startet nur diesen einen Befehl unter dem Benutzer root.
su Benutzer -c Befehl = Startet den Befehl mit den Berechtigungen des Users Benutzer.
sudo (superuser do):
sudo verwendet man, wenn man Befehle mit Rechten eines Superusers (root) ausführen will.
Des Weiteren ist auch ein dauerhafter Wechsel der Identität möglich.
Will man Aktionen als Superuser (root) ausführen, so benötigt man auch nicht das Kennwort des Superusers - man muss nur in der Gruppe [sudo] Mitglied sein (siehe auch Punkt 3b oben).
sudo Befehl = Startet den angegebenen Befehl mit den Superuser (root) Rechten.
sudo -i = Wechselt die Identität zum Superuser (root), dabei werden eventuell hinterlegte Startskripte des Users root [/root/.bash_profile]
ausgeführt und in der Regel wird automatisch in das Home-Verzeichnis [/root] von root gewechselt.
sudo -s = Wechselt die Identität zum Superuser (root), dabei werden eventuell hinterlegte Startskripte nicht ausgeführt.
Der Pfad in dem man sich befindet bleibt in der Regel gleich. sudo -s wird daher eher empfohlen.
sudo su = Wechselt die Identität zum Superuser (root), dabei werden eventuell hinterlegte Startskripte nicht ausgeführt.
Der Pfad in dem man sich befindet bleibt in der Regel gleich. sudo -s wird daher eher empfohlen.
tail:
tail zeigt immer die letzten Zeilen einer Datei an. Daher ist es gut geeignet Logfiles in einer Console zu überwachen.
tail -f /var/log/logfilename.log = (follow) Änderungen an der Logdatei werden sofort mit angezeigt.
Achtung wenn das Logfile rotiert hält die Anzeige an (die letzten Daten vor dem rotieren bleiben dann immer stehen).
tail -f --retry /var/log/logfilename.log = (follow & retry) Änderungen an der Logdatei werden sofort mit angezeigt,
nach dem Rotieren des Logfiles wird dieses erneut geöffnet. So das dies für eine dauerhafte Überwachung geeignet ist.
tail -F logfile.log = Ist die Kurzform von [-f --retry logfile.log] (ist also leichter einzugeben).
Änderungen vom angegeben Logfile werden ausgegeben und das rotieren des Logfiles wird berücksichtigt.
tar:
Dieser Befehl ermöglicht die Archivierung von Dateien bzw. Verzeichnissen. Das bedeutet, man kann mehrere Dateien und Verzeichnisse zu einer einzigen Datei zusammenfassen. Insbesondere ist hervorzuheben, dass hier die Benutzerrechte mitgesichert werden.
tar -cvJf archiv.tar.xz /pfad/Daten_oder_Ordner/ = Die angegebenen Daten werden im angegebenen tar-Archiv mit xz komprimiert gespeichert.
tar -cvjf archiv.tar.bz2 /pfad/Daten_oder_Ordner/ = Die angegebenen Daten werden im angegebenen tar-Archiv mit bzip2 komprimiert gespeichert.
tar -cvzf archiv.tar.gz /pfad/Daten_oder_Ordner/ = Die angegebenen Daten werden im angegebenen tar-Archiv mit gzip komprimiert gespeichert.
tar -xvJf archiv.tar.xz -C /optionaler_Zielpfad/ = entpackt das xz-tar-Archiv in das ggf. angegebenen Verzeichnis.
tar -xvjf archiv.tar.bz2 = entpackt das bzip2-tar-Archiv.
tar -xvzf archiv.tar.gz = entpackt das gzip-tar-Archiv.
tar -tzf archiv.tar.gz = Archiv Inhalt nur anzeigen (nicht entpacken).
tar --help | more = Zeigt die Hilfe an.
Parametererklärungen:
[-c] = (compress) ein Archiv erstellen.
[-C] = (Change directory) ein anderes Zielverzeichnis angeben.
[-v] = (verbose) ausführlich Anzeige beim packen bzw. entpacken.
[-z] = (zip) die Daten mit gzip packen bzw. entpacken.
[-j] = die Daten mit bzip2 packen bzw. entpacken.
[-J] = die Daten mit xz packen bzw. entpacken.
[-f] = (file) umleiten an eine Datei, bzw. aus einer Datei lesen. Muss immer am Ende der Parameterkette stehen (also direkt vor dem Archivnamen).
[-x] = (expand) das Archiv entpacken.
[-t] = (list) den Inhalt des Archivs ausgeben.
tee:
tee liest von der Standardeingabe. Die gelesenen Daten werden dann direkt an die Standardausgabe und an eine Datei übergeben.
Ausgaben kann man so optisch am Bildschirm verfolgen und zusätzlich in einer Datei protokollieren.
echo 'Hallo Welt' | tee Datei.txt = der Text 'Hallo Welt' wird über echo über die Standardausgabe über die Pipe [|] an tee übergeben.
tee gibt die Daten auf dem Bildschirm aus und speichert den Text 'Hallo Welt' in der 'Datei.txt'.
Eine ggf. bereits bestehende Datei wird überschrieben.
Hallo Welt
cat Datei.txt = zeigt dann den gespeicherten Inhalt nochmals an:
Hallo Welt
echo 'ich bin da!' | tee -a Datei.txt = (append) die Daten der Standardeingabe werden ausgegeben und an eine bereits bestehende Datei angehängt.
ich bin da!
cat Datei.txt = zeigt dann den gespeicherten Inhalt nochmals an. Hier dann Beispielsweise (beachtet dabei den Zeilenumbruch):
Hallo Welt
ich bin da!
Wenn man nicht nur die Standardausgabe sondern auch ggf. auftretende Fehler/Errors mit protokollieren möchte, dann geht man wie folgt vor:
echo 'Ich bin ggf. ein Fehler.' 2>&1 | tee -a Datei.txt = Alle Standardausgaben und ggf. Fehlerausgaben (2>&1) in die angegebene Datei umleiten/anhängen (empfohlene Variante).
Hintergrundinfo: Die Fehlerausgaben werden durch das Hinzufügen von '2>&1' auf die Standardausgabe umgeleitet und dadurch mit protokolliert.
timedatectl (control the system time and date):
Mit timedatectl kann man die System-Uhrzeit sowie die Zeitzonen anzeigen und ändern (ab Ubuntu 16.04).
timedatectl status = Zeigt die derzeitig gesetzten Einstellungen der Lokalen und der Echtzeituhr (RTC = real time clock) an.
Weiterhin wird angezeigt ob die Uhrzeit regelmäßig über den systemd Dienst synchronisiert wird.
timedatectl set-time "2019-05-26 18:00:00" = Setzt die Systemzeit auf das angegebene Datum.
Die Echtzeituhr (real time clock) wird entsprechend ebenso aktualisiert. Die Uhrzeit muss so wie im Beispiel angegeben übergeben werden.
timedatectl list-timezones = Listet alle UTC Zeitzonen auf (UTC = Universal Time Coordinated).
wichtige Varianten:
timedatectl set-timezone Europe/Berlin = Setzt die UTC Zeitzone auf Berlin (+2 Stunden im Sommer, +1 Stunde im Winter).
Dies verhindert die falsche Uhrzeit insbesondere bei Dualboot-Systemen (ggf. Neustart erforderlich).
timedatectl set-ntp 0 = (false) Datum-/Zeitsynchronisation ausschalten z. B. sinnvoll bei virtuellen Testsystemen (disable date/time sync on VirtualBox Ubuntu/Debian).
timedatectl set-ntp 1 = (true) Die Zeitsynchronisation wieder einschalten.
top:
Zeigt verschiedenste CPU-Prozesse an.
top -s = Im sicheren Modus starten, alle potentiell gefährlichen interaktiven Kommandos werden ignoriert. Besonders für Überwachungsterminals geeignet.
top -i = (inaktive) untätige Prozesse werden ausgeblendet.
top -c = Statt dem Namen wird der komplette Kommandozeilenaufruf dargestellt.
Einige wichtige Tastaturkommandos wenn top läuft:
c = (command) Wechselt zwischen der Darstellung von Kommandonamen und vollen Kommandozeilen.
h = Hilfe anzeigen.
i = (inaktive) untätige Prozesse werden ausgeblendet.
k = (kill) Es wird nach dem zu killenden Prozess gefragt (geht nicht im sicheren Modus).
l = Die Anzeige der Durchschnittsauslastung und uptime an- oder ausschalten.
m = (memory) Speicherverbrauch ein-/ausblenden.
q = (quit) Beendet das Programm.
t = (tasks) Taskübersicht ein-/ausblenden.
N = Sortiert die Tasks nach PID.
P = Sortiert die Tasks nach CPU-Benutzung (Voreingestellt).
M = (memory) Sortiert die Tasks nach Speichernutzung.
T = (tasks) Sortiert die Tasks nach Zeit/kumulativer Zeit.
Leertaste = sofort alles aktualisieren.
Eine empfehlenswerte Alternative ist htop [apt-get install htop].
touch (change file timestamps):
touch Datei_oder_Verzeichnis
Mit touch kann man Zugriffs- und Änderungszeiten von Dateien und Verzeichnissen ändern.
touch -t 1912311200 Datei_oder_Verzeichnis = Ändert das Zugriffs und Änderungsdatum (Inhaltsmodifizierung) auf den 31.12.2019, 12:00 Uhr.
Falls die Datei nicht existiert wird eine neue leere Datei angelegt.
Anzeigen lassen sich die Zeitstempel mittels stat.
tune2fs:
tune2fs Festlegen der automatischen Dateisystemüberprüfung.
tune2fs -c 15 /dev/sda1 = festlegen nach wie vielen Systemstarts die Festplatte automatisch auf Fehler geprüft wird.
tune2fs -U random /dev/sdb1 = einen neuen UUID (Universally Unique Identifier) Code setzen (ggf. nötig nach Festplattencloning).
tune2fs -l /dev/sda1 = (list) zeigt verschiedene Datenträgerparameter an, unter anderem die Reserve-Blöcke (einfacher SSD/HD Test).
uname:
uname zeigt verschiedene Hardwareinformationen an.
Ausgaben sind Systembedingt und können je nach Hardware und Betriebssystem zum Teil sehr verschieden sein.
uname -a = (all) Zeigt alle Informationen an.
uname -r = (release) Nur die genaue Versionsnummer vom Kernel Release ausgeben.
uname -m = (machine typ) Gibt verwendete Architektur aus: 32-Bit oder 64-Bit? Man kann hier auch den Befehl [arch] verwenden.
Hierbei bedeutet eine Ausgabe von:
[x86_64] = es wird ein 64-Bit Kernel verwendet.
[i686] = es wird nur ein 32-Bit Kernel verwendet, auch wenn die CPU ggf. 64-Bit fähig ist. Es ist also nur eine 32-Bit Version installiert.
xset:
xset dient unter anderem zur Anpassung von Bildschirmeinstellungen (auch für X-Server/grafische Desktop-Umgebungen).
xset s off -dpms = Schaltet den Bildschirm-Energiesparmodus und den Bildschirmschoner aus.
Beachtet: Das funktioniert auch bei Live-Systemen wenn man z. B. von einer DVD/einem USB-Stick bootet.
Dies verhindert also das automatische abschalten des Bildschirms nach einer Leerlaufzeit.
Länger laufende Programme oder Dateioperationen (auf die man wartet) kann man dann so besser verfolgen ohne das man ständig an der Maus wackeln muss.
Auch schaltet man dann nicht so schnell einen laufenden PC aus, da man nun einfach direkt erkennt das der PC noch an ist.
Die Einstellungen sind nach einem Neustart verloren (daher ggf. im Autostart eintragen).
nano ~/.bash_profile
Parametererklärung einzeln:
xset q = Die aktuellen Einstellungen anzeigen.
xset -dpms = Stromsparmöglichkeiten des Monitors (Energy Star) ausschalten (wenn DPMS unterstützt wird).
xset +dpms = Stromsparmöglichkeiten des Monitors (Energy Star) wieder aktivieren (wenn DPMS unterstützt wird).
xset +dpms 600 1200 1800 = Stromsparmöglichkeit DPMS aktivieren, Standby nach 10 Minute, Suspend nach 20 Minuten, Off (abschalten) nach 30 Minuten (die Angaben erfolgen in Sekunden).
xset s off = Den Bildschirmschoner deaktivieren.
xset s on = Den Bildschirmschoner wieder aktivieren.
!. Abschließende Hinweise:
IP-Adressen, E-Mailadressen, Namen u. ä. wurden für die Dokumentation geändert, hacken ist also zwecklos.
Die Nutzung der Anleitung erfolgt auf eigene Gefahr, für jegliche Schäden wird keine Garantie/Haftung übernommen!
Die Dokumentation entstand aus verschiedenen Tests, sowie produktiven Installationen und stellt eine Zusammenfassung wichtiger und empfohlener Schritte dar.
Bevor sie eventuell Fragen stellen bitte ich sie die Dokumentation komplett zu lesen.
Hinweise auf Fehler, Anregungen, Danksagungen oder ähnliches sind immer willkommen.
Die Bildschirm-Screenshots sind in Originalgröße, diese werden aber verkleinert dargestellt.
Die Anzeige kann man z. B. mit der Tastatur über Strg und + vergrößern und über Strg und - wieder verkleinern,
Strg + 0 stellt die Originalgröße wieder her.
Design:
© ctaas.de, Arno Schröder, Kahla, Impressum
